假设转换输入已排序,MERGE和UNIONALL有什么区别?
 社区干货
社区干货
干货|高性能、高稳定、高扩展:解读ByteHouse实时导入技术演进
能够支撑实时数据分析和海量离线数据分析;便捷的弹性扩缩容能力,极致的分析性能和丰富的企业级特性,助力客户数字化转型。**本文将从需求动机、技术实现及实际应用等角度,介绍基于不同架构的ByteHouse实时导入技术... 并降低后台Merge线程的压力。 ### **/ 无法满足的需求 /** **上述社区的设计与实现,还是无法满足用户的一些高级需求:** **●** 首先部分高级用户对数据的分布有着比较严格的要求,比...
漫谈开源许可证:开发者需要知道的法理和事例
merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:The above copy... 有什么不同?(****#MereAggregation****)**“聚合版”包含有多个独立的程序,并在同一个 CD-ROM 或其他媒体上发行。GPL 允许你制作并发布一个聚合版,即使其他软件的许可证不是自由许可证或不是 GPL 兼容的许可证...
高性能、高稳定、高扩展:解读 ByteHouse 实时导入技术演进
并降低后台 Merge 线程的压力。**无法满足的需求****上述社区的设计与实现,还是无法满足用户的一些高级需求:*** 首先部分高级用户对数据的分布有着比较严格的要求,比如他们对于一些特定的数据有特定的 K... 让每个线程来消费不同 Partition。从而完全继承了社区 Kafka 表引擎两级并发的优点。在 Low-Level 消费模式下,上游用户只要在写入 Topic 的时候,保证没有数据倾斜,那么通过 HaKafka 导入到 Clickhouse 里的数据...
干货|字节跳动数据技术实战:Spark性能调优与功能升级
合并小文件主要是两种思路: **MergeFile和FragPartitionCompaction,** 使用场景和具体实现均不同。 **●****MergeFile:**主要适用分区数据量均匀的场景,即每个分区的总数据量差异不大,且分区内部均有小文件。这种场景主要是因为Spark任务的最后一个stage并行度较大导致,如下左图,InsertInto之前的最后一个Operator的并行度为7,则最终也会产出7个文件。============================================================...
 特惠活动
特惠活动
 假设转换输入已排序,MERGE和UNIONALL有什么区别?
-优选内容
假设转换输入已排序,MERGE和UNIONALL有什么区别?
-优选内容
 假设转换输入已排序,MERGE和UNIONALL有什么区别?
-相关内容
假设转换输入已排序,MERGE和UNIONALL有什么区别?
-相关内容
干货|字节跳动数据技术实战:Spark性能调优与功能升级
合并小文件主要是两种思路: **MergeFile和FragPartitionCompaction,** 使用场景和具体实现均不同。 **●****MergeFile:**主要适用分区数据量均匀的场景,即每个分区的总数据量差异不大,且分区内部均有小文件。这种场景主要是因为Spark任务的最后一个stage并行度较大导致,如下左图,InsertInto之前的最后一个Operator的并行度为7,则最终也会产出7个文件。============================================================...
基于 LoserTree 的 Paimon 多路归并优化
而胜者树和败者树调整时的比较次数都是 logN,区别是胜者树需要和兄弟节点进行比较并更新父节点,而败者树只需要和父节点进行比较,访存次数更少。目前在 Paimon 中默认使用堆排序实现 SortMergeReader,因此考虑使用 ... 排序过程分为建堆和堆调整两个过程。在整个排序过程中,如果父子节点进行比较后发生了数据交换,那么会产生自顶向下的调整,这种调整每次都需要和两个子节点同时进行比较。1. **建堆**假设有 5 个待排序列,第一步...
[数据库论文研读] HTAP行列混存 & 智能转换
而OLAP中根本没有“事务”的概念,基本上可以认为只有read/scan操作。- OLTP应用在存储侧的layout一般为行存,OLAP应用则一般为列存因为OLTP和OLAP的差异,现有的数据分析系统(或者说数据分析的pipeline)一般是部... 管控面的麻烦从外部转移到内部而已,并没有什么实际的架构创新。**所以,本论文提出了一种新的想法,**不再“分而治之”,而是要构建一个统一的存储层**,使用统一的data layout来管理表数据,这种layout里的“热数据”...
LAS Spark 在 TPC-DS 的优化揭秘
且已在内部生产环境得到验证。**文末更有专属彩蛋,新人优惠购福利,等着你来解锁!**本篇文章提纲如下:- TPC-DS 简介- 性能表现- 自研优化策略- 总结## 1. TPC-DS 简介针对数据库不同的使用场景... #### 3.1.6 Push Union Through JoinUnionAll 和 Join 是 TPCDS 以及业务 SQL 中常见的算子,在视图 VIEW 中此二者的组合尤其常见。我们观察到,在 UnionAll 的子查询中,如果 Join 存在公共子表,可以调整 UnionAll...
20000字详解大厂实时数仓建设 | 社区征文
什么差别,只是在查询模式上,有的是特定业务场景,有的是通用业务场景。针对第 3 种和第 4 种,它对于更新的要求比较低,对于吞吐的要求比较高,过程之中的曲线也不要求有一致性。第 4 种查询模式更多的是单实体的一些查询,比如去查询内容,会有哪些指标,而且对 QPS 要求比较高。_3.2 技术方案_针对上方 4 种不同的场景,我们是如何去做的?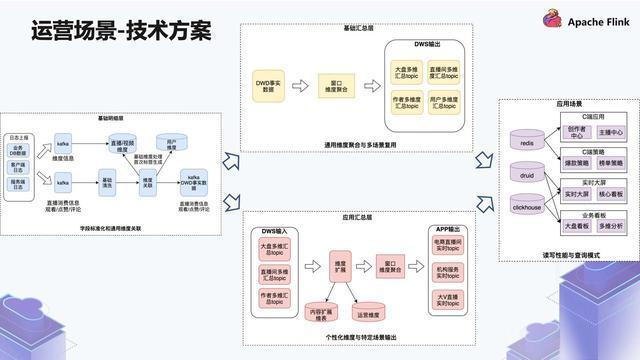首先看一下基础明细层 ...
Apache Pulsar 在火山引擎 EMR 的集成与场景
各种面向不同场景的大数据计算、存储组件以及贯穿整个 EMR 服务端到端的管控面。EMR 向上可以对接火山引擎的大数据研发治理套件 DataLeap,支持用户构建数据仓库,赋能百行百业,助力企业决策,帮助业务成长,体现数据价... 那么如果 Pulsar 与用户既有的一些系统(如 Kafka)兼容,就可以零成本或者低成本地把既有的业务代码放到 Pulsar 上来体验,更易于用户去体验 Pulsar 的各种令人瞩目的特性和功能。这一点对用户的价值很大。假设 Pulsa...
火山引擎ByteHouse:10亿数据、查询<10s,论基于OLAP搭建广告系统的正确姿势
同时由于人群查询在不同标签组合下的结果集大小不同,在一次广告投放中,分析师需要经过多次的逻辑调整,以获得"最好"的人群包。在这种高频的操作下,画像平台通常会遇到两方面的问题:* 第一,由于此类查询分析是临... 由于即时查询的实时性和灵活性,转化好的数据通常会写入OLAP引擎,例如ByteHouse,以提供灵活且实时的SQL查询。用户在分析时,一般会从画像平台应用界面去可视化构建标签逻辑,再由平台应用将这些逻辑转化成SQL,发给Byt...
字节跳动实时数据湖构建的探索和实践
没有什么规律可言,并且底表的数据量会比较大,新增的数据量通常相比底表会比较小。在这种场景下,我们可以**选用哈希索引、State索引和Hbase索引来做到高效率的全局索引**。这两个例子说明了不同场景下,索引的选择也会决定了整个表读写性能。Hudi提供多种开箱即用的索引,已经覆盖了绝大部分场景,用户使用成本非常低。### 02 - Merge On Read表格式除了索引系统之外,Hudi的Merge On Read表格式也是一个我们看重的核心功能之...
干货 | UniqueMergeTree:支持实时更新删除的ClickHouse表引擎
**key-based merge on read**第一个方案叫key-based merge on read,它的整个思想比较类似LSMTree。对于写入,数据先根据key排序,然后生成对应的列存文件。每个Batch写入的文件对应一个版本号,版本号能用来表示数据的写入顺序。同一批次的数据不包含重复key,但不同批次的数据包含重复key,这就需要在读的时候去做合并,对key相同的数据返回去最新版本的值,所以叫merge on read方案。ClickHouse的ReplacingMergeTree和Dori...
