协调跨线程池的 Rust 通道
 社区干货
社区干货
字节开源 Monoio :基于 io-uring 的高性能 Rust Runtime
但并不想为了 IO 等待启动多余的线程,如果需要等待 IO,我们希望这时线程可以去干别的,等 IO 就绪了再做就好。这种基于事件的触发机制在 cpp 里面常常会以 callback 的形式遇见。Callback 会打断我们的连续逻辑,导致代码可读性变差,另外也容易在 callback 依赖的变量的生命周期上踩坑,比如在 callback 执行前提前释放了它会引用的变量。但在 Rust 中只需要创建两个 task 并等待 task 执行结束即可。3. Golang#### #### **为什么不用 JavaScript(Node.js) ?** 使用Node.js我们不用担心 API 兼容的问题,但是Node.js 单线程优化的潜力不大,所以尝试使用Node.js 提供的多线程能力提高性能。 我们在实际使用 Node.js 做多线程编程的时候发现有些问题,Node.js 虽然提供了 worker-thread 来提供多线程,但由于它是通过创建新的 V8 实例来模拟多线程,这些 V8 实例...
阿里巴巴的 Java 开发手册(黄山版)来了
需要字符串常量池所在的内存块有足够的空间。然而,因为e.printStackTrace() 语句要产生的字符串记录的是堆栈信息,太长太多,内存被填满了!大量线程产出字符串产出到一半,等待有内存被释放,锁死了,导致整个应用挂掉了。另外,日志交错混合,不易读。printStackTrace()默认使用了System.err输出流进行输出,与System.out是两个不同的输出流,那么在打印时自然就形成了交叉。再就是输出流是有缓冲区的,所以对于什么时候具体输出也形成...
六年安卓开发的技术回顾和展望 | 社区征文
探索适合业务的新方式:跨端(RN Flutter KotlinMultiplatform)、动态化、多端逻辑一致(C/C++ Rust) **第二点:提升质量**和日活几万的项目相比,日活千万甚至上亿的产品,需要应对的质量问题更加显著。在这... 线程过多:在线程创建、释放的 API 里做记录在遇到一个新问题时,发现和之前解决过的有点像,但又不知道哪里像。怎么办?回头去思考新旧的两个问题,它的本质是什么?有什么相似的分析思路?这个思考训练的目...
 特惠活动
特惠活动
 协调跨线程池的 Rust 通道-优选内容
协调跨线程池的 Rust 通道-优选内容
 协调跨线程池的 Rust 通道-相关内容
协调跨线程池的 Rust 通道-相关内容
干货 | 以一次Data Catalog架构升级为例,聊聊业务系统的性能优化
但Max线程数较多的线程池:需要拉取全量上下游的情况是少数,大部分情况下几个Core线程就够用,对于少数情况,再启用额外的线程。* 在批量拉取某一层的元数据后,将每个新拉取的元数据顶点加入到一个线程中,在线程中单独做属性扩充* 等待所有的线程返回对于关系较多的元数据,优化效果可以从分钟级到秒级。对于写入瓶颈的优化 字节的数仓中有部分大宽表,列数超过3000。对于这类元数据,初始的版本几...
抖音春晚幕后|支撑 12 亿红包雨的云原生基础设施
两大支撑团队在短时间内跨多个机房完成了服务器的协调,为整个活动提供了充足的计算资源支撑;凭借云原生基础设施,抖音平稳应对了流量洪峰,用户的红包互动体验也自然流畅。 极致弹性的云原生底层 ... 通过异步和多线程 IO 优化,将热点数据打散和智能搬迁,大大降低 Redis 的长尾时延。在红包雨活动期间,该系统凭借字节跳动庞大的集群数量和机器规模,支撑超过 2.5PB 数据。在大规模分布式系统中,通过消息队列进行...
DataLeap的Catalog系统近实时消息同步能力优化
State Manager:负责维护每个Kafka Partition的消息状态,并暴露当前应提交的Offset信息给MQ Consumer。# 实现## 线程模型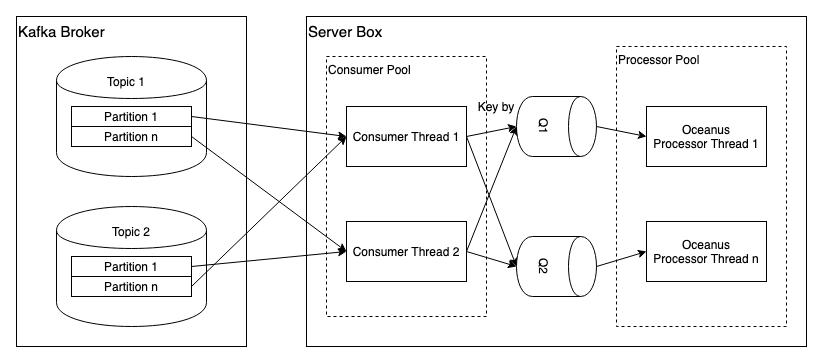每个Task可以运行在一台或多台实例,建议部署到多台机器,以获得更好的性能和容错能力。每台实例中,存在两组线程池:- Consumer Pool:负责管理MQ Consumer Thread的...
基于Prometheus的企业级监控体系探索与实践|社区征文
线程池情况,jvm运行情况等。资源监控方面,我们对社区的NodeExporter进行定制化开发,使其可以通过Eureka进行服务发现。应用监控方面,除了利用社区JmxExproter,我们提供了一套标准化的应用监控SDK,即插即用,提供... 主要提供了分层联邦和跨服务联邦(联邦官方文档)。本质上就是采集级联,说白了就是 a 从 b,c,d那里再采集数据过来,其实有很大的问题,本质上Prometheus的单机能力依旧没有得到解决。我们最初的方案是利用remote_rea...
干货|七个方向,基于开源工具构建一款智能化BI
自动将数据字段分配到合适的视觉通道上,极大地增强用户进行探索式分析的能力,轻松制作可视化报表。 *DataWind图表推荐演示* **/ 实现揭秘 /**-------------...
浅谈分布式操作系统 KubeWharf 的第二批开源项目|社区征文
我们在单机上引入第三方组件负责确定协调给在线和离线的资源量,并与 Kubelet 或 Node Manager 等单机组件打通;同时当在线和离线工作负载调度到节点上后,也由该协调组件异步更新这两种工作负载的资源分配。 该... 都能实现在相同节点上的并池运行,不需要通过硬切集群来隔离,实现更好的资源流量效率和资源利用效率。 在 QoS 的基础上,Katalyst 同时也提供了丰富的扩展 Enhancement 来表达除 CPU 核心外其他的资源需求: ...
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
问题原因是我们的服务是跨国的,垮了很多的时区位置,甚至在墨西哥的时候还需要考虑的是冬令时和夏令时的缘故,所以对时间特别的敏感,所以这就需要再K8s在不同的地区建立不同的指定时区才可以,例如下图所示。负载均衡体系|社区征文
还有一些各种内存池、线程池 等初始化工作要做;而这些初始化工作在某些情况下可能需要一点耗时;或者某些情况下是有请求过来后才进行初始化,但是由于初始化需要时间,因此 Readiness 探针 OK 之后,还不能马上提供大量服务,否则在启动的时候就可能造成服务的些许不稳定,从而降低 SLA,给业务带来影响。 这个是我们实际 Java 项目所得出的结论,因为 jit 的影响,如果在低流量下完成 jit 编译,这样给一个缓冲时间,最终效果就是可以提高...
干货|字节跳动基于Apache Atlas的近实时消息同步能力优化
线程模型每个Task可以运行在一台或多台实例,建议部署到多台机器,以获得更好的性能和容错能力。每台实例中,存在两组线程池:* Consumer Pool:负责管理MQ Consumer Thread的生...
