p100和cuda7.5
 社区干货
社区干货
Linux安装CUDA
以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 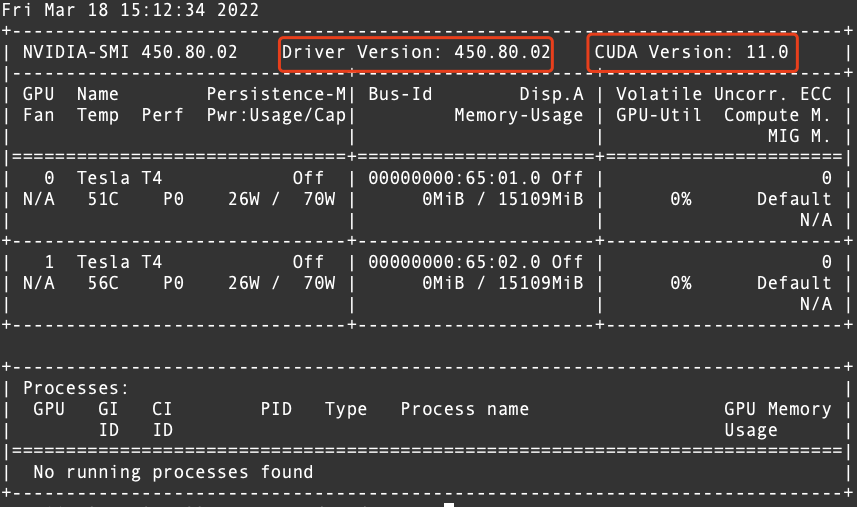 从上图中可以确认CUDA的版本... 执行`sudo sh cuda_11.0.2_450.51.05_linux.run`稍等片刻,输入 accept 回车确认。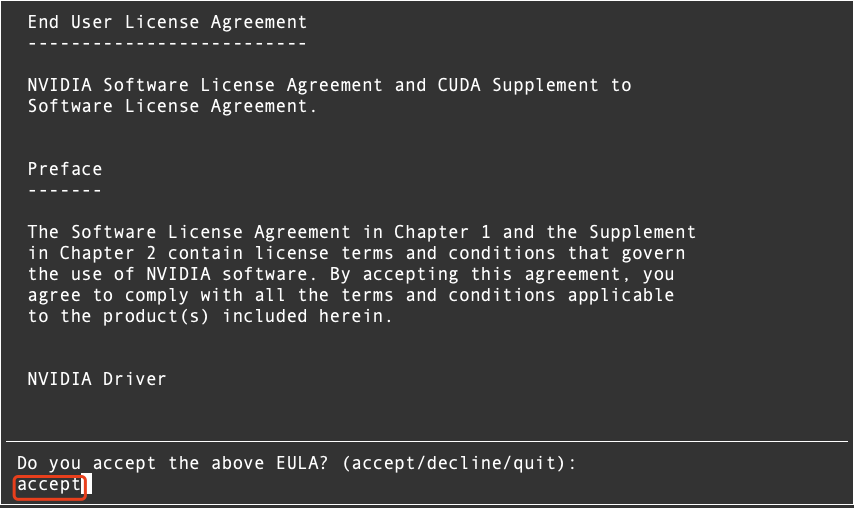7. 由于CU...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
biz=MzkyMTQyNzI4OQ==&mid=2247485568&idx=1&sn=143ac2721f1800fd0e90f735d1f93834&chksm=c18284b6f6f50da0cd5ae7c9ada6c73b9438e8cc8dc519f060c83bfac0c9548b5891a33e0273&scene=21#wechat_redirect)。本系列... 和设计细节一样,编译器对于终端使用来说也是不透明的。大多数 ASIC 都很难支持开发者像优化 CUDA Kernel 一样优化 ASIC 上运行的 AI 模型性能,往往只能做的很有限。 **0****3** **...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
7d78e33a951d86~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714666836&x-signature=9joRUk%2FeAUTnnrZZzSWNphaO5eM%3D)除了参数量巨大的模型外,大模型还可以指包含了大量数据和算法的模型库,例如... device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)for epoch in range(10): train_loss = train(model, train_loader, criterion, optimizer) test_loss, test_...
火山引擎部署ChatGLM-6B实战指导
5mQiINx%2Btc%3D)2. 在实例类型中,选择GPU计算型,可以看到有A30、A10、V100等GPU显卡的ECS云主机,操作系统镜像选择Ubuntu 带GPU驱动的镜像,火山引擎默认提供的GPU驱动版本为CUDA11.3,如果需要升级版本的话可以参... =&rk3s=8031ce6d&x-expires=1714666880&x-signature=lP8Bq7lhjg%2BgCPk8zOVk3sXNleI%3D)3. 网际快车服务创建完成后在服务列表界面可以看创建好的服务名称,以及分配到的加速IP地址和加速的端口号3128,接下来只需...
 特惠活动
特惠活动
 p100和cuda7.5-优选内容
p100和cuda7.5-优选内容
 p100和cuda7.5-相关内容
p100和cuda7.5-相关内容
通过工作流串联训练与评测任务
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])batch_size = 4classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')class Net(nn.Module): ... args = parser.parse_args() device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') print(f"use device={device}, local_rank={args.local_rank}") if args.local_rank >= 0: ...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
biz=MzkyMTQyNzI4OQ==&mid=2247485568&idx=1&sn=143ac2721f1800fd0e90f735d1f93834&chksm=c18284b6f6f50da0cd5ae7c9ada6c73b9438e8cc8dc519f060c83bfac0c9548b5891a33e0273&scene=21#wechat_redirect)。本系列... 和设计细节一样,编译器对于终端使用来说也是不透明的。大多数 ASIC 都很难支持开发者像优化 CUDA Kernel 一样优化 ASIC 上运行的 AI 模型性能,往往只能做的很有限。 **0****3** **...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
7d78e33a951d86~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714666836&x-signature=9joRUk%2FeAUTnnrZZzSWNphaO5eM%3D)除了参数量巨大的模型外,大模型还可以指包含了大量数据和算法的模型库,例如... device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)for epoch in range(10): train_loss = train(model, train_loader, criterion, optimizer) test_loss, test_...
火山引擎部署ChatGLM-6B实战指导
5mQiINx%2Btc%3D)2. 在实例类型中,选择GPU计算型,可以看到有A30、A10、V100等GPU显卡的ECS云主机,操作系统镜像选择Ubuntu 带GPU驱动的镜像,火山引擎默认提供的GPU驱动版本为CUDA11.3,如果需要升级版本的话可以参... =&rk3s=8031ce6d&x-expires=1714666880&x-signature=lP8Bq7lhjg%2BgCPk8zOVk3sXNleI%3D)3. 网际快车服务创建完成后在服务列表界面可以看创建好的服务名称,以及分配到的加速IP地址和加速的端口号3128,接下来只需...
GPU实例部署paddlepaddle-gpu环境
本文介绍 GPU 实例部署深度学习Paddle环境。 前言 在ECS GPU实例上部署深度学习Paddle环境。 关于实验 预计实验时间:20分钟级别:初级相关产品:ECS受众: 通用 环境说明 本文测试规格如下:实例规格:ecs.pni2.3xlargeGPU 类型:Tesla A100 80G显存容量:81920MiB实例镜像:velinux - 1.0 with GPU DriverNVIDIA-SMI:470.57.02NVIDIA Driver version:470.57.02CUDA version:11.4CUDA Toolkit version:11.2Python version:Python 3.7.3pa...
GPU推理服务性能优化之路
比如CPU与GPU分离,TensorRT开启半精度优化,同模型混合部署,GPU数据传输与推理并行等。下面从理论,框架与工具,实战优化技巧三个方面介绍下推理服务性能优化的方法。# 二、理论篇## 2.1 CUDA架构## 二、优化方向解析我的项目具体实现是致力于解决在文生成图任务中,模型规模庞大导致的高存储需求和计算开销大的问题。具... os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"os.environ["CUDA_VISIBLE_DEVICES"] = "-1"async def generate_image_async(args): if args.mixed_precision: print("Using mixed precision.")...
