最新cuda中文文档
 社区干货
社区干货
nvidia-cuda镜像
## 简介 CUDA-X AI 是软件加速库的集合,这些库建立在 CUDA® (NVIDIA 的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算 (HPC) 必不可少的优化功能。 下载地址: - 火山引擎访问地址:https://mirrors.ivolces.com/nvidia_all/ - 公网访问地址:https://mirrors.volces.com/nvidia_all/ ## 相关链接 官方主�
Linux安装CUDA
# 运行环境 * CentOS * RHEL * Ubuntu * OpenSUSE # 问题描述 初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。 # 解决方案 1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 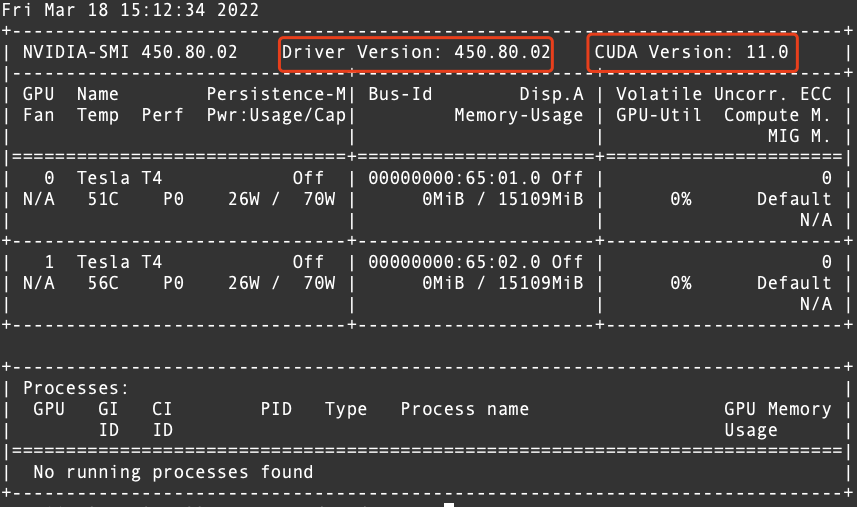 从上�
GPU推理服务性能优化之路
# 一、背景 随着CV算法在业务场景中使用越来越多,给我们带来了新的挑战,需要提升Python推理服务的性能以降低生产环境成本。为此我们深入去研究Python GPU推理服务的工作原理,推理模型优化的方法。最终通过两项关键的技术: 1.Python的GPU与CPU进程分离,2.使用TensorRT对模型进行加速,使得线上大部分�
【高效视频处理】体验火山引擎多媒体处理框架 BMF |社区征文

BMF访问链接:
 特惠活动
特惠活动
 最新cuda中文文档-优选内容
最新cuda中文文档-优选内容
 最新cuda中文文档-相关内容
最新cuda中文文档-相关内容
【高效视频处理】体验火山引擎多媒体处理框架 BMF |社区征文
解决方法:通过查阅 BMF 的官方文档和社区,我了解到可以使用虚拟环境来隔离项目的依赖。我创建了一个独立的虚拟环境,并在其中安装了与 BMF 兼容的依赖库版本,成功解决了版本冲突的问题。- CUDA 和 cuDNN 版本匹... 文档和示例代码,方便开发人员更深入地理解框架的使用方式。# 运行 BMF 的体验与反馈在运行 BMF 的过程中,我深入体验了框架的优势与不足。以下是我的详细体验与反馈,同时结合代码分析。## 优势- 跨语言接...
GPU-部署基于DeepSpeed-Chat的行业大模型
高效的训练:通过使用最新技术,如ZeRO和LoRA等技术改善训练过程,让训练过程更高效。 推理API:提供易于使用的推理API,方便进行对话式的交互测试。 模型微调 模型微调是一种迁移学习技术,通过在预训练模型的基础上进... 软件要求CUDA:使GPU能够解决复杂计算问题的计算平台。本文以11.4.152为例。 Python:编程语言,并提供机器学习库Numpy等。本文以3.8.10为例。 DeepSpeed:大模型训练工具。本文以0.10.2为例。 Tensorboard:机器学习实...
NVIDIA驱动安装指引
建议您安装最新版本的驱动: 驱动类型 驱动介绍 收费情况 Tesla驱动 用于驱动物理GPU卡,即调用GPU云服务器上的GPU卡获得通用计算能力,适用于深度学习、推理、AI等场景。您可以配合CUDA、cuDNN库更高效的使用GPU卡。... 重新安装GPU驱动和安装CUDA工具包。 公共镜像名称 适用规格族 GPU驱动版本(默认安装) CUDA版本(默认安装) Windows Server 2019 数据中心版 64位中文版 (GPU) GPU计算型 Tesla 470.129.06 11.2 Windows Server 20...
ModifyCenBandwidthPackageAttributes
数字或中文开头,可包含字母、数字、中文和以下特殊字符:点号 (.) 、下划线 (_) 和中划线 (-) 。 长度限制为1 ~ 128个字符。 不更改该参数时,保持原有名称。 Description String 否 namedesc 带宽包的描述。 必... 公共错误码请参见公共错误码文档。 HttpCode 错误码 错误信息 描述 400 InvalidName.Malformed The specified name is malformed. Ensure the maximum length of name is 128. 指定的名称格式不合法,名称长度不能超...
如何对 Linux 操作系统的 GPU 实例进行压测?
# 问题描述Linux 操作系统的 GPU 实例如何进行压力测试以及性能测试?# 问题分析GPU_BURN 是一款开源的软件,可以对 GPU 进行压力测试。GPU 性能测试使用 CUDA sample 自带的 deviceQuery、bandwith 稳定性测试以及性能测试。# 解决方案所有的测试均需要在 GPU 实例上面安装相对应的 cuda 版本,具体请参考如下步骤。## GPU_BURN### 安装GPU_BURN1. GPU_BURN下载以及使用方法参考文档[GPU_BURN下载以及使用方法](http://w...
新功能发布记录
本文为您介绍容器服务相关功能的最新动态。新特性将在各个地域陆续发布,欢迎体验。 说明 发布地域 用于记录该功能首次发布时开放的地域。新增支持地域时,历史功能的地域信息不做修改,其当前实际支持的地域以控制台显示为准。 邀测 功能正式对外开放后,该功能的历史邀测记录不做修改。该功能迭代信息,以最近发布的相关记录为准。 2024年04月功能名称 功能描述 发布地域 发布时间 相关文档 节点池对接 ESI 【邀测·申请试用】节点...
高效视频处理框架 BMF 实践|社区征文
中间框架层提供了各语言基础能力封装,框架的图/管道调度、跨数据类型和跨设备数据传输后端,以及常用的跨设备格式化、色彩空间转换、张量算子等sdk,接口层提供了多语言的API接口。本文基于docker跑通了bmf框架,实践了解码和合成功能。## 1、环境搭建日常工作使用的是Inter芯片的Mac本,基于docker环境搭建了bmf环境。bmf提供的docker镜像基于ubuntu 20.04,它包含了运行BMF CPU和GPU的完整环境依赖:Cuda11.8, Pytorch 2.0, T...
如何在Docker容器中使用GPU资源
# 问题描述在安装了 Nvidia 驱动和 docker 的主机上直接启动容器报错提示如下信息:```shelldocker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smidocker: Error response from daemon: could not sele... # 参考文档[https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#installing-on-centos-7-8](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-g...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
# 前言大语言模型(LLM,Large Language Model)是针对语言进行训练处理的大模型,建立在Transformer架构基础上的语言模型,大语言模型主要分为三类:编码器-解码器(Encoder-Decoder)模型、只采用编码器(Encoder-Only)模... 如文本文档、网页内容、数据库等。然后需要对数据进行清洗,去除噪音、标准化格式、处理缺失值等。可能遇到的瓶颈问题:数据获取困难:可以通过使用网络爬虫、API 接口、公开数据集等方式来获取数据。此外,还可以与...
