机器学习数据集
 社区干货
社区干货
浅谈AI机器学习及实践总结 | 社区征文
# 机器学习基础## 什么是机器学习机器学习是一种从数据生成规则、发现模型,来帮助我们预测、判断、分组和解决问题的技术。(机器学习是一种从数据中生产函数,而不是程序员直接编写函数的技术)说起函数就涉及到自变量和因变量,在机器学习中,把自变量叫做特征(feature)多个自变量分别可以定义为X1,X2..Xn,因变量叫做标签(label),可定义为Y,而一批特征和标签的集合,就是机器学习的数据集。机器学习的学习过程就是在已知的数据...
如何构建过拟合和防过拟合模型
当机器学习模型过分关注训练数据中的噪声和其他异常因素,而忽略了其他重要特征时,该模型可能会发生“过拟合”。如果模型太简单,而忽略了许多重要特征,则可能会发生“欠拟合”。因此,要构建准确的机器学习模型,用户需要有一种策略来确保模型不会过拟合或欠拟合,以确保预测的准确性。下面,我们将讨论如何构建过拟合和防止过拟合的模型。首先,要构建准确的机器学习模型,用户必须可以收集到准确、有效和足够庞大的训练数据集。该数...
火山引擎大规模机器学习平台架构设计与应用实践
>作者:火山引擎AML团队## 模型训练痛点关于模型训练的痛点,首先是技术上的。现在机器学习应用非常广泛,下表给出了几种典型的应用,包括自动驾驶、蛋白质结构预测、推荐广告系统、NLP 等。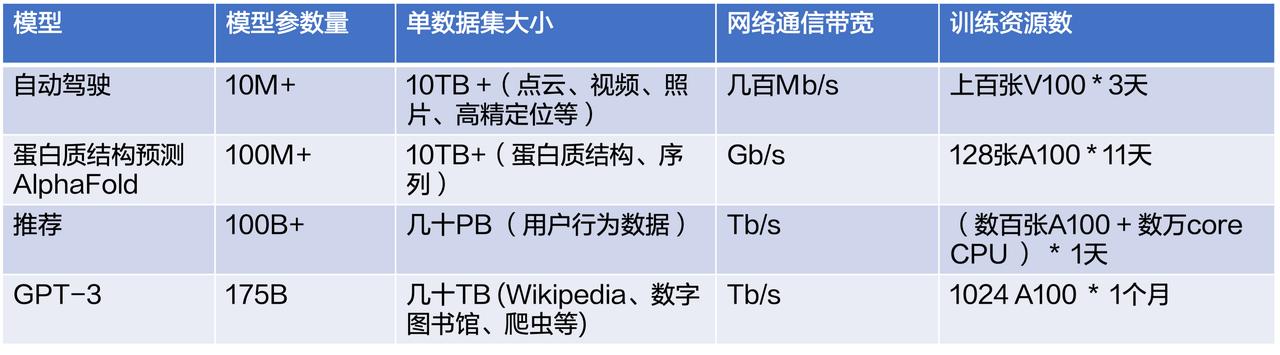可以看到不同应用场景下的参数和数据集、模型训练过程中的网络通信带宽、训练资源数和时长都不尽相同...
AI 和机器学习:探索智能科技的未来 | 社区征文
# AI和机器学习的定义人工智能(Artificial Intelligence)是使计算机和机器模拟人类智能的科学与工程实践。它旨在构建智能代理——系统能够正确理解外部环境,并在那里采取行动,以最大程度地完成目标。AI技术的目标之一是通过创建具有人类智能特征的系统来解决复杂问题。而机器学习(Machine Learning)是AI的一个分支。它通过分析数据来教会计算机学习而不通过明确编程。通过例如聚类、分类和回归等算法从示例数据中学习模式和规则...
 特惠活动
特惠活动
 机器学习数据集-优选内容
机器学习数据集-优选内容
 机器学习数据集-相关内容
机器学习数据集-相关内容
模型精调数据集格式说明
当前模型精调数据集支持jsonl格式,以下为详细格式说明: 注:仅Pretrain模型(预训练模型)支持上传未标注文本数据进行Continue Pretraining(继续预训练);非Pretrain模型请使用已标注文本数据。 已标注文本数据 JSONL格... 未标注文本数据 JSONL格式说明: {"text":"火山引擎机器学习平台是面向机器学习应用开发者,提供【开发机】和【自定义训练】等丰富建模工具、多框架高性能模型推理服务的企业级开发平台,支持从数据托管、代码开发、模...
AI 和机器学习:探索智能科技的未来 | 社区征文
# AI和机器学习的定义人工智能(Artificial Intelligence)是使计算机和机器模拟人类智能的科学与工程实践。它旨在构建智能代理——系统能够正确理解外部环境,并在那里采取行动,以最大程度地完成目标。AI技术的目标之一是通过创建具有人类智能特征的系统来解决复杂问题。而机器学习(Machine Learning)是AI的一个分支。它通过分析数据来教会计算机学习而不通过明确编程。通过例如聚类、分类和回归等算法从示例数据中学习模式和规则...
火山引擎大规模机器学习平台架构设计与应用实践
现在机器学习应用非常广泛,下表给出了几种典型的应用,包括自动驾驶、蛋白质结构预测、推荐广告系统、NLP 等。可以看到不同应用场景下的参数和数据集、模型训练过程中的网络通信带...
技术人的 2023 总结:人工智能-基于机器学习的环境污染影响评估学习|社区征文
而基于机器学习的方法能够利用大量的数据,从而更全面、精确地评估环境污染的影响。## 数据收集:环境数据的收集是评估环境污染影响的关键步骤。通过传感器、卫星遥感、气象站等设备获...
我的技术年终总结——机器学习 |社区征文
**建立模型**:设计计算机可以自动“学习”的算法- **训练**:用数据训练算法模型(算法从数据中分析规律)- **预测**:利用训练后的算法完成任务(根据学习的规律为未知数据进行分类和预测) 通过周志华老师西瓜书上面的描述为下图: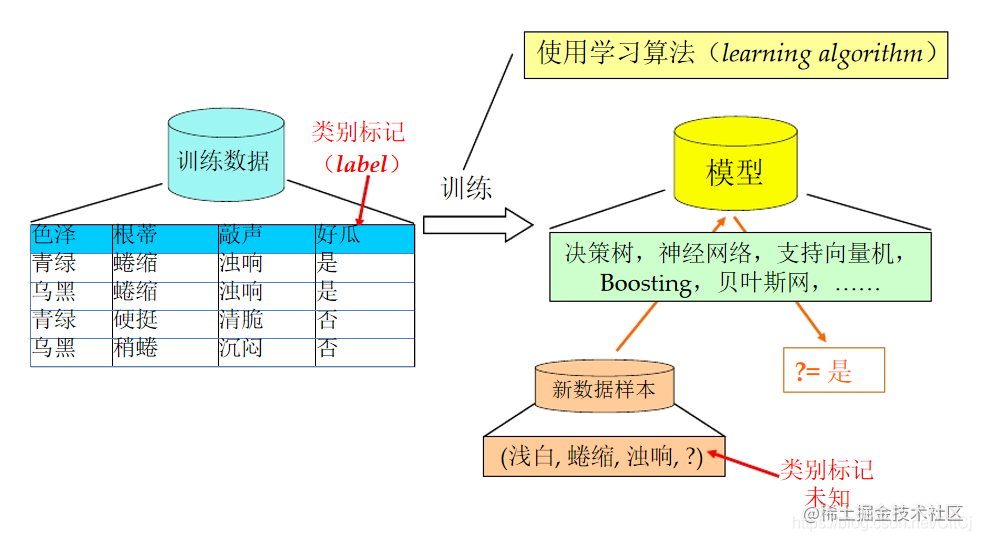## 二、机器学习能做什么? ### 数据集上 ...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
> 深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持 EB 级机器学习样本存储,实现高性能特征读取和高效特征调研、特征工程加速模型迭代。**相关产品**:https://www.volcengine.com/product/flink # 机...
在线学习FTRL介绍及基于Flink实现在线学习流程|社区征文
# 背景目前互联网已经进入了AI驱动业务发展的阶段,传统的机器学习开发流程基本是以下步骤:数据收集->特征工程->训练模型->评估模型效果->保存模型,并在线上使用训练的有效模型进行预测。这种方式主要存在两个瓶颈:模型更新周期慢,不能有效反映线上的变化,最快小时级别,一般是天级别甚至周级别。另外一个是模型参数少,预测的效果差;模型参数多线上predict的时候需要内存大,QPS无法保证。针对这些问题,一般而言有两种解决方...
机器学习
1. 概述 机器学习,是指可视化建模支持机器学习算子,对数据进行加工处理,以便用户基于数据进行模型训练、深度分析、预测分析等。本文将为您介绍机器学习算子的功能。 2. 功能介绍 2.1 预测将机器学习算子训练生成的模型应用于预测数据的数据上,一般链接在机器学习算子后面。字段设置特征列映射:设置模型中的特征列和数据中的特征列的映射关系。标签列:标签列,分类训练的依据。参数设置预测的列名:预测的列的名字。 2.2 one-hot 模...
机器学习
1.功能概述 机器学习,是指可视化建模支持机器学习算子,对数据进行加工处理,以便用户基于数据进行模型训练、深度分析、预测分析等。本文将为您介绍机器学习算子的功能。 2.算子介绍 2.1 预测将机器学习算子训练生成的模型应用于预测数据的数据上,一般链接在机器学习算子后面。 说明 字段设置 特征列映射:设置模型中的特征列和数据中的特征列的映射关系。 标签列: 标签列,分类训练的依据。 参数设置 预测的列名:预测的列的名字。 ...
