将深度嵌套字典中的重复键进行展平/归一化
 社区干货
社区干货
浅谈分布式操作系统 KubeWharf 的第二批开源项目|社区征文
寓意该系统能够为所有运行在 Kubernetes 体系中的负载提供更加强劲的自动化资源管理能力。 项目地址 | [github.com/kubewharf/katalyst-core](https://xie.infoq.cn/article/ce4a725bfbf0a65680ffa9173) ... 具体来说我们将 QoS 分为四类:独占型、共享型、回收型和为系统关键组件预留的系统型; **微观上**,Katalyst 最终期望状态无论什么样的 workload,都能实现在相同节点上的并池运行,不需要通过硬切集群来隔离,实...
初探金融风控中的信用评分卡搭建全流程 | 社区征文
在个人信贷中,信用风险评估的关键是,通过分析借款人的信用信息,评估借款人的偿还能力和意愿量化违约风险。因此,个人借贷平台的信用风险管理依赖于其收集和分析借款人信用信息的能力。一般借款人的信息来自线下调查和网络信息两个渠道,线下调查在地理维度上是有限的,并且会增加贷款人的搜索成本。利用信息技术补充甚至替代线下调查已成为个人借贷业务建设的一种趋势。信用评分卡模式是个人信贷风险管理中的重要手段,是一种结合专...
ICME VQA Grand Challenge 获奖工作分享
我们使用 CNN 作为特征提取器来计算输入视频块的深度特征。提取 ResNet 不同层的特征,在空间维度上利用 MaxPooling 将这些特征降采样到相同大小,并在特征维度上进行拼接。将该特征的空间维度展平并进行 Linear p... 其值归一化至[-1,1],PLCC 值越大性能越好,因此 PLCC 损失表示为: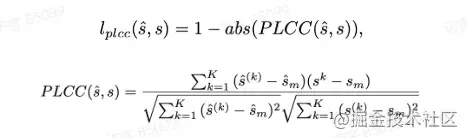全参考模型框架如图...
字节跳动开源 Kelemetry:面向 Kubernetes 控制面的全局追踪系统
我们会将 spec.replicas 字段更新为 5,rs controller 会观察到此更改,并不断创建新的 pod 对象,直到总数达到 5 个。当 kubelet 观察到其管理的节点创建了一个 pod 时,它会在其节点上生成与 pod 中的规范匹配的容器... Kelemetry 使用 Kubernetes 中的对象列表观察 API 检索事件,而该 API 仅公开 event 对象的最新版本。为了避免重复事件,Kelemetry 使用了几种启发式方法来“猜测”是否应将 event 报告为一个跨度:* 持久化处理的最...
 特惠活动
特惠活动
 将深度嵌套字典中的重复键进行展平/归一化-优选内容
将深度嵌套字典中的重复键进行展平/归一化-优选内容
 将深度嵌套字典中的重复键进行展平/归一化-相关内容
将深度嵌套字典中的重复键进行展平/归一化-相关内容
SearchByVector
否 过滤字段,指定要返回的标量或向量字段列表。 outputFields 不传时,返回所有的标量字段,不返回向量字段。 outputFields 为空列表时,不返回 fields 字段。 outputFields 格式错误或者过滤字段不是 collection 里的字段时, 接口返回错误。 如果索引的距离方式为cosine,向量字段返回的向量是归一化后的向量。 partition string/int 否 "default" 子索引名称,类型与 partitionBy 的 FieldType 一致,字段值对应 partitionBy...
search_by_id
dense_weight 用于控制稠密向量在检索中的权重。范围为[0.2,1]。仅在检索的索引为混合索引时有效。 output_fields list 否 过滤字段,指定要返回的标量或向量字段列表。 output_fields 不传时,返回所有的标量字... output_fields 格式错误或者过滤字段不是 collection 里的字段时, 接口返回错误。 如果索引的距离方式为cosine,向量字段返回的向量是归一化后的向量。 partition string/int 否 "default" 子索引名称,类型与...
字节跳动开源 Kelemetry:面向 Kubernetes 控制面的全局追踪系统
我们会将 spec.replicas 字段更新为 5,rs controller 会观察到此更改,并不断创建新的 pod 对象,直到总数达到 5 个。当 kubelet 观察到其管理的节点创建了一个 pod 时,它会在其节点上生成与 pod 中的规范匹配的容器... Kelemetry 使用 Kubernetes 中的对象列表观察 API 检索事件,而该 API 仅公开 event 对象的最新版本。为了避免重复事件,Kelemetry 使用了几种启发式方法来“猜测”是否应将 event 报告为一个跨度:* 持久化处理的最...
searchByText
向量数据库通过测量文本之间的距离来确定两段文本的相似程度,返回文本的相似度。该功能适用于重复识别、文本搜索与匹配、问答等场景。 说明 当前仅支持文本类型的非结构化数据。 Collection 数据写入/删除后,Index... outputFields 格式错误或者过滤字段不是 collection 里的字段时, 接口返回错误。 如果索引的距离方式为cosine,向量字段返回的向量是归一化后的向量。 partition string/int 否 "default" 子索引名称,类型与 ...
searchByText
向量数据库通过测量文本之间的距离来确定两段文本的相似程度,返回文本的相似度。该功能适用于重复识别、文本搜索与匹配、问答等场景。 说明 当前仅支持文本类型的非结构化数据。 Collection 数据写入/删除后,Index... outputFields 格式错误或者过滤字段不是 collection 里的字段时, 接口返回错误。 如果索引的距离方式为cosine,向量字段返回的向量是归一化后的向量。 partition string/int 否 "default" 子索引名称,类型与 ...
SearchByText
向量数据库通过测量文本之间的距离来确定两段文本的相似程度,返回文本的相似度。该功能适用于重复识别、文本搜索与匹配、问答等场景。 说明 当前仅支持文本类型的非结构化数据。 Collection 数据写入/删除后,Index... outputFields 格式错误或者过滤字段不是 collection 里的字段时, 接口返回错误。 如果索引的距离方式为cosine,向量字段返回的向量是归一化后的向量。 partition string/int 否 "default" 子索引名称,类型与 ...
SearchByText
向量数据库通过测量文本之间的距离来确定两段文本的相似程度,返回文本的相似度。该功能适用于重复识别、文本搜索与匹配、问答等场景。 说明 当前仅支持文本类型的非结构化数据。 Collection 数据写入/删除后,Index... outputFields 格式错误或者过滤字段不是 collection 里的字段时, 接口返回错误。 如果索引的距离方式为cosine,向量字段返回的向量是归一化后的向量。 partition string/int 否 "default" 子索引名称,类型与 ...
search_by_vector
格式是字典,k 为 string 类型,表示关键词的字面量,v 为 float 类型,表示该关键词的权重数值。 dense_weight float 否 0.5 对于混合检索,dense_weight 用于控制稠密向量在检索中的权重。范围为[0.2,1]。仅在检... output_fields 格式错误或者过滤字段不是 collection 里的字段时, 接口返回错误。 如果索引的距离方式为cosine,向量字段返回的向量是归一化后的向量。。 partition string/int 否 "default" 子索引名称,类型...
searchByVector
dense_weight 用于控制稠密向量在检索中的权重。范围为[0.2,1]。仅在检索的索引为混合索引时有效。 outputFields list 否 过滤字段,指定要返回的标量或向量字段列表。 outputFields 不传时,返回所有的标量字段... outputFields 格式错误或者过滤字段不是 collection 里的字段时, 接口返回错误。 如果索引的距离方式为cosine,向量字段返回的向量是归一化后的向量。 partition string/int 否 "default" 子索引名称,类型与 ...
