apache服务器内存高
 社区干货
社区干货
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
由轻量级的 serverless 计算框架 Pulsar Functions 实现流原生的数据处理。 - 基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar。 - 分层式存储可在数据... 消费者将在内存缓存所有的块消息,直到收到所有的消息块。将这些消息合并成为原始的消息 M1,发送给处理进程。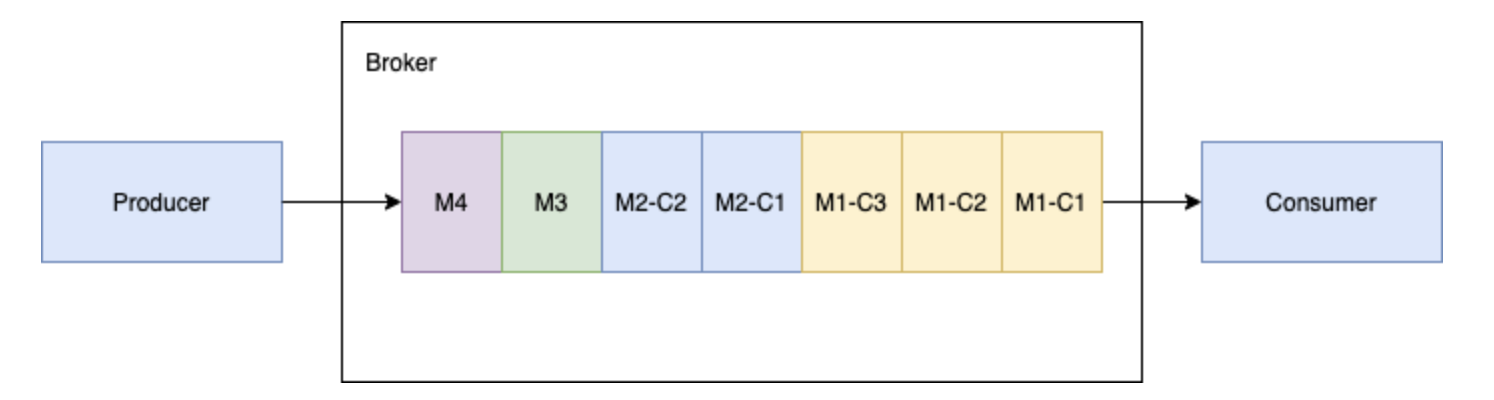##### 3...
ApacheCon - 云原生大数据上的 Apache 项目实践
Apache 软件基金会的官方全球系列大会 CommunityOverCode Asia(原 ApacheCon Asia)首次中国线下峰会将于 2023 年 8 月 18-20 日在北京丽亭华苑酒店举办,大会含 17 个论坛方向、上百个前沿议题。字节跳动云原生计... 主要负责 Serverless Flink 等方向研发;闵中元,于 2021 年加入字节跳动,就职于基础架构开放平台团队,主要负责 Serverless Flink ,Flink OLAP 等方向研发。 **专题:人工智能/机器学习** ...
ApacheCon - 云原生大数据上的 Apache 项目实践
Apache 软件基金会的官方全球系列大会 CommunityOverCode Asia(原 ApacheCon Asia)首次中国线下峰会将于 2023 年 8 月 18-20 日在北京丽亭华苑酒店举办,大会含 17 个论坛方向、上百个前沿议题。字节跳动云原生计... 主要负责 Serverless Flink 等方向研发;闵中元,于 2021 年加入字节跳动,就职于基础架构开放平台团队,主要负责 Serverless Flink ,Flink OLAP 等方向研发。 ### 专题:人工智能 / 机器学习#### 字节跳动深...
揭秘字节跳动对 Apache Doris 数据湖联邦分析的升级和优化
本文主要介绍 Apache Doris 设计和开发数据湖联邦分析特性的思考和实践。 全文分为三部分,首先介绍数据湖相关技术的演进,其次介绍 Apache Doris 数据湖联邦分析的整体设计和相关特性,最后介绍 Apache Doris 在数... 会分别连接到外部的 JDBC Server 和 ES Server 来进行元数据获取。  特惠活动
特惠活动
 apache服务器内存高-优选内容
apache服务器内存高-优选内容
 apache服务器内存高-相关内容
apache服务器内存高-相关内容
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
其次介绍 Apache Doris 数据湖联邦分析的整体设计和相关特性,最后介绍 Apache Doris 在数据湖联邦分析上的未来规划。# 1. 湖仓一体架构演进回顾湖仓一体的发展史,主要经历了三个阶段。第一个阶段是数据仓库,第... 会分别连接到外部的 JDBC Server 和 ES Server 来进行元数据获取。提交 spark 作业。Spark 作业以 cluster 模式运行,即 spark context 运行在 cluster 内,而非 livy server 中,之后 Livy 以 session 来管理这些 spark 作业。 2 Livy 入门2.1 Rest APISession 是 Livy 中一个非常重要的概念...
Kafka 消息传递详细研究及代码实现|社区征文
## 背景新项目涉及大数据方面。之前接触微服务较多,趁公司没反应过来,赶紧查漏补缺。Kafka 是其中之一。Apache Kafka 是一个开源的分布式事件流平台,可跨多台计算机读取、写入、存储和处理事件,并有发布和订阅事件流的特性。本文将研究 Kafka 从生产、存储到消费消息的详细过程。 ## Producer### 消息发送所有的 Kafka 服务器节点任何时间都能响应是否可用、是否 topic 中的 partition leader,这样生产者就能发送它的...
干货 I 字节跳动基于 Apache Hudi 的数据湖实战解析
Apache HUDI 作为数据湖框架的一种开源实现,提供了事务、高效的更新和删除、高级索引、 流式集成、小文件合并、log文件合并优化和并发支持等多种能力,支持实时消费增量数据、离线批量更新数据,并且可通过 Spark、F... Apache Hudi 仅支持单表的元数据管理,缺乏统一的全局视图,会存在数据孤岛。Hudi 选择通过同步分区、表信息到 Hive Metastore Server 的方式,提供全局的元数据访问。但是,两个系统之间的同步无法保证原子性,会有一致...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
高容错性与复杂性隔离上,主要包含以下三方面: **●** **职责边界清晰** :流处理专注于增量数据计算,批处理专注于全量数据计算;**●** **容错性** :批处理 T+1 全量计算的结果会覆盖流处理的结... **●** Block:Table Server 中的一块内存空间。对于主键表,会按照主键基于时间戳做排序后合并 Flush 成 Hudi 的 log file;对于非主键表,会按照 offset 有序进行 Flush;**●** WAL Log:Block 对应的持久化存储...
干货 I 字节跳动基于 Apache Hudi 的数据湖实战解析
Apache HUDI 作为数据湖框架的一种开源实现,提供了事务、高效的更新和删除、高级索引、 流式集成、小文件合并、log文件合并优化和并发支持等多种能力,支持实时消费增量数据、离线批量更新数据,并且可通过 Spark、F... Apache Hudi 仅支持单表的元数据管理,缺乏统一的全局视图,会存在数据孤岛。Hudi 选择通过同步分区、表信息到 Hive Metastore Server 的方式,提供全局的元数据访问。但是,两个系统之间的同步无法保证原子性,会有一致...
深度剖析 Apache EventMesh 云原生分布式事件驱动架构 |社区征文
## 一、前言近年来,随着微服务、云原生和 Serverless 概念的普及以及容器化技术的发展,事件驱动也再次成为热点,引起 IT 界广泛的关注。事件驱动架构是一种用于设计应用的软件架构和模型。对于事件驱动系统而言,事件的捕获、通信、处理和持久保留是解决方案的核心结构。事件驱动架构可以最大程度减少耦合度,很好地扩展与适配不同类型的服务组件,因此是现代化分布式应用架构的理想之选。本文会从以下几个方面来剖析 Apache Even...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
切记安全-开启服务器的防火墙systemctl start firewalld.service```## ElasticSearch分布式全文搜索引擎****描述:基于Lucene搜索服务器,提供了一个分布式多用户能力的全文搜索引擎,基于RESTful Web接口,基于Java语言开发,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎,能够达到实时搜索,稳定,可靠,快速,安装使用方便。****```温馨提示:为了保证正确安装和运行,如果可用内存过少,可能导致ES安装或启...
