ods数据仓库的优点
 社区干货
社区干货
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
从源系统同步过来的数据落到ODS层,但是要注意采集数据时需要能捕获到源系统表结构的变更,可以采用Flink CDC等。ODS层的数据落到Kakfa中,设置一个较长的保存周期。kafka直接作为数仓的存储层,优点是不关心数据的格... 数据落到Kafka虽然有很多优势,但是Kafka本身不是一个数据库,不支持SQL查询,也不支持数据的索引和聚合,因此在数据分析方面的能力有限。另外Kafka是一个基于事件的系统,不同于传统的基于事实表和维度表的数据仓库建模...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
以上特点也是数据仓库的特点,所以好的数据仓库一定是耗散结构的**多层次,开放,一直被构建ing**# 三、怎么做,如何搭建数仓## 建设思路如何搭建数仓,在业界一直存在着两种思路### 从顶到下从顶到下,即从点到面,到面面俱到### 从低到上从低到上,即面面俱到,到各个击破### 数仓分层不管是哪一种,都逃脱不了以下的常用分层架构- ODS:操作型数据(Operational Data Store),指结构与源系统基本保持一致的增量或者...
浅谈数仓建设及数据治理 | 社区征文
反映历史变化的数据集合,用于支持管理决策。从定义上来看,数据仓库的关键词为面向主题、集成、稳定、反映历史变化、支持管理决策,而这些关键词的实现就体现在分层架构内。一个好的分层架构,有以下好处:1. **清... [数据分层架构](https://cdn.jsdelivr.net/gh/sunmyuan/cdn/210316_7.png)### 1. 数据层具体实现>使用四张图说明每层的具体实现- **数据源层ODS**  特惠活动
特惠活动
 ods数据仓库的优点-优选内容
ods数据仓库的优点-优选内容
 ods数据仓库的优点-相关内容
ods数据仓库的优点-相关内容
实战分享(直播&PPT)
欢迎关注【字节跳动数据平台】视频号,第一时间获取更多技术分享。以下是关于大数据、湖仓一体、数据湖、数据仓库、开源、数据中台等主题的直播与演讲 PPT 等一手材料,欢迎自取与观看: 【Apache Hudi 中文社区技术交... 《数据湖化的新思考》《基于数据湖的样本存储与样本生成》 Hudi 中文社区技术交流会-第九期 2023.03.30《社区最新进展同步》《字节跳动基于 Hudi 的湖仓一体及应用实践》《电商流量基于 Hudi 的 ODS 落湖实践》 Hu...
创建专题设置
说明 “数据专题”以业务视角出发,将服务于同一业务场景的表归纳整理,形成数据仓库,方便使用者查询及管理。以营销场景为例,可以按照商品中心、会员中心等方向,形成对应数仓。PS:专题中,涉及到产品线、业务域、主题... 以此数据las schema库,添加 ods、dim、dwd、dwm 库。 点击确认选择,再点击确认后保存成功 可按需编辑专题调整等操作,同时支持目录刷新
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况” 经典数据仓库按照大类分为基础数据层、应用数据层。 本样例中,我们的数据仓库建设思路是: ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表) DWD(对ODS冗余表数据进行轻度过滤处理) DWM (基于DWD表与业务需求,轻度聚合最近三天的数据) APP (基于DWD或DWM,...
干货 | 这样做,能快速构建企业级数据湖仓
Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但现在,向量化是一个更好的选择,因为向量化可以一次处理一批数据,而不只是一条数据。其好处是可以充分利用 CPU 的特性,如 SIMD,Pipeline 执行等...
字节跳动基于数据湖技术的近实时场景实践
从数据研发与应用的角度,数据湖技术具有以下特点:首先,数据湖可存储海量、低加工的原始数据。在数据湖中开发成本较低,可以支持灵活的构建,构建出来的数据的复用性也比较强。其次,在存储方面,成本比较低廉,且容... Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Fli...
干货|ByteHouse:百万级TPS!看字节跳动如何基于ClickHouse落地高性能实时数仓
数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。> > > > > **全篇将从两个版块讲解 ByteHouse 的技术... 各种各样的数据源都可以通过Kafka或者Flink写入到ByteHouse里面,然后来对接上层的应用。按照数仓分层角度,Kafka、Flink可以理解为ODS层,那ByteHouse就可以理解为DWD和DWS层。如果说有聚合或者预计算的场景,也...
基于火山引擎 EMR 构建企业级数据湖仓
都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但是现在人们发现可能向量化是一个更好的选择,向量化可以一次处理一批数据,而不只是一条数据。其好处是可以充分利用 CPU 的一些特性,比如 SIMD,Pipeline 执行等。### *...
迁移指南说明
内容包括: 数据迁移、作业迁移、元数据迁移 成本评估和优化建议 1 准备工作1.1 迁移路径在大数据开始迁移前,需要先确定迁移路径,每个路径都有其优点和缺点,您可以结合实际业务场景进行选择: 架构重构 迁移源端 H... 数据存储格式。 网络吞吐量。 大数据组件的参数设置。 作业信息。 至少一周的资源使用情况。 ODS/DWD/DWS/DIM/ADS 数据分层、流转图。 3 后续步骤准备工作和信息指标信息采集完成后,您便可开始后续的成本评估...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
兼顾数据仓库,具有实时,批处理,多并发等优点。**Java接入:** 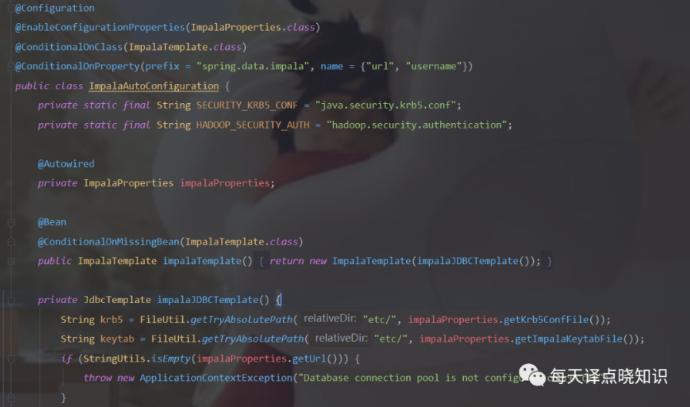 在阐述Vertica(简称V)、 ClickHouse(简称C)、Greenplum(简称G)这三款MPP之前,我们不妨以北京...
