数据仓库etl案例
 社区干货
社区干货
ELT in ByteHouse 实践与展望
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数... server是多实例,每个server实例中都有queue,所持有的是一个局部视角,缺乏全局的资源视角。除此之外,每个queue中的查询状态没有持久化,只是简单的缓存在内存中。后续,我们会增加server之间的协调,在一个全局的视角...
ByConity 技术详解之 ELT
谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用Extract-Transform-Load ... server是多实例,每个server实例中都有queue,所持有的是一个局部视角,缺乏全局的资源视角。除此之外,每个queue中的查询状态没有持久化,只是简单的缓存在内存中。后续,我们会增加server之间的协调,在一个全局的视角...
干货|从ETL到ELT,揭秘火山引擎ByteHouse的技术实现
[picture.image](https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/2566e761f27c4ea89f21916921641761~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1715185247&x-signature=Od9bzfW%2BehtiPo9NBOlPYLJFZwg%3D) 谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT) 将来源不同、格式各异的数据提取到数据仓库中。 作为云原生数据仓库, ...
如何快速从 ETL 到 ELT?火山引擎 ByteHouse 做了这三件事
这些数据系统大多采用以行为主的存储结构,比如支付交易记录、用户购买行为、传感器报警等。在数仓及分析领域,海量数据则主要采按列的方式储存。因此,将数据从行级转换成列级存储是建立企业数仓的基础能力。 传统方式是采用 Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的 ETL 系统,因而维护成本较高。但随着云计算时代的到来,云数据仓库具备更强扩展性和计算能力,也要求改...
 特惠活动
特惠活动
 数据仓库etl案例-优选内容
数据仓库etl案例-优选内容
 数据仓库etl案例-相关内容
数据仓库etl案例-相关内容
干货 | ELT in ByteHouse 实践与展望
谈到数据仓库, 一定离不开使用 **Extract-Transform-Load (ETL)**或 **Extract-Load-Transform (ELT)**。将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。 传统的数据转换过程一般采用... server 是多实例,每个 server 实例中都有 queue,所持有的是一个局部视角,缺乏全局的资源视角。除此之外,每个 queue 中的查询状态没有持久化,只是简单的缓存在内存中。 后续,我们会增加 server 之间的协调,...
ByteHouse+Apache Airflow:高效简化数据管理流程
可扩展可靠的数据流程:Apache Airflow 提供了一个强大的平台,用于设计和编排数据流程,让您轻松处理复杂的工作流程。搭配 ByteHouse,一款云原生的数据仓库解决方案,您可以高效地存储和处理大量数据,确保可扩展性和可靠性。1. 自动化工作流管理:Airflow 的直观界面通过可视化的 DAG(有向无环图)编辑器,使得创建和调度数据工作流程变得容易。通过与 ByteHouse 集成,您可以自动化提取、转换和加载(ETL)过程,减少手动工作量,实现更...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... 专题分析需求而计算生成的数据。数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(**抽取Extra, 转化Transfer, 装载Load**)的过程,ETL是数据仓库的流水线,也可以认为是数据仓库的血液,...
基于火山引擎 EMR 构建企业级数据湖仓
对业务吸引不够:由于以上三点原因,Table Format 对业务的吸引力就大打折扣了。要怎么去解这些问题呢?现在业界已经有基于这些 Table Format 应用的经验、案例或者商业公司,比如 Data Bricks,基于 Iceberg 的 ... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
DataLeap数据仓库流程最佳实践
我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表: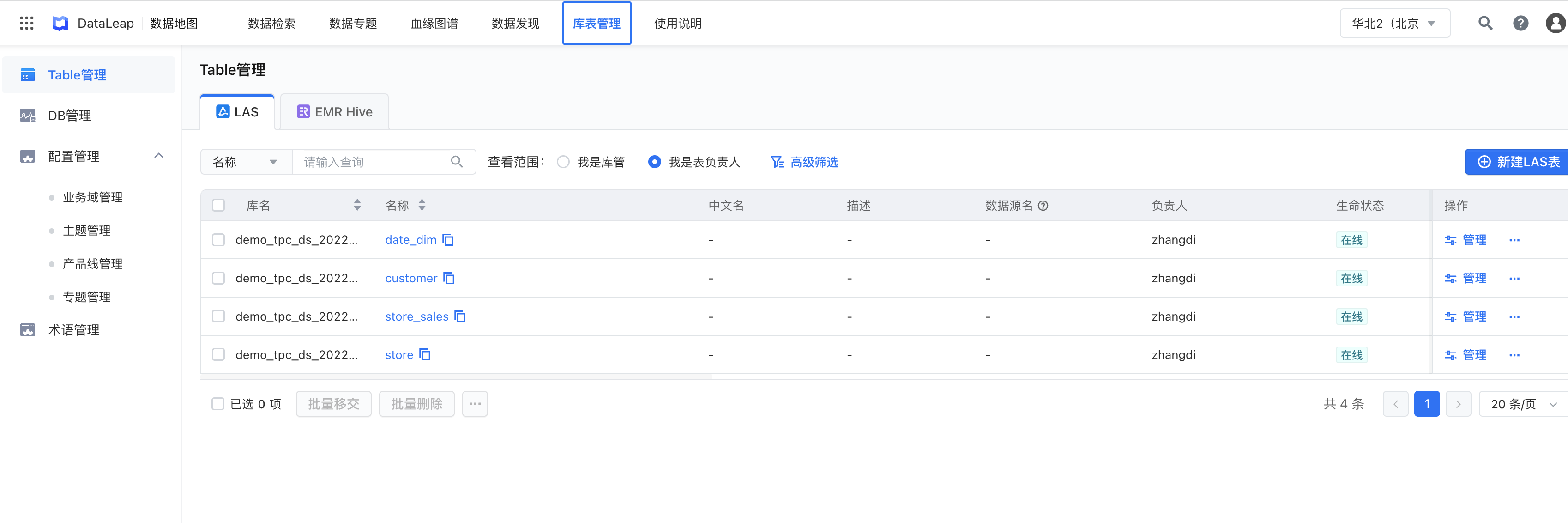本案例中库信息为:demo_tpc_ds_20...
基于Flink+Paimon的流式湖仓探索|社区征文
# 前言各位好,笔者是一名银行业的科技类员工,从2021年底开始接触实时技术,最开始实时数据加工模式是“端到端”的烟囱式开发,经过一年多的实时需求开发积累,发现存在诸多问题,比如:只支持增量计算、基础ETL操作重复... 因此项目决定搭建实时数据仓库。实时数据仓库的分层架构在设计上必须考虑到时效性问题,分层设计尽量精简,避免数据在流转过程中造成不必要的延迟响应,并降低中间流程出错的可能性。 实验说明 步骤1:创建项目 步骤2:计算资源组设置本案例以湖仓一体Las为例,这里选择已创建的湖仓一体...
基于火山引擎 EMR 构建企业级数据湖仓
保证数据并发访问安全,同时历史快照功能方便流、AI 等场景需求。* **满足多引擎访问**:能够对接 Spark 等 ETL 的场景,同时能够支持 Presto 和 channel 等交互式的场景,还要支持流 Flink 的访问能力。* **开放存... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
