数据仓库er图向多维模型
 社区干货
社区干货
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、身份验证、查询优化器,事务管理、安全管理、元数据管理,以及运维监控、数据查询等可视化操作功能。 **服务层主要包括如下组件:**- **资源管理器**资源管理器(Resource Manager)负责对计算资源进行统一的...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
图解那些OLAP分析引擎中的DBMS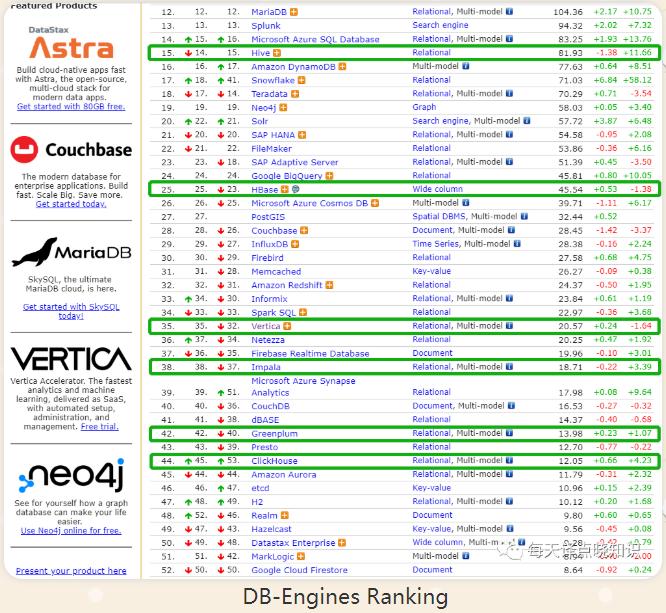## 资讯元宇宙(Metaverse),数据... 数仓多维数据模型详细设计,欢迎一起加入交流探讨,希望能给读者在实际业务场景-OLAP分析演进过程中有些不一样的IDea。 ## 场景目前数据存储的业务类型-**OLTP**,**OLAP......****1、** 其中一种是企业知识库...
ByteHouse:基于ClickHouse的实时数仓能力升级解读
ByteHouse是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。全篇将从两个版块讲解... =&rk3s=8031ce6d&x-expires=1715271701&x-signature=Hph1XGDnWerQ97YYCSNOyWn73QI%3D)实时数仓,本质上是由原来的离线数仓所衍生出来的需求。业务场景对数仓的需求,已经上升到对实时数据分析能力的增强,以及对离线...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 计算层** 和**数据存储层。** 服务接入层负责客户端数据和服务的接入,也就是 ByConity Server;ByConity 的计算资源层,由一个或者多个计算组构成,每个 Virtual Warehouse(VW)是一个计算组;数据存储层由分布式文件系...
 特惠活动
特惠活动
 数据仓库er图向多维模型-优选内容
数据仓库er图向多维模型-优选内容
 数据仓库er图向多维模型-相关内容
数据仓库er图向多维模型-相关内容
2022技术盘点之平台云原生架构演进之道|社区征文
访问控制来保证数据安全与用户隐私)以及安全监控与审计,形成事前、事中、事后的全过程防护;- 业界主流安全工具平台赋能:如:KubeLinter/Kubescape/Nessus/Sonarqube/AppScan等,严格把控平台从设计、开发、测试、部... Service 得到一个 ClusterIP(虚拟 IP 地址),并保存到集群数据仓库;4. 在集群范围内传播 Service 配置;5. 集群 DNS 服务得知该 Service 的创建,据此创建必要的 DNS A 记录。总体来说,Kubernetes的服务注册与发...
基于 ByteHouse 构建实时数仓实践
星型模型、雪花模型在内的各类模型。 ByteHouse 可以满足企业级用户的多种分析需求,包括 OLAP 多维分析、定制报表、实时数据分析和 Ad-hoc 数据分析等各种应用场景。 ### ByteHouse 优势一:实时数据高... 数据接入高吞吐性,支持了多线消费 Kafka topic 对应 Partition 的数据,满足大数据量实时数据接入的需求。1. 数据接入高可靠性,通过 Zookeeper 来实现主备消费节点管理,比如,当线上出现某个节点出现故障或无法提...
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
[Rancher](https://www.rancher.cn/)是一个开源的企业级多集群Kubernetes管理平台,实现了Kubernetes集群在混合云+本地数据中心的集中部署与管理,以确保集群的安全性,加速企业数字化转型。###### 中文官网首页(最新)在升级到高版本K8s集群版本之前,我们使用的都是Rancher管理工具,如下图所示。![]...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
作者|程伟,MetaAPP 大数据研发工程师【项目地址】GitHub |https://github.com/ByConity/ByConity> ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致... 我们使用 DataX 把 Kafka 的数据集成到 Hive 数仓,再生成 BI 报表。BI 报表使用了 Superset 组件来进行结果展示;在**实时场景**中,一条线使用 GoSink 进行数据集成,把 GoSink 的数据集成到 ClickHouse,另外一条线...
「火山引擎」数据中台产品双月刊 VOL.02
火山引擎数据中台产品双月刊涵盖「大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品的功能迭代、重点功能介绍、平台最新... Iceberg 升级到0.14.0;Hudi 版本升级到0.11.1;Doris 版本升级到1.1.1 第二,新增数据格式 Delta Lake 2.0- **【新增软件栈版本 EMR v2.0.0】** 采用 **Hadoop2.x** 版本序列,降低使用 Hadoop 2.x 迁移到火...
揭秘字节跳动对 Apache Doris 数据湖联邦分析的升级和优化
其次介绍 Apache Doris 数据湖联邦分析的整体设计和相关特性,最后介绍 Apache Doris 在数据湖联邦分析上的未来规划。## 1. 湖仓一体架构演进回顾湖仓一体的发展史,主要经历了三个阶段。第一个阶段是数据仓库,第二... Iceberg、DeltaLake 等表格式的定义,也支持结构化、半结构化和非结构化数据。 **● 实时数仓:** 提供实时指标的聚合,数据可以秒级入库。实时数仓的分析能力也较强,支持秒级和亚秒级的数据分析,支持多维分析和联合...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
其次介绍 Apache Doris 数据湖联邦分析的整体设计和相关特性,最后介绍 Apache Doris 在数据湖联邦分析上的未来规划。# 1. 湖仓一体架构演进回顾湖仓一体的发展史,主要经历了三个阶段。第一个阶段是数据仓库,第... Iceberg、DeltaLake 等表格式的定义,也支持结构化、半结构化和非结构化数据。 **● 实时数仓:** 提供实时指标的聚合,数据可以秒级入库。实时数仓的分析能力也较强,支持秒级和亚秒级的数据分析,支持多维分析和联合...
干货|ByteHouse:百万级TPS!看字节跳动如何基于ClickHouse落地高性能实时数仓
> yteHouse 是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。> > > > > **全... =&rk3s=8031ce6d&x-expires=1715271645&x-signature=vISMX6NERtGAJPjMbCvT6nZpkqQ%3D)面对这些需求,ByteHouse团队选择了ClickHouse作为实时数仓的承载。**时效性、数据准确、开发运维成本低,这些跟Click...
LAS Spark 在 TPC-DS 的优化揭秘
TPC-DS 是一个模拟复杂数据仓库环境的测试基准,LAS Spark 通过采用规则优化、缓存优化和运行时优化三类优化策略,实现了超越社区版本的巨大性能提升,且已在内部生产环境得到验证。**文末更有专属彩蛋,新人优惠购福利,等着你来解锁!**本篇文章提纲如下:- TPC-DS 简介- 性能表现- 自研优化策略- 总结## 1. TPC-DS 简介针对数据库不同的使用场景 TPC 组织发布了多项测试标准。TPC-DS 采用星型、雪花型等多维数...
