优达cuda
 社区干货
社区干货
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 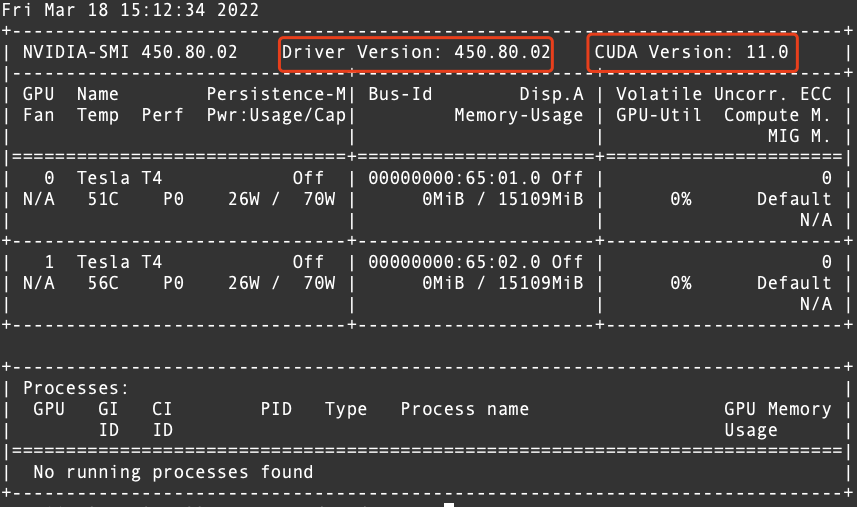 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
nvidia-cuda镜像
## 简介CUDA-X AI 是软件加速库的集合,这些库建立在 CUDA® (NVIDIA 的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算 (HPC) 必不可少的优化功能。下载地址:- 火山引擎访问地址:https://mirrors.ivolces.com/nvidia_all/- 公网访问地址:https://mirrors.volces.com/nvidia_all/## 相关链接官方主页:[https://www.nvidia.cn/technologies/cuda-x/](https://www.nvidia.cn/technologies/cuda-x/?spm=a...
GPU推理服务性能优化之路
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA ...
大模型:深度学习之旅与未来趋势|社区征文
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") input_tensors = input_tensors.to(device) model.to(device) with torch.no_grad(): outputs = model(input_tensors) predictions = torch.argmax(outputs.logits, dim=2).squeeze().tolist() # 解码预测结果 tokens = tokenizer.convert_ids_to_tokens(input_ids) labels = [tokenizer.decode([pred]) ...
 特惠活动
特惠活动
 优达cuda-优选内容
优达cuda-优选内容
 优达cuda-相关内容
优达cuda-相关内容
nvidia-cuda镜像
## 简介CUDA-X AI 是软件加速库的集合,这些库建立在 CUDA® (NVIDIA 的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算 (HPC) 必不可少的优化功能。下载地址:- 火山引擎访问地址:https://mirrors.ivolces.com/nvidia_all/- 公网访问地址:https://mirrors.volces.com/nvidia_all/## 相关链接官方主页:[https://www.nvidia.cn/technologies/cuda-x/](https://www.nvidia.cn/technologies/cuda-x/?spm=a...
GPU实例部署paddlepaddle-gpu环境
本文介绍 GPU 实例部署深度学习Paddle环境。 前言 在ECS GPU实例上部署深度学习Paddle环境。 关于实验 预计实验时间:20分钟级别:初级相关产品:ECS受众: 通用 环境说明 本文测试规格如下:实例规格:ecs.pni2.3xlargeGPU 类型:Tesla A100 80G显存容量:81920MiB实例镜像:velinux - 1.0 with GPU DriverNVIDIA-SMI:470.57.02NVIDIA Driver version:470.57.02CUDA version:11.4CUDA Toolkit version:11.2Python version:Python 3.7.3pa...
GPU推理服务性能优化之路
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA ...
卸载NVIDIA Tesla驱动
卸载NVIDIA Tesla驱动(Linux)注意事项卸载GPU驱动需要root账号操作权限,如果您是普通用户,请使用sudo命令获取root权限后再操作,本文以root登录系统操作为例。 卸载不同CUDA版本的命令可能不同,若不存在cuda-uninstaller文件, 请进入“/usr/local/cuda/bin/”目录查看是否存在uninstall_cuda开头的文件。若有,请将命令中的cuda-uninstaller替换为uninstall_cuda开头的文件名。 卸载run包方式安装的NVIDIA驱动登录Linux实例。 执...
新功能发布记录
对业务侧使用的 CUDA 等软件不同版本进行适配。 华北 2 (北京) 2024-01-31 自定义 GPU 驱动安装说明 华南 1 (广州) 2024-01-30 华东 2 (上海) 2024-01-30 AIOps 套件支持生成和下载巡检/故障诊断报告 【邀测·申请试用】在集群巡检/故障诊断的报告详情中增加下载报告的功能。方便多方介入排障时,共享下载的集群巡检和故障诊断报告,协作排障。 华北 2 (北京) 2024-01-31 配置集群巡检 华南 1 (广州) 2024-01-30 华东 2 (上海) 202...
大模型:深度学习之旅与未来趋势|社区征文
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") input_tensors = input_tensors.to(device) model.to(device) with torch.no_grad(): outputs = model(input_tensors) predictions = torch.argmax(outputs.logits, dim=2).squeeze().tolist() # 解码预测结果 tokens = tokenizer.convert_ids_to_tokens(input_ids) labels = [tokenizer.decode([pred]) ...
预置镜像列表
机器学习开发中镜像用于提供开发所需的运行环境,机器学习平台为用户提供了包括 Python、CUDA、PyTorch、TensorFlow、BytePS 等多种依赖的预置镜像供用户直接使用。 相关概念 镜像 预置镜像列表 PythonPython 是目前机器学习研究和开发中最常用的编程语言之一,该语言可读性强且拥有丰富的软件库(如 scikit-learn、numpy 等)。平台基于原版 Ubuntu 镜像安装了不同版本的 Miniconda Python(3.7+),内置了常用开发工具,同时 pip、cond...
从构建到落地,火山方舟助力大模型生态持续繁荣
双方还联合开源了高性能图像处理加速库CV-CUDA,并在大规模稳定训练、多模型混合部署等方面的技术合作上取得成效。未来NVIDIA和火山引擎团队将继续深化合作,包含在NVIDIA Hopper架构进行适配与优化、机密计算、重点模型合作优化、共同为重点客户提供支持,以及NeMo Framework适配等,携手助力大模型产业繁荣。 智谱AI张鹏:认知大模型及应用用好大模型的前提,是对大模型拥有清晰认知。智谱AI CEO张鹏回顾了智谱AI的发展轨迹,并将始终...
GPU-部署ChatGLM-6B模型
需保证CUDA版本 ≥ 11.4。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以535.86.10为例。 CUDA:使GPU能够解决复杂计算问题的计算平台。本文以CUDA 12.2为例。 CUDNN:深度神经网络库,用于实现高性能GPU加速。本文以8.5.0.96为例。 运行环境:Transformers:一种神经网络架构,用于语言建模、文本生成和机器翻译等任务。本文以4.30.2为例。 Pytorch:开源的Python机器学习库,实现强大的GPU加速的同时还支持动态神经网络。本...
