Spark异常:必须在配置中设置主节点的URL
 社区干货
社区干货
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
## 一、Spark 架构原理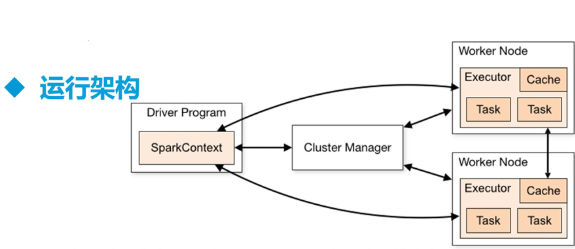> SparkContext 主导应用执行> > Cluster Manager 节点管理器> > 把算子RDD发送给 Worker Node> > Cache : Worker Node 之间共享信息、通信> > Executor 虚拟...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。**本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。**... 在代码中只需要通过如下的代码方式:```Class.forName("com.mysql.cj.jdbc.Driver");Connection connection= DriverManager.getConnection(DB_URL,USER,PASS);//操作connection.close();```第一,初始化驱...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致> 难满足日常的业务开发需求。> **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门... 在代码中只需要通过如下的代码方式:``` Class.forName("com.mysql.cj.jdbc.Driver"); Connection connection= DriverManager.getConnection(DB_URL,USER,PASS); //操作 ...
干货|字节跳动数据技术实战:Spark性能调优与功能升级
文章会为大家讲解字节跳动 **在Spark技术上的实践** ——LAS Spark的基本原理,分析该技术相较于社区版本如何实现性能更高、功能更多,为大家揭秘该技术做到极致优化的内幕,同时,还会为大家带来团队关于LAS Spark技... 将7个并行度调整为2个并行度,最终产出2个文件。=============================================================================================== **●****FragPartitionCompaction:**主要适用分区...
 特惠活动
特惠活动
 Spark异常:必须在配置中设置主节点的URL
-优选内容
Spark异常:必须在配置中设置主节点的URL
-优选内容
 Spark异常:必须在配置中设置主节点的URL
-相关内容
Spark异常:必须在配置中设置主节点的URL
-相关内容
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
> SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。**本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。**... 在代码中只需要通过如下的代码方式:```Class.forName("com.mysql.cj.jdbc.Driver");Connection connection= DriverManager.getConnection(DB_URL,USER,PASS);//操作connection.close();```第一,初始化驱动...
使用 VCI 运行 Spark 数据处理任务
介绍使用 VCI 运行 Spark 任务的操作。主要流程如下: 创建集群 连接集群 安装 spark-operator 测试 spark-operator 如果您需要使用更多 VCI 的高级功能,可以通过设置 Annotation(注解)对 VCI 进行参数配置。详情请... 部分参数配置如下所示,其余参数,请参见 创建集群 中的说明,完成配置。说明 创建集群过程中添加节点时,建议您结合自己业务实际需求和安装运行 Spark Operator 的需求,选择合适的节点规格,保证节点的 vCPU、内存等满...
Iceberg 基础使用
2 操作步骤使用 SSH 方式登录到集群主节点,详情请参见使用 SSH连接主节点。 执行以下命令,通过 Spark SQL 读写 Iceberg 配置: 在 Spark SQL 中操作 Iceberg,首先需要配置 Catalog。Catalog的配置以 spark.sql.... 固定值为org.apache.iceberg.spark.SparkCatalog。 spark.sql.catalog.hive.type:Catalog type,可以配置为hive 或hadoop。本示例中采用hive。 spark.sql.catalog.hive.uri :Hive Metastore 的 url 地址,格式为:t...
Cloud Shuffle Service 在字节跳动 Spark 场景的应用实践
> 本文整理自字节跳动基础架构的大数据开发工程师魏中佳在 ApacheCon Aisa 2022 「大数据」议题下的演讲,主要介绍 Cloud Shuffle Service(CSS) 在字节跳动 Spark 场景下的设计与实现。作者|字节跳动基础架构的大... 来减轻对同节点上高优作业的影响。整体的思路是当我们发现 ESS 响应请求的 Letency (延迟)升高到一定程度时,比如 10 秒或 15 秒,我们就认为这个节点当前处于异常状态,这时 ESS 就会针对内部正在排队的 Fetch 请求...
配置 Spark 访问 CloudFS
Spark 是专为大规模数据分析处理而设计的开源分布式计算框架。本文介绍如何配置 EMR 中的 Spark 服务使用 CloudFS。 前提条件开通大数据文件存储服务并创建文件存储实例,获取挂载点信息。具体操作,请参见开通大数据文件存储。 完成 E-MapReduce 中的集群创建。具体操作,请参见 E-MapReduce 集群创建。 准备一个测试文件。 步骤一:配置 CloudFS 服务说明 集群所有节点都要修改如下配置。 连接 E-MapReduce 集群,连接方式如下: 使...
Cloud Shuffle Service 在字节跳动 Spark 场景的应用实践
本文整理自字节跳动基础架构的大数据开发工程师魏中佳在 ApacheCon Aisa 2022 「大数据」议题下的演讲,主要介绍 Cloud Shuffle Service(CSS) 在字节跳动 Spark 场景下的设计与实现。作者|字节跳动基础... 来减轻对同节点上高优作业的影响。整体的思路是当我们发现 ESS 响应请求的 Letency (延迟)升高到一定程度时,比如 10 秒或 15 秒,我们就认为这个节点当前处于异常状态,这时 ESS 就会针对内部正在排队的 Fetch 请求,...
喜讯!火山引擎 Flink、Spark 产品通过信通院可信大数据能力评测
在第五届“数据资产管理大会”上,中国信息通信研究院(中国信通院)公布了第十五批“可信大数据”产品能力评测结果。 **火山引擎** **流式计算 Flink 版**和 **火山引擎** **批式计算 Spark 版** **凭借出色的... 在开发效率上对开源版本 Flink 有显著提升。* **可靠性提升。**流式计算 Flink 版针对单个 Task 进行 Checkpoint,提高了大并发下的 Checkpoint 成功率。单点任务恢复和节点黑名单机制功能,保障了对故障节点的快速...
字节跳动 Spark 支持万卡模型推理实践|CommunityOverCode Asia 2023
本文整理自字节跳动基础架构工程师刘畅和字节跳动机器学习系统工程师张永强在本次 CommunityOverCode Asia 2023 中的《字节跳动 Spark 支持万卡模型推理实践》主题演讲。 **0****1**... 字节跳动拥有业界领先的 Spark 业务规模,每天运行数百万的离线作业,占有资源量数百万核,GPU 数万张卡,总集群规模节点也达到了上万台。如此大规模的 Spark 负载意味着要实现 Spark 彻底原生化不是一件容易的事情。以...
EMR Spark
4 任务配置说明新建任务完成后,您可在任务配置界面完成以下参数配置: 4.1 语言设置语言类型支持 Java、Python。 注意 语言类型暂不支持互相转换,切换语言类型会清空当前配置,需谨慎切换。 4.2 引入资源语言类型... 4.3 参数配置参数 说明 Spark 参数 Main Class 语言类型为 Java 时填写,需填写主类信息,如 org.apache.spark.examples.JavaSparkPi。 Conf参数 配置任务中需设置的一些 conf 参数,例如您可通过spark.yar...
