仓储管理系统应用开发套件
 社区干货
社区干货
DataLeap数据仓库流程最佳实践
# 前言本实验以DataLeap on LAS为例,实际操作火山引擎数据产品,完成数据仓库的构建。# 关于实验* 预计部署时间:50分钟* 级别:初级* 相关产品:大数据开发套件、湖仓一体分析服务LAS* 受众: 通用## 环境说... 应用数据层。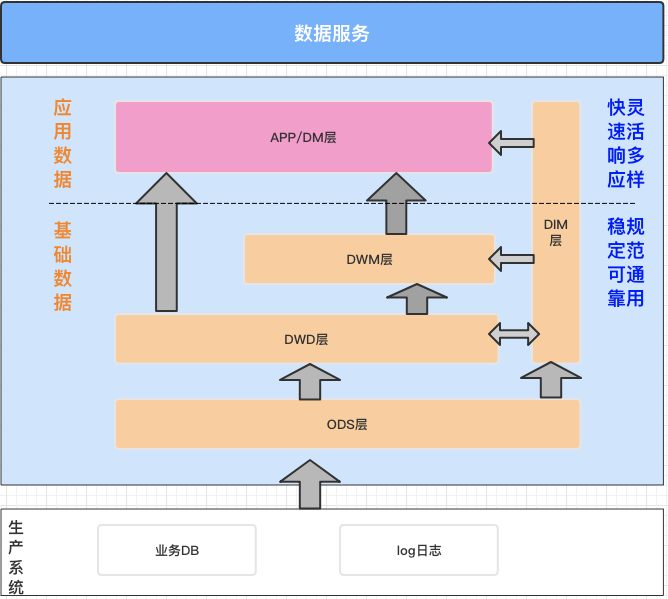本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始...
【云原生 | 最佳实践】一个实践驱动的云原生项目集—KubeWharf | 社区征文
KubeWharf 是字节跳动基础架构团队在对 Kubernetes 进行了大规模应用和不断优化增强之后的技术结晶。这是一套以 Kubernetes 为基础构建的分布式操作系统,由一组云原生组件构成,专注于提高系统的可扩展性、功能性、... 他们介绍了字节跳动开源的细粒度资源管理与调度系统 **[Katalyst](https://github.com/kubewharf/katalyst-core)**。**[在Kubernetes上构建一个精细化和智能化的资源管理系统 | Building a Fine-Grained and Int...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.07
数据开发支持 EMR 引擎任务类型、通用任务、流式计算 Flink 版任务类型 - 数据集成新增支持离线集成、流式集成任务 - 数据安全支持权限管理、风险审计、审批中心 - 数据质量支持 EMR 引擎的数据监控、数据探查、数据对比等能力 - 数据地图支持数据检索、专题、血缘、元数据采集支持 EMR Hive/Doris/StarRocks - 数据服务支持创建数据集、QUERY,并支持 API 监控运维、应用管理、系统管理等...
观点|SparkSQL在企业级数仓建设的优势
> > > 企业级数仓架构设计与选型的时候需要从开发的便利性、生态、解耦程度、性能、 安全这几个纬度思考。本系列分两次连载, **第一部分(本文)分享我们在企业级数仓建设上的技术选型观点** ,第二个部分则重点介... 数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式...
 特惠活动
特惠活动
 仓储管理系统应用开发套件-优选内容
仓储管理系统应用开发套件-优选内容
 仓储管理系统应用开发套件-相关内容
仓储管理系统应用开发套件-相关内容
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.07
数据开发支持 EMR 引擎任务类型、通用任务、流式计算 Flink 版任务类型 - 数据集成新增支持离线集成、流式集成任务 - 数据安全支持权限管理、风险审计、审批中心 - 数据质量支持 EMR 引擎的数据监控、数据探查、数据对比等能力 - 数据地图支持数据检索、专题、血缘、元数据采集支持 EMR Hive/Doris/StarRocks - 数据服务支持创建数据集、QUERY,并支持 API 监控运维、应用管理、系统管理等...
观点|SparkSQL在企业级数仓建设的优势
> > > 企业级数仓架构设计与选型的时候需要从开发的便利性、生态、解耦程度、性能、 安全这几个纬度思考。本系列分两次连载, **第一部分(本文)分享我们在企业级数仓建设上的技术选型观点** ,第二个部分则重点介... 数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式...
SparkSQL 在企业级数仓建设的优势
> 企业级数仓架构设计与选型的时候需要从开发的便利性、生态、解耦程度、性能、 安全这几个纬度思考。本系列分两次连载,**第一部分(本文)分享我们在企业级数仓建设上的技术选型观点**,第二个部分则重点介绍了字节跳... 目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive...
「火山引擎数据中台产品双月刊」 VOL.07
数据开发支持 EMR 引擎任务类型、通用任务、流式计算 Flink 版任务类型 - 数据集成新增支持离线集成、流式集成任务 - 数据安全支持权限管理、风险审计、审批中心 - 数据质量支持 EMR 引擎的数据监控、数据探查、数据对比等能力 - 数据地图支持数据检索、专题、血缘、元数据采集支持 EMR Hive/Doris/StarRocks - 数据服务支持创建数据集、QUERY,并支持 API 监控运维、应用管理、系统管理等...
Android SDK 集成
1. 集成增长营销套件 SDK 1.1 引入仓库Gradle 7.0 以下Groovy // 在 project 级别的 build.gradle 中添加 maven 仓库// 在 allprojects 的 repositories 中添加 maven 仓库allprojects { repositories { ... DevTools是 Debug 环境下辅助开发者或测试人员进行应用内埋点验证和 SDK 接入问题排查的组件。在 app module 级别的 build.gradle 文件中,在 dependencies 里引入DevTools。详细接入文档请查阅:Android埋点开发工具...
新功能发布记录
开发、训练、推理业务的服务套件。以 VKE 容器集群作为底座,针对 AI 业务基础设施的特性,提供一系列资源监控运维、性能加速、工作负载编排调度能力。 华北 2 (北京) 2024-04-16 云原生 AI 套件 华南 1 (广州) 2024-04-08 华东 2 (上海) 2024-04-15 云原生批量计算套件开放公测 云原生批量计算套件为用户提供异构资源混合调度能力,多队列管理能力、队列资源共享调度能力等,可支持海量作业和并发规模的作业有序调度运行,广泛应用于...
火山引擎数据中台发布新品:湖仓一体分析服务、E-MapReduce 服务
系统和应用正逐步面向公有云进行构建或迁移,云上大数据分析能力正成为业务数字化、智能化的关键支撑。传统自建数据仓库,在企业数据体量持续增长、业务时效持续提升的情况下,已经很难应对更复杂、更多样化的分析场景需求,平台扩展和数据融合面临重重障碍。另外一方面,尽管Hadoop已成为企业大数据平台建设的主流技术框架,但企业在逐步建设大数据平台过程中也会面临这样的难题——基于开源Hadoop无法有效支撑商用部署和高效开发,建...
字节跳动基于数据湖技术的近实时场景实践
更灵活的应用。2. ## **字节**数据湖Apache Hudi有下面非常重要的特性:- Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/d... 血缘管理、开发套件等方面,实时计算、离线计算客观上存在着较大差异。 因此,我们采取的策略是设计一种近实时的计算架构,在保留离线计算数据的丰富度和复杂度的同时,又兼顾实时计算的时效性高的特点,将两者进...
应用场景
聚合APP和日志数据分析客户行为支持精准营销,辅助分析决策。但自建开源大数据平台时,往往面临管理维护人力投入大,资源成本高且不灵活等问题。 火山引擎EMR提供丰富的主流开源大数据组件,100%开源兼容,支持平滑迁移和长期演进。提供企业级组件优化和管控能力,帮助企业开发运维降本增效。一个架构支撑完整能力的数据湖仓方案,支持EB级别的数据仓库、湖内建仓、湖仓一体等。配合火山引擎大数据研发治理套件DataLeap和全域数据集成Da...
