讨论进程地址空间中的字符串部分时,什么是所提到的对齐方式?
 社区干货
社区干货
【拥有新时代的通信协议,引领云原生迈向更高的舞台】解密Dubbo3从微服务升华到云原生 | 社区征文
Dubbo之前的服务治理都是接口层级的。同一个应用发布的多个服务会在注册中心注册多份数据,注册服务的元数据相互独立。但是存储在注册中心中的数据会在很大程度上存在重复的内容,其实浪费了一部分的存储。###### ... 同时也引入了其他的核心组件,完美的解决了接口以及应用指令层面的都兼容的场景!下图就是两种不同方式的服务治理机制: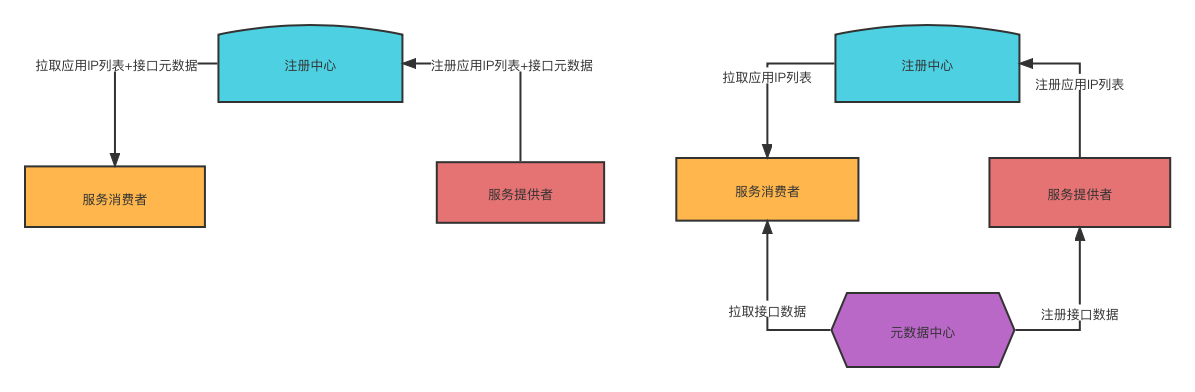左边...
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
并允许用户以可移植的方式在任何 Kubernetes 环境和支持的存储提供程序上合并快照操作。6. **【容器能力扩展】在v1.20版本开始它移除 dockershim** ,从而就实现了可以扩展为其他容器实现的急促> tips:维护dock... 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。 初始延迟之前的就绪态的状态值默认为 Failure。 如果容器不提供就绪态探针,则默认状态为 Success。- startupProbe:指示容器中的应用是...
Kubernetes 观测:基于 eBPF 的云原生深度可观测性实践
难以回答诸如“究竟是谁访问我发生了故障”“我究竟影响了下游哪些实例”“是什么原因导致发生了丢包” 等问题。* **埋点困难**传统 APM 方案需要依赖 SDK/Javaagent 的方式来进行插桩埋点,这给在多协议、... ## **eBPF 具备全栈深度观测潜力**除了提供了很多预定义的 Hook 之外,eBPF 还允许我们创建内核探针 (kprobe) 或用户探针 (uprobe) 来将 eBPF 程序附加到内核或用户应用程序中的几乎任何位置。如下图所示,工程师...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇和挑战。 通过前面提到的这些趋势,我们也可以看出当前需要解决的一些问题及为实现... 训练模型所需的计算资源也在不断提升。然而如果样本的读取速度无法跟上算力的增长就会成为训练过程中的瓶颈,限制算力资源的有效利用率。所以我们需要寻找方法来提高样本的读取吞吐量,确保可以充分利用现有的算力资...
 特惠活动
特惠活动
 讨论进程地址空间中的字符串部分时,什么是所提到的对齐方式?
-优选内容
讨论进程地址空间中的字符串部分时,什么是所提到的对齐方式?
-优选内容
 讨论进程地址空间中的字符串部分时,什么是所提到的对齐方式?
-相关内容
讨论进程地址空间中的字符串部分时,什么是所提到的对齐方式?
-相关内容
KubeZoo:字节跳动轻量级多租户开源解决方案
是一种打造 Serverless Kubernetes 底座的优良方案。作者 | kubzoo-dev**项目地址**:[https://github.com/kubewharf/kubezoo](https://www.oschina.net/action/GoToLink?url=https%3A%2F%2Fgithub.com%2Fkubew... Namespace 是 Kubernetes 原生的资源,提供了原生的基于命名空间的多租户能力。众所周知,Kubernetes 的对象分为两种类型:- 第一种是 namespace scope,比如常见的 deployment、pod 和 pvc 等,这类资源通常比较常...
干货|ByteHouse如何将OLAP性能提升百倍?
有效避免了传统 MPP 架构中的 Re-sharding 问题,同时保留了MPP并行处理能力。 ******●******数据一致性与事务支持。 ********●********计算资源隔离,读写分离:通过计算组(VW)概念,对宿... 全局字典主要功能是通过全局字典编码的方式将变长的字符串转化为电长的数值。针对 AGG function 和 exchange 算子,不仅在单节点上单节点以,也可以在跨节点间直接进行这个编码值的计算,以此提升计算效率。 ...
支持200万字长上下文,Kimi的背后都藏着哪些硬科技?
200万字超长无损处理 快速整理大量资料常常是用户在工作中的一大难题。以简历筛选为例,公司HR可以根据具体需求,利用 Kimi 阅读500份简历,迅速筛选出具备某行业经验和计算机类专业背景的求职者,从而更高效地识别和选择合适的候选人。 自动筛选简历 从20万字到200万字,由于没有采用常规的渐进式提升路线,月之暗面团队遇到的技术难度也呈指数级增加。为了达到更好的长窗口无损压缩性能,研发和技术团队从模型预训练到对齐、推理环节...
Redis的数据被删除,占用内存咋还那么大?| 社区征文
Redis 进程占用的内存一定会降低么?(也叫做 RSS,进程消耗内存页数)。**答案是:可能依然占用了大约 5GB 的内存,即使 Redis 的数据只占用了 3GB 左右。**大家一定要设置`maxmemory`,否则 Redis 会继续为新写入... Redis 自身空进程占用的内存很小可以忽略不计,对象内存是占比对打的一块,里面存储着所有的数据。缓冲区内存在大流量场景容易失控,造成 Redis 内存不稳定,需要重点关注。**内存碎片过大会导致明明有空间可用,但...
KubeZoo:字节跳动轻量级多租户开源解决方案
Namespace 是 Kubernetes 原生的资源,提供了原生的基于命名空间的多租户能力。众所周知,Kubernetes 的对象分为两种类型:* 第一种是 namespace scope,比如常见的 deployment、pod 和 pvc 等,这类资源通常比较常... Cluster as a Service 则是为每个租户分配一个完整的集群,包括独占的控制面和数据面。如此每个租户都有独立的 Master 和计算节点,该 Master 可以通过 Cluster API 等方式完成租户 Master 的生命周期管理。在...
2022年终总结-两年Androider的技术成长之路|社区征文
但是花费了我巨多的时间:比如**沈奕斐老师的社会爱情思维课**我花费了八个小时来记录两个小时的老师的干货输出;奇葩说中的老师演讲大部分也在两个小时时间短的我可能花费了五个小时,时间长的我整整花费了三天时间去... 看到这句话的时候释怀了6.经历反哺普世知识,普世知识拓展预测经历,没有经历和反思过得东西必然索然无味,**自己的想法和别人提到的信息如果只是记录的话,没什么用处**。**因为没有经历所以觉得不重要,没有实际的用...
MAD,现代安卓开发技术:Android 领域开发方式的重大变革|社区征文
> Android 诞生已久,其开发方式保持着高频更迭,相较于早期的开发方式已大不相同,尤其是近几年 Google 热切推崇的 MAD 开发技术。> > **其实很多开发者已经有意或无意地正在使用这门技术,借着 2023 开年探讨技术趋... 有的时候 Google 会将其翻译成`现代安卓开发`,有的时候又翻译成`新式安卓开发`,个人觉得前者的翻译虽然激进、倒也贴切。下面按照 MAD 的构成要点逐步展开,帮助大家快速了解 MAD 的技术理念。如果大家对其中的语言...
火山引擎大规模机器学习平台架构设计与应用实践
模型训练过程中的网络通信带宽、训练资源数和时长都不尽相同。所以面对丰富的机器学习应用,我们的需求是多样的。针对这些需求,底层的计算、存储、网络等基础设施要提供强大的硬件,同时在这些硬件基础上还要提供强大... 上图是某真实用户的线上申请率,可以看到申请率可以达到 95% 以上。这里的利用率其实是由客户的代码自己决定的。### 模型分布式训练加速在分布式训练中,加速方式主要从计算、通信、显存三个角度考虑。在计算侧...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇和挑战。通过前面提到的这些趋势,我们也可以看出当前需要解决的一些问题及为实现降... 训练模型所需的计算资源也在不断提升。然而如果样本的读取速度无法跟上算力的增长就会成为训练过程中的瓶颈,限制算力资源的有效利用率。所以我们需要寻找方法来提高样本的读取吞吐量,确保可以充分利用现有的算力资...
