一个将相等数量的某个值排序为真或假的函数。
 社区干货
社区干货
golang pprof
执行`top`命令可以可以看到占用量逆序排列的函数,如下。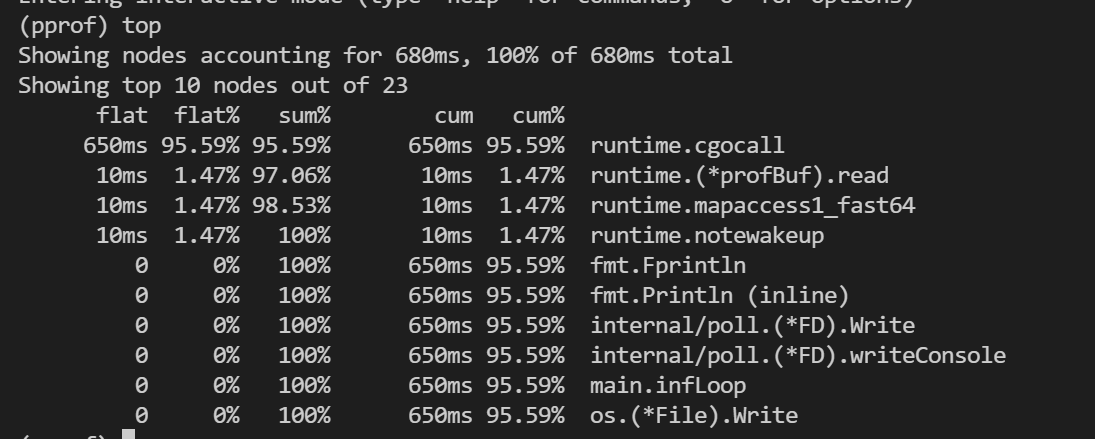可以看到总共有6列信息,这六... 与top相同 || top | 以文本格式输出占用量前n的函数 || topproto | 以protobuf格式输出top的每个...
万字长文带你漫游数据结构世界|社区征文
数据结构是指相互之间存在一种或多种特定关系的[数据元素](https://baike.baidu.com/item/数据元素/715313)的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储[效率](https://baike.baidu.com/item... 排序后的链表,还是只能知道头尾节点,知道中间的范围,但是要找到中间的节点,还是得走遍历的老路。如果我们把中间节点存储起来呢?存起来,确实我们就知道数据在前一半,还是在后一半。比如找`7`,肯定就从中间节点开始找...
干货|Hudi Bucket Index 在字节跳动的设计与实践
如果需要对一个分区数据做更新,整个更新过程会涉及三个很重的操作。举一个更直观的例子。假设一个 Hive 分区存在 100,000 条记录,分布在 400 个文件中,我们需要更新其中的 100 条数据。这三个很重的操作分别是:1... 供运营或分析师自助进行近实时数据分析。**随着入湖的数据量增加,Hudi 中生成了约 40,000 个 File Group。虽然该业务部门使用了 Hudi 索引避免了全局合并操作,但是随着 File Group 的数量以及存储的数据量增加,定...
Hudi Bucket Index 在字节跳动的设计与实践
如果需要对一个分区数据做更新,整个更新过程会涉及三个很重的操作。举一个更直观的例子。假设一个 Hive 分区存在 100,000 条记录,分布在 400 个文件中,我们需要更新其中的 100 条数据。这三个很重的操作分别是: ... 随着入湖的数据量增加,Hudi 中生成了约 40,000 个 File Group。虽然该业务部门使用了 Hudi 索引避免了全局合并操作,但是随着 File Group 的数量以及存储的数据量增加,定位 File Group 的时间也在增加,这造成了 Ups...
 特惠活动
特惠活动
 一个将相等数量的某个值排序为真或假的函数。-优选内容
一个将相等数量的某个值排序为真或假的函数。-优选内容
 一个将相等数量的某个值排序为真或假的函数。-相关内容
一个将相等数量的某个值排序为真或假的函数。-相关内容
干货|Hudi Bucket Index 在字节跳动的设计与实践
如果需要对一个分区数据做更新,整个更新过程会涉及三个很重的操作。举一个更直观的例子。假设一个 Hive 分区存在 100,000 条记录,分布在 400 个文件中,我们需要更新其中的 100 条数据。这三个很重的操作分别是:1... 供运营或分析师自助进行近实时数据分析。**随着入湖的数据量增加,Hudi 中生成了约 40,000 个 File Group。虽然该业务部门使用了 Hudi 索引避免了全局合并操作,但是随着 File Group 的数量以及存储的数据量增加,定...
Hudi Bucket Index 在字节跳动的设计与实践
如果需要对一个分区数据做更新,整个更新过程会涉及三个很重的操作。举一个更直观的例子。假设一个 Hive 分区存在 100,000 条记录,分布在 400 个文件中,我们需要更新其中的 100 条数据。这三个很重的操作分别是: ... 随着入湖的数据量增加,Hudi 中生成了约 40,000 个 File Group。虽然该业务部门使用了 Hudi 索引避免了全局合并操作,但是随着 File Group 的数量以及存储的数据量增加,定位 File Group 的时间也在增加,这造成了 Ups...
干货|Hudi Bucket Index 在字节跳动的设计与实践
如果需要对一个分区数据做更新,整个更新过程会涉及三个很重的操作。举一个更直观的例子。假设一个 Hive 分区存在 100,000 条记录,分布在 400 个文件中,我们需要更新其中的 100 条数据。这三个很重的操作分别是: ... 随着入湖的数据量增加,Hudi 中生成了约 40,000 个 File Group。虽然该业务部门使用了 Hudi 索引避免了全局合并操作,但是随着 File Group 的数量以及存储的数据量增加,定位 File Group 的时间也在增加,这造成了 Ups...
干货|Hudi Bucket Index 在字节跳动的设计与实践
如果需要对一个分区数据做更新,整个更新过程会涉及三个很重的操作。举一个更直观的例子。假设一个 Hive 分区存在 100,000 条记录,分布在 400 个文件中,我们需要更新其中的 100 条数据。这三个很重的操作分别是: ... 供运营或分析师自助进行近实时数据分析。**随着入湖的数据量增加,Hudi 中生成了约 40,000 个 File Group。虽然该业务部门使用了 Hudi 索引避免了全局合并操作,但是随着 File Group 的数量以及存储的数据量增...
数组函数
使用函数的参数作为数组元素创建一个数组。 参数必须是常量,并且具有最小公共类型的类型。必须至少传递一个参数,否则将不清楚要创建哪种类型的数组。也就是说,你不能使用这个函数来创建一个空数组(为此,使用上面描述的’emptyArray *’函数)。 返回’Array(T)’类型的结果,其中’T’是传递的参数中最小的公共类型。 arrayConcat合并参数中传递的所有数组。 plaintext arrayConcat(arrays)参数 arrays – 任意数量的阵列类型的参数...
Hudi Bucket Index 在字节跳动的设计与实践
如果需要对一个分区数据做更新,整个更新过程会涉及三个很重的操作。举一个更直观的例子。假设一个 Hive 分区存在 100,000 条记录,分布在 400 个文件中,我们需要更新其中的 100 条数据。这三个很重的操作分别是:1... 供运营或分析师自助进行近实时数据分析。**随着入湖的数据量增加,Hudi 中生成了约 40,000 个 File Group。虽然该业务部门使用了 Hudi 索引避免了全局合并操作,但是随着 File Group 的数量以及存储的数据量增加...
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。(2)一个计算每个分区的函数。Spark中... 一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,...
系统集成在一些特定行业的相关概念
主要为企业的特定应用服务,强调处理的响应时间、数据的安全性和完整性等;分析型处理则用于管理人员的决策分析,经常要访问大量的历史数据。数据仓库(DataWarehouse)是一个面向主题的、集成的、相对稳定的、反映... 不同的应用可能会同时访问相同的数据导致数据访问冲突,因此也会带来如死锁等问题。所以说,共享数据库方案出现问题的根源在于用一种统一的数据模型来解决各种不同的应用需求是并不现实的。(3)RPC(远程过程调用)...
一口气看完43个关于 ElasticSearch 的使用建议
缓存内容为单个分片的查询结果。**主要作用是对聚合的缓存**,查询结果中被缓存的内容主要包括:Aggregations(聚合结果)、Hits.total、以及 Suggestions等。并非所有的分片级查询都会被缓存。只有客户端查询请求中... 类似的还有在脚本查询中使用了 Math.random() 等函数的查询也不会进行缓存。当有新的 Segment 写入到分片后,缓存会失效,因为之前的缓存结果已经无法代表整个分片的查询结果。所以分片每次**Refresh**之后,缓存会...
