云上搭建tensorflow
 社区干货
社区干货
转型,技术人绕不开的坎
加入了tensorflow开发者社区,并且在Windows和MAC上同时搭建好了开发环境,为此还专门整理了一篇博客: 。后来业务量增多,工作比较繁忙,就跑去搞业务开发了,tensorflow的事情暂时告一段落。我真正对人工智能引发思考是在今年,大概从4月份开始吧,就一直很迷茫。一方面是因为我们公司Android原生开发工作量少了很多,另一方面也是整个大环境不景气,Android不断被唱衰,具体细节可以参看我当时的博客: 。当时写那篇文章的时候比较纠结,...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
服务器配置(物理机or虚拟机or云主机)还可选择更高配些! Ok,now,有了这些前提条件,接下来开始**安装部署**我们**译点笔记应用**-所需要的**服务组件**: ## 系统环境准备**系统环境**首先,在云后台-防火墙配置好需要外网访问的端口(IP+PORT解析-公网IP或域名外网访问)。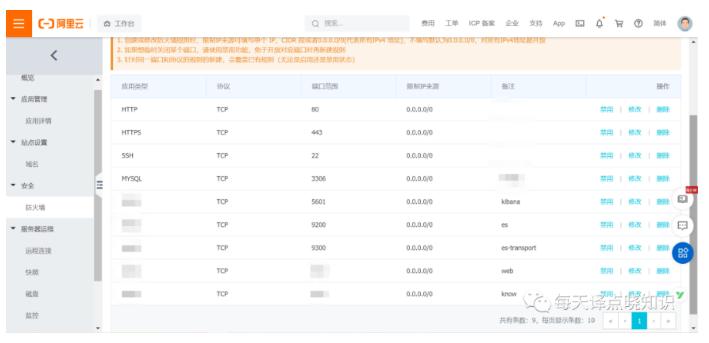 特惠活动
特惠活动
 云上搭建tensorflow-优选内容
云上搭建tensorflow-优选内容
 云上搭建tensorflow-相关内容
云上搭建tensorflow-相关内容
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
服务器配置(物理机or虚拟机or云主机)还可选择更高配些! Ok,now,有了这些前提条件,接下来开始**安装部署**我们**译点笔记应用**-所需要的**服务组件**: ## 系统环境准备**系统环境**首先,在云后台-防火墙配置好需要外网访问的端口(IP+PORT解析-公网IP或域名外网访问)。