Flink高内存使用
 社区干货
社区干货
关于大数据计算框架 Flink 内存管理的原理与实现总结 | 社区征文
因为flink计算会面临大量数据处理、大量状态存储,完全基于jvm的堆内存管理存在较大的缺陷,flink基于jvm实现了独立的内存管理:可超出主内存的大小限制、承受更少的垃圾回收开销、对象序列化二进制存储,下面在来详细介绍下flink内存管理。## 完全JVM内存管理存在的问题基于JVM的数据分析引擎都需要面对将大量数据存到内存当中,就不得不面对JVM存在的几个问题:- java对象存储密度低:比如一个只包含boolean属性的对象占用16个...
打造通用缓存层:字节跳动 Flink StateBackend 性能提升之路
目前 Flink 提供的生产可用的 Statebackend 主要有两类,一类是 FsStateBackend,另一类是 RocksDBStateBackend。他们的**基本原理都是提供一个 State** **API** **给用户使用,底层会根据 StateBackend 类型选用不同的存储来存储数据。**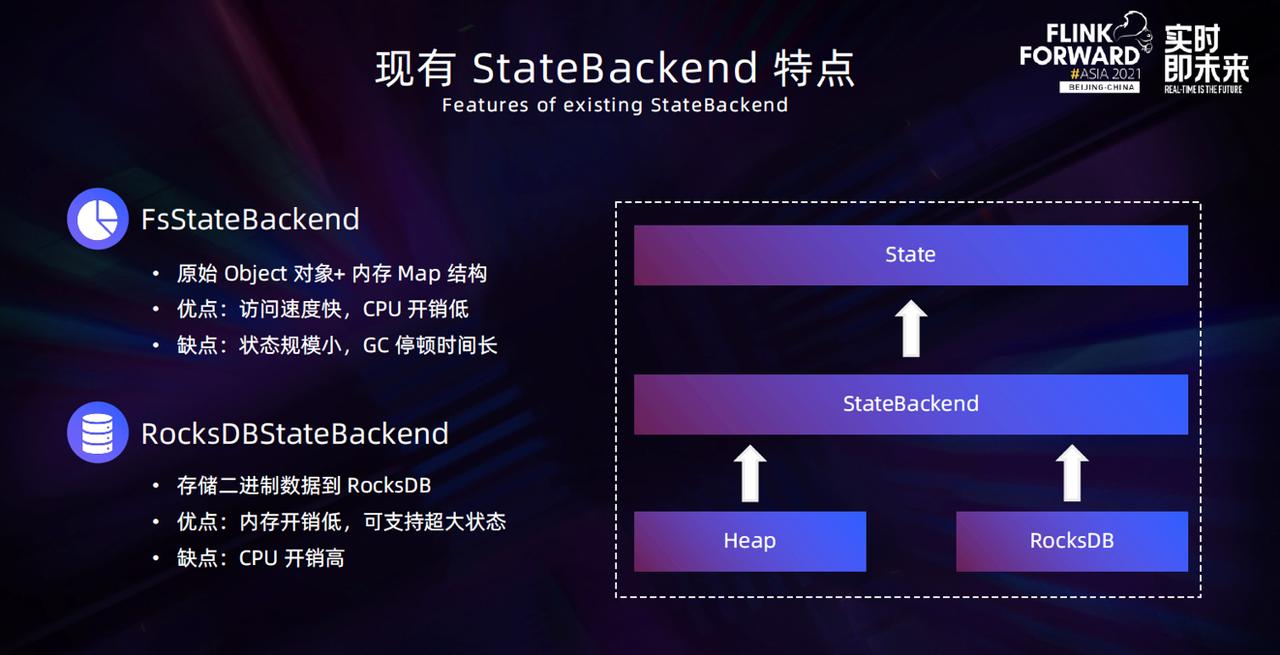**FsStateBackend** 底层实现是在内存中通过 Map 的数据结构来...
字节跳动 Flink 基于 Slot 的资源管理实践
内存大小都比较容易理解,主要是配置启动的计算进程数以及每个进程绑定的物理资源大小。**那么** **Slot** **是什么?为什么需要在** **Flink** **作业启动时配置?**一言以蔽之,Slot 是 Flink 集群管理资源的最小单位,也是 Flink 作业申请和释放资源的单位。本文主要分析 **Flink** **基于** **Slot** **的资源管理** **、作业资源申请以及释放流程。**> 阅读提示:字节跳动内部目前主要使用 Flink-1.11 版本,所以本文分析的 ...
 特惠活动
特惠活动
 Flink高内存使用-优选内容
Flink高内存使用-优选内容
 Flink高内存使用-相关内容
Flink高内存使用-相关内容
打造通用缓存层:字节跳动 Flink StateBackend 性能提升之路
StateBackend 作为 Flink 向上提供 State 能力的基石,其性能会严重影响任务的吞吐。本次分享主要介绍在字节跳动内部通过为 StateBackend 提供通用缓存层,来提高性能的相关优化。作者|字节跳动基础架构研... 通过内存+磁盘进行数据存储,在运行过程中会根据当前的GC情况,以 KeyGroup 的粒度动态地与磁盘上的数据进行交换,来调整内存占用。当 Task 状态特别大的时候,大部分数据会被交换到磁盘上,访问性能会有较大下降,...
StarRocks Flink Connector
StarRocks 支持通过 Flink 读取或写入数据。您可以使用 Flink Connector 连接 Flink 与 StarRocks 实现数据导入,其原理是在内存中对数据进行攒批,按批次使用 Stream Load 将数据导入 StarRocks。Flink Connector 支持 DataStream API、Table API & SQL,以及 Python API,并且相对于 Flink 官方提供的 JDBC Connector 具备更好的性能和稳定性。 1 获取 Flink Connector您可以从 Maven 中央仓库 中下载与您 Flink 版本匹配的最新的 ...
如何调优一个大型 Flink 任务 | 社区征文
需要使用 Flink 的窗口函数,而窗口中就维护了状态信息。这类处理通常对 CPU 和内存都会造成压力,且窗口越长压力越大。注意:这里给出的仅仅是粗略的经验值,由于业务情况不同,例如数据是否压缩、序列化格式、是否需要复杂计算等,均会造成一定偏差。另外,CPU 本身的优劣也会造成一定影响。# 如何拆解性能问题?网上有大量的 Flink 性能调优案例分析,但实际上我们每次遇到性能问题时往往还是无从下手,这是因为没有从案例中总结出...
基于 Flink 构建实时数据湖的实践
用户对其也有了更高的需求:需要从多种数据源中导入数据、数据湖与数据源保持实时与一致、在发生变更时能够及时同步,同时也需要高性能查询,秒级返回数据等。所以我们选择使用 Flink 进行出入湖以及 OLAP 查询。Flin... 占用的内存很大。所以我们需要对表的 Partition 字段进行 Keyby 操作,用来减少 OOM 次数。因为 Iceberg 有隐式分区的特性,所以需要对隐式分区的字段 Transform 之后再进行 Keyby 操作。**03**...
基于 Flink 构建实时数据湖的实践
用户对其也有了更高的需求:需要从多种数据源中导入数据、数据湖与数据源保持实时与一致、在发生变更时能够及时同步,同时也需要高性能查询,秒级返回数据等。所以我们选择使用 Flink 进行出入湖以及 OLAP 查询。Flin... 占用的内存很大。所以我们需要对表的 Partition 字段进行 Keyby 操作,用来减少 OOM 次数。因为 Iceberg 有隐式分区的特性,所以需要对隐式分区的字段 Transform 之后再进行 Keyby 操作。# 数据查询实践## 为什么...
Flink OLAP 在字节跳动的查询优化和落地实践
Flink OLAP 是作为内部自研的高性能 HTAP 产品 -- ByteHTAP 的 AP 引擎,用于支持内部的核心业务。通过支持双机房部署提高容灾能力,每个新接入的业务可以在双机房垂直部署两套 AP 集群,在线上集群出现严重故障时,可... 而不需要在算子启动的时候初始化内存。- 内存使用优化:在并行执行包含大量 Aggregate / Join 算子的 Query 时,发现即使数据量非常小,TM 的Managed Memory 使用也很高。经过排查,对于需要使用 Managed Memory 的...
字节跳动的 Flink OLAP 作业调度和查询执行优化实践
使用 Batch 模式以及计算全拉起的调度模式,减少了计算节点之间的数据落盘且能提升 OLAP 计算的性能。 在 Flink OLAP 计算过程中,主要存在以下几个问题:* Flink OLAP 计算相比流式和批式计算,最大的特点是 Flink OLAP 计算是一个面向秒级和毫秒级的小作业,作业在启动过程中会频繁申请内存、网络以及磁盘资源,导致 Flink 集群内产生大量的资源碎片;* OLAP 最大的特点是查询作业对 Latency 和 QPS 有要求的,需要保证作...
基于 Flink 构建实时数据湖的实践
用户对其也有了更高的需求:需要从多种数据源中导入数据、数据湖与数据源保持实时与一致、在发生变更时能够及时同步,同时也需要高性能查询,秒级返回数据等。所以我们选择使用 Flink 进行出入湖以及 OLAP 查询。Flin... 占用的内存很大。所以我们需要对表的 Partition 字段进行 Keyby 操作,用来减少 OOM 次数。因为 Iceberg 有隐式分区的特性,所以需要对隐式分区的字段 Transform 之后再进行 Keyby 操作。**数据查询实践**...
字节跳动 Flink 状态查询实践与优化
但目前对于 Flink SQL 任务来说,当我们想要查询作业 State 时,通常会因为无法获知 State 的定义方式和具体类型等信息,而导致查询 State 的成本过高。 为了解决这个问题,字节跳动流式计算团队在内部提出了... Task 会把 operatorName\ID\KeySerializer\StateDescriptors 等元信息都保存在 Task 的内存中;* 触发 Savepoint 时,Task 会在制作快照的同时,对状态的元信息也同样进行快照。快照完成之后将状态的元信息 (StateMe...
