如何支持RDMA的GPUDirect功能?
 社区干货
社区干货
火山引擎大规模机器学习平台架构设计与应用实践
如何应以上这些挑战的呢?#### 专为 AI 优化的高性能计算集群大型模型的训练需要具备高性能与高可用性的计算集群支撑。因此我们搭建了火山引擎 AI 异构计算平台,提供面向 AI 场景优化的超算集群。- **超大算力池:** 搭载英伟达 Tesla A100 80GB/A30/V100/T4;2TB CPU Mem;单一集群 2000+ GPU 卡,提供 1 EFLOPS 算力。 - **超强网络性能:** 机内 600GBps 双向 NVLink 通道,800Gbps RDMA 网络高速互联,支持 GPU Direct Acc...
火山引擎大规模机器学习平台架构设计与应用实践
如何应以上这些挑战的呢?**专为 AI 优化的高性能计算集群**大型模型的训练需要具备高性能与高可用性的计算集群支撑。因此我们搭建了火山引擎 AI 异构计算平台,提供面向 AI 场景优化的超算集群。* **超大算力池**:搭载英伟达 Tesla A100 80GB/A30/V100/T4;2TB CPU Mem;单一集群 2000+ GPU 卡,提供 1 EFLOPS 算力。* **超强网络性能**:机内 600GBps 双向 NVLink 通道,800Gbps RDMA 网络高速互联,支持 GPU Direct Acces...
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
功能扩展,此版本尚且没有得到相关的修正且官方不支持修复,只能使用新版本了!2. **【安全问题,以及workaround的问题较多】** 其实新版本与旧版本区别主要在于应用了社区中经过cherrypick挑选出来的PR以及修复了安... DirectMemorySize的控制。以及定时执行System.gc()。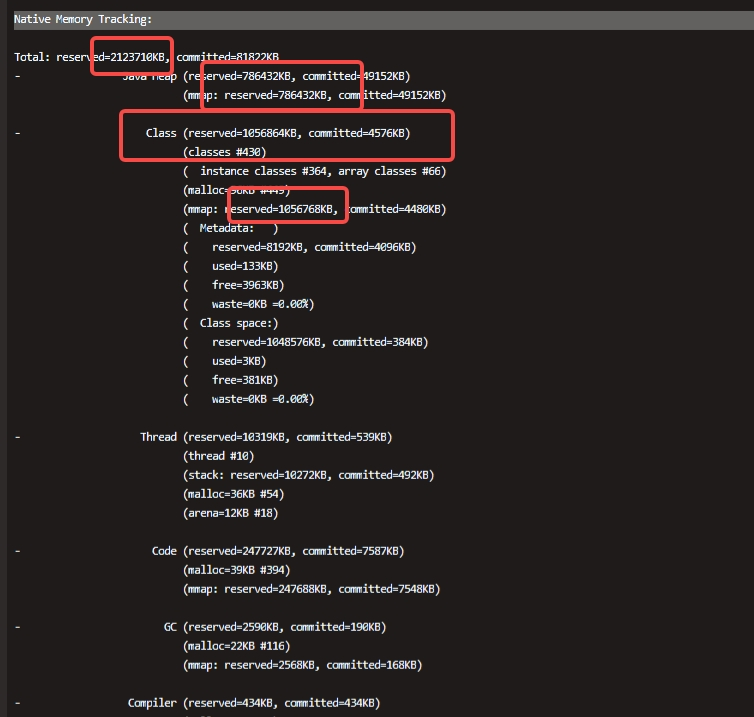#### K8s探测Java进程与堆内存不...
ByteFUSE的演进与落地
自动将来自该Client的请求Redirect到新的活着的Proxy,该机制对客户端是完全透明的。但是使用TTGW具有以下缺点:- **无法支持大吞吐场景;** 用户的吞吐不仅受限于TTGW集群本身吞吐的限制,而且受限于NFS协议单次读... 功能扩展以及性能优化都会变得非常方便。用户使用ByteFUSE和NFS两种协议访问ByteNAS的流程如下图所示: 特惠活动
特惠活动
 如何支持RDMA的GPUDirect功能?
-优选内容
如何支持RDMA的GPUDirect功能?
-优选内容
 如何支持RDMA的GPUDirect功能?
-相关内容
如何支持RDMA的GPUDirect功能?
-相关内容
RDMA 网络监控
容器服务支持通过组件使用 RDMA 资源,以消除传统网络通信带给计算任务的瓶颈。同时,支持对 RDMA 网络进行监控。本文为您介绍如何配置和查看 RDMA 网络的监控信息。 说明 【邀测·申请试用】:该功能目前处于 邀测 阶段,如需使用,请提交申请。 使用限制仅支持 NVIDIA GPU 模式下,采集节点和 Pod 的 RDMA 指标。不支持 mGPU 模式。 共享(shared)模式下,仅上报节点的 RDMA 指标。 独占(exclusive)模式下,仅上报 Pod 的 RDMA 指标。 ...
高性能计算GPU型实例监控新增RDMA相关指标
高性能计算GPU型实例监控新增RDMA相关指标,您可以直接通过云监控服务实时监控RDMA CNP、ECN和QP等相关指标数据,通过自定义指标阈值和告警通知,能够及时知晓高性能计算实例规格中RDMA网卡CNP、ECN和QP等指标超出阈值的情况,及时发现异常指标,确保业务的稳定运行。 可以参考以下内容配置高性能计算GPU型实例的监控告警能力: 高性能计算GPU实例监控指标 配置告警策略 应用场景业务使用高性能计算GPU型实例,希望实时监控RDMA网络情...
高性能计算GPU型实例监控新增RDMA指标
在使用高性能计算GPU型实例进行多机训练时,用户希望能对RDMA性能进行实时监控,并根据相关指标判断网络状态。 本次高性能计算GPU型实例监控新增RDMA相关6个指标,您可以直接通过云监控服务实时监控RDMA网络接收/发送包数量、RDMA网络入/出方向暂停包数量和RDMA网络入/出方向流量暂停时间,如果发现业务运行速度变慢可参考此指标分析是否存在网络拥塞。 说明:此指标和模型算法、网络配置等多种因素有关,建议仅作为观测指标辅助业务分...
RDMA 拓扑感知调度
本文主要介绍使用 RDMA 拓扑感知调度的方法以及使用限制等。 说明 【邀测·申请试用】:该功能目前处于邀测阶段,如需使用,请提交申请。 背景信息在大模型训练等 AI 场景中,经常会出现一个 Job 中的多个 Pod 并行执行训练任务的情况,这些 Pod 在运行过程中需要频繁地相互交换参数、梯度值等数据。为了保障网络通讯开销不成为训练任务的性能瓶颈,通常使用 RDMA 网络在 GPU 之间直接传输数据。而在数据中心当中,一台交换机可以连接的...
高性能计算GPU型
概述高性能计算GPU型规格在原有GPU型规格的基础上,加入RDMA网络,可大幅提升网络性能,提高大规模集群加速比,适用于高性能计算、人工智能、机器学习等业务场景。 说明 您可以在价格计算器页面,查看实例的价格及其配置项(系统盘、数据盘、公网IP等)费用。价格计算器为参考价格,具体请以云服务器控制台实际下单结果为准。 高性能计算GPU型实例不支持变更实例规格。 高性能计算GPU型规格提供的显卡特点如下: 规格名称 显卡类型 特点 ...
高性能计算GPU型
概述高性能计算GPU型规格在原有GPU型规格的基础上,加入RDMA网络,可大幅提升网络性能,提高大规模集群加速比,适用于高性能计算、人工智能、机器学习等业务场景。 说明 您可以在价格计算器页面,查看实例的价格及其配置项(系统盘、数据盘、公网IP等)费用。价格计算器为参考价格,具体请以云服务器控制台实际下单结果为准。 高性能计算GPU型实例不支持变更实例规格。 规格名称 显卡类型 特点 高性能计算GPU型ebmhpcpni2l A800 搭载NV...
查看实例GPU/RDMA监控数据
针对GPU云服务器,火山引擎为您提供了其特有的GPU监控及RDMA监控,可帮助您快速了解实例显卡、RDMA网络信息。 使用说明暂仅支持GPU云服务器使用,规格详情可查看异构计算。 您还可根据创建告警策略指引,配置GPU卡、RDMA卡指标数据异常告警。说明 “告警对象”请选择“弹性计算 > 云服务器”。 “维度”请选择“GPU卡”或“RDMA卡”。 操作步骤登录云服务器控制台。 在顶部导航栏选择目标实例所属的项目和地域。 在左侧导航树,选择...
购买高性能计算GPU型实例
当前默认RDMA设备IP地址为固定的198.x.x.x/33.x.x.x网段,您可以使用该网段在多个具有RDMA网卡的高性能GPU实例之间进行RDMA网络通信。 RDMA网卡和GPU实例绑定后,不支持挂载、卸载RDMA网卡。 RDMA网卡和VPC网络之间... 参考RDMA网络监控手动安装插件。 请不要在插件安装过程中停止或重启实例,导致安装失败,实例重新启动后不再继续安装。 若您使用开启了“RDMA网络观测性增强”功能的hpcpni2实例创建自定义镜像,则该镜像中包含RDMA监...
HPC-单机&多机点对点RDMA网络性能测试
本文以Ubuntu 20.04的ecs.hpcpni2.28xlarge实例为例,介绍如何使用InfiniBand在单台实例内或两台实例间测试RDMA网络性能。 背景信息HPC实例是在原有GPU实例的基础上,加入了RDMA网络,可大幅提升网络性能,提高大规模集群加速比,适用于高性能计算、人工智能、机器学习等业务场景。 InfiniBand是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。 检查RDMA网卡速率登录Linu...
