R语言数据框架中查找最大值的索引
 社区干货
社区干货
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
基于RESTful Web接口,基于Java语言开发,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎,能够达到实时搜索,稳定,可靠,快速,安装使用方便。****```温馨提示:为了保证正确安装和运行,如果可用内存过少,可能导致ES安装或启动失败。查看:RAM内存free -h检查:硬盘空间df -h查看:目录下各文件夹磁盘占用率(ES的data目录指定可根据实际资源情况挂载)du --max-depth=1 -h /***/***ES免安装:这里采用服务器间s...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
Oracle,ElasticSearch,MySQL集群架构 目前,Oracle中多个业务库,数据集极其庞大,MySQL中多个业务库,单表数据量超过千万级别...... 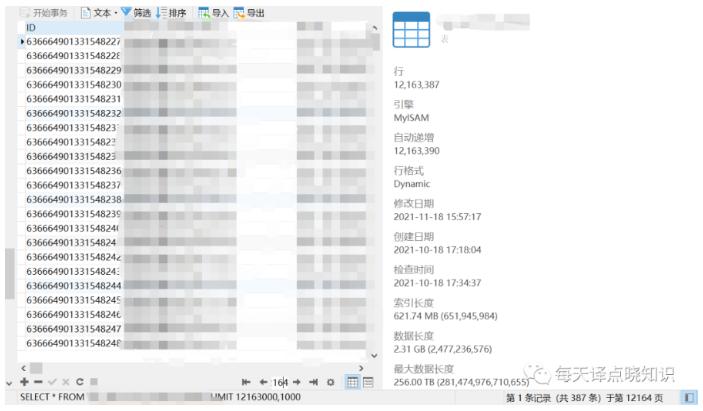随着数据一直在不断增长,往水平方方向扩展节点,虽然能在一定程度上缓解大数据带来的压力,但长久来看,数据库查询性能无疑受到了巨大的冲击!VikingDB 在字节内部的应用向量数据库近来的火热来源于大语言模型的兴起,但在大模型兴起之前,VikingDB 已经在字节内... 文档搜索等需要向量检索的其他场景。在内部推广应用的过程中,VikingDB 经历了非常多样的挑战:超大规模的数据、极致的延迟/性能要求、海量业务场景的接入支持等。为了克服这些困难,我们做了很多架构和性能的优化...
 特惠活动
特惠活动
 R语言数据框架中查找最大值的索引-优选内容
R语言数据框架中查找最大值的索引-优选内容
 R语言数据框架中查找最大值的索引-相关内容
R语言数据框架中查找最大值的索引-相关内容
万字长文带你漫游数据结构世界|社区征文
索引/5716853)技术有关。简单讲,数据结构就是组织,管理以及存储数据的方式。虽然理论上所有的数据都可以混杂,或者糅合,或者饥不择食,随便存储,但是计算机是追求高效的,如果我们能了解数据结构,找到较为适合当前问... 也就是最高的一位表示符号位,`0`表示正数,`1`表示负数,也就是8位的最大值是`01111111`,也就是`127`。值得我们注意的是,计算机的世界里,多了原码,反码,补码的概念:- 原码:用第一位表示符号,其余位表示值- 反码...
Apache Iceberg 中引入索引提升查询性能
partition evolution,schema evolution 等功能。> 本文将讨论火山引擎EMR团队针对 Iceberg 组件的优化思路,通过引入索引来提高查询性能。# 采用 Iceberg 构建数据湖仓火山引擎 E-MapReduce(简称 EMR)是火山引... =&rk3s=8031ce6d&x-expires=1714666880&x-signature=AoQXxPbBYvdAX88NXPzq9YyY6xA%3D)在 Manifest file 中记录了 data file 中字段的最大值和最小值。```"data_file": { "content": 0, "file...
高维向量相似度搜索(pg_vector)
关于 pg_vectorpg_vector 是一款对高维度向量提供高效相似度搜索能力的插件,该插件具备以下功能: 支持向量数据类型,能够存储和查询向量数据。 支持精确和近似最近邻搜索(Approximate Nearest Neighbor,简称 ANN),支... insert 时使用。 最小值为 1,最大值 为 32768,默认值为 100,表示往索引中的数据集分成的列表数。该值越大,表示数据集被分割得越多,各个子集的大小就越小,查询效率就越快。 lists 值不宜过大,建议设置在 2000 以内...
字节跳动湖平台在批计算和特征场景的实践
Apache Iceberg 是由 Netflix 公司推出的一种用于大型分析表的高性能通用表格式实现方案。如上图所示,系统分成引擎层、表格式层、文件格式层、缓存加速层、对象存储层。图中可以看出,Iceberg 所处的层级和 Hudi,DeltaLake 等工具一样,都是表格式层:* 向上提供统一的操作 API* Iceberg 定义表元数据信息以及 API 接口,包括表字段信息、表文件组织形式、表索引信息、表统计信息以及上层查询引擎读取、表写入文件接口等,使得 ...
Apache Iceberg 中引入索引提升查询性能
partition evolution,schema evolution 等功能。本文将讨论火山引擎EMR团队针对 Iceberg 组件的优化思路,通过引入索引来提高查询性能。## 1. 采用 Iceberg 构建数据湖仓火山引擎 E-MapReduce(简称 EMR)是火山... =&rk3s=8031ce6d&x-expires=1714666828&x-signature=q5SoNkGqWDNnUBQ%2BMqZ526yG%2BiY%3D)在 Manifest file 中记录了 data file 中字段的最大值和最小值。```"data_file": { "content": 0, "...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
### 1、场景介绍某银行业务人员想要查询某款理财产品中原财富1号9月销售额度,对于数据工程人员则会考虑写一个SQL语句:`Select sum(sale) from table_name where month= 9 and product_name =‘中原财富1号’`... NL2SQL(Natural Language to SQL), 顾名思义是将自然语言转为SQL语句。它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位...
抖音大规模实践,火山引擎向量数据库是这样炼成的
其典型应用场景比如:基于大语言模型的智能客服、基于企业知识库的问答以及 Chatdoc 等工具应用。 火山引擎向量数据库技术演进之路 **存算分离的分布式架构搭建**在抖音集团内部,早期的向量化检索引擎是围绕搜索、推荐、广告业务来构建的,由于这些业务天然具有极大的数据规模,因此从一开始,就需要思考如何在向量索引中支持百亿数据的检索需求,比如图虫拥有几亿图片素材,数量规模早已超...
字节跳动基于大规模弹性伸缩实现拓扑感知的在离线并池
这些服务通常对 RPC 调用延迟比较敏感。* **离线业务体系:**包含临时查询、定时报表、模型训练、数据分析等作业,这些服务的特点是它们可以承受一定程度的排队或等待,在合理时间得到合理结果即可。为了保证在... 搜索核心服务等;算法服务在运营过程中需要加载大量的在线模型,在资源使用上除了占用 CPU,也会占用较大的内存;同时算法服务不仅对调用延迟较为敏感,对业务的展现效果也有一定要求;为了满足服务的极致性能要求,我们通...
字节跳动基于大规模弹性伸缩实现拓扑感知的在离线并池
这些服务通常对 RPC 调用延迟比较敏感。- **离线业务体系:** 包含临时查询、定时报表、模型训练、数据分析等作业,这些服务的特点是它们可以承受一定程度的排队或等待,在合理时间得到合理结果即可。为了保证在... 搜索核心服务等;算法服务在运营过程中需要加载大量的在线模型,在资源使用上除了占用 CPU,也会占用较大的内存;同时算法服务不仅对调用延迟较为敏感,对业务的展现效果也有一定要求;为了满足服务的极致性能要求,我们通...
