什么是实体-关系图数据库中的扇出(fan-out)?
 社区干货
社区干货
阿里巴巴的 Java 开发手册(黄山版)来了
我仔细一看这不是孤尽老师的著作吗?居然已经更新到了黄山版。上次看这本小册子的时候还是上次——19年的时候我看的华山版的。再往前那就是17年的第一版了,当时是在阿里的公众号下载的,后来还买了实体的《Java开发... 再就是输出流是有缓冲区的,所以对于什么时候具体输出也形成了随机。一般打印错误日志的时候我们都是用日志框架的`log.error("",e)`,基本够用了。### 2.7 数据库> 小数类型为 decimal,禁止使用 float 和 doub...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
#### 2.1 什么是NL2SQLNL2SQL(Natural Language to SQL), 顾名思义是将自然语言转为SQL语句。它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### ... 因此表格中的数据是真实且没有经过归一化的,一个cell内可能包含多个实体或含义,比如「Beijing, China」或「200 km」;同时,为了很好地泛化到其它领域的数据,该数据集测试集中的表格主题和实体之间的关系都是在训练集...
一文读懂火山引擎云数据库产品及选型
业界将关系型数据库与 NoSQL 数据库的优势进行了融合,出现了 NewSQL 数据库,随着云原生技术的入场与爆发,又有了云原生数据库。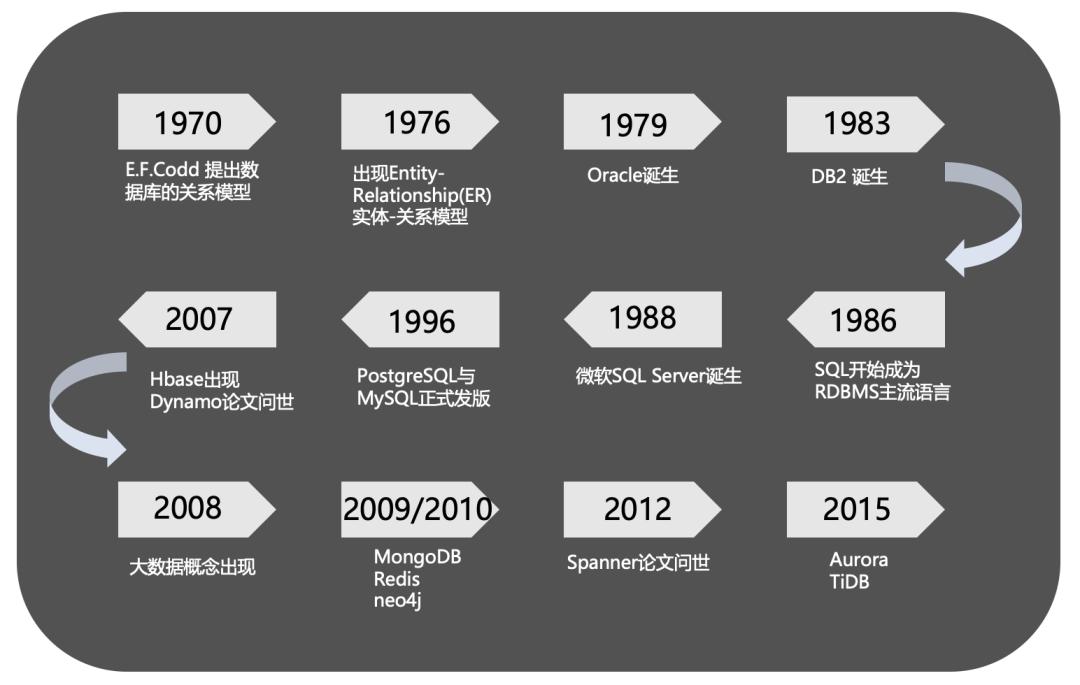**关系型数据库**将数据存储于二维表格之中,数据以行为单位,一行数据表示一个实体信息,每一行数据的属性都是相同的,通过 SQL 语言进行操作,容易理解,广泛应用于企业的...
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
有些类型的实体可以作用于多种其他的实体,比如一张Hive表和一堆被组织在一起的业务报表,都可以被用户收藏或点赞。我们将收藏、点赞这些行为也抽象为实体,并通过关系与Hive表、业务报表集合等相关联。这种思想,类似... 一是列十分多的大宽表,对于一些机器学习的表,甚至会超过1万列;另外一种情况是被广泛引用的底表,比如埋点底表的一级血缘下游就超过了1万。在读取这类数据时,我们发现性能极差。与关系型数据库慢查询优化类似,我们...
 特惠活动
特惠活动
 什么是实体-关系图数据库中的扇出(fan-out)?
-优选内容
什么是实体-关系图数据库中的扇出(fan-out)?
-优选内容
 什么是实体-关系图数据库中的扇出(fan-out)?
-相关内容
什么是实体-关系图数据库中的扇出(fan-out)?
-相关内容
干货 | 字节跳动构建Data Catalog数据目录系统的实践(下)
有些类型的实体可以作用于多种其他的实体,比如一张Hive表和一堆被组织在一起的业务报表,都可以被用户收藏或点赞。我们将收藏、点赞这些行为也抽象为实体,并通过关系与Hive表、业务报表集合等相关联。这种思想,类似... 一是列十分多的大宽表,对于一些机器学习的表,甚至会超过1万列;另外一种情况是被广泛引用的底表,比如埋点底表的一级血缘下游就超过了1万。在读取这类数据时,我们发现性能极差。与关系型数据库慢查询优化类似,我们...
火山引擎 Iceberg 数据湖的应用与实践
Iceberg 相较于 Hive 表是基于设计的文件组织形式实现的上述优点,和 Hive Metastore 把元数据存在 MySQL 上的数据库不一样, Iceberg 是把元数据以文件的形式存在 HDFS 或对象存储上。最上层的 Catalog 也就是表的目... 通过这种层级关系保存了一个从 Iceberg 表到底层所有数据文件的映射。因此只需要依靠读元数据文件就可以获取一张 Iceberg 表里面所有的数据文件而不需要做 File Listing,从而更适用于对象存储的场景。 **第二...
基于 Flink 构建实时数据湖的实践
上图示例中原始 Schema 是 id、name、age,在 Schema 匹配情况下的写入不会报错,所以 Row 1 可以写入;Row 2 写入时由于长度不符合,所以会报错:Index out of range;Row 3 写入时,由于数据类型不匹配,会报错:Class ca... Flink 为输入和输出定义了全面的接口,并实现了许多嵌入式连接器,如数据库、数据湖仓库。用户也可以基于这些接口轻松实现定制的连接器。## OLAP 架构,而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Fli... 又或者是落盘到成本较高的OLAP数据库中。但是当前,可以通过将中间结果近实时增量同步至数据湖,在湖中支持多种类型的分析监控,比如说多数据源对照,全局异常检测,大型商家或关键 KOL达人的实体抽测等等。从而实现了操...
支持的云服务
是一种由CPU、内存、云盘组成的资源集合,每一种资源都会逻辑对应到数据中心的计算硬件实体。 volcengine_ecs_deployment_set 部署集volcengine_ecs_deployment_set_associate部署集绑定volcengine_ecs_instance 弹... volcengine_network_interface 网卡volcengine_network_interface_attach 网卡绑定volcengine_route_table 路由表volcengine_route_entry 路由表配置volcengine_route_table_associate 路由表绑定volcengine_sec...
分布式数据库TiDB的设计和架构
=&rk3s=8031ce6d&x-expires=1714666832&x-signature=Jg4q4fAnvtXw9moqfueTrmNRDAA%3D)第十二期技术夜校分享嘉宾是DBA大咖——Xiaoyu他拥有10年+互联网数据库运维经验、在游戏、电商、OTA行业从事过DBA运维工作、在大规模数据库自动化、平台化方面有较资深的落地经验。# 导语市场上有很多数据库产品,如Oracle、MySQL、SQLServer、NoSQL、NewSQL等,那么目前数据库圈最火的分布式关系型数据库之一TiDB你了解吗?相信很多同学...
干货 | 以一次Data Catalog架构升级为例,聊聊业务系统的性能优化
引入了字节内部的图数据库veGraph,写入时,需要业务层处理MySQL、ElasticSearch和veGraph三种存储,模型也需要同时理解关系型和图两种。更多的背景可以参照之前的[文章](https://mp.weixin.qq.com/s?__biz=MzkwMzMw... .out('r:DataStoreBusinessDomainRelationship') .groupCount().by('__typeName') .profile(); ```优化后的Gremlin如下,耗时~50ms:```...
解读火山引擎 EMR Stateless 的创新理念以及应用
什么是瞬态集群,什么是 Stateless 理念,本文从基础概念、架构体系、演进过程、实际运用场景&使用价值等多个角度全方位介绍 EMR Stateless 的创新理念以及应用。