数据仓库的逻辑模型通常采用
 社区干货
社区干货
浅谈数仓建设及数据治理 | 社区征文
每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。数据仓库之父 Bill Inmon对数据仓库做了定义——面向主题的、集成的... 数据仓库模型的建设方法和业务系统的企业数据模型类似。在业务系统中,企业数据模型决定了数据的来源,而企业数据模型也分为两个层次,即主题域模型和逻辑模型。同样,主题域模型可以看成是业务模型的概念模型,而逻辑模...
ELT in ByteHouse 实践与展望
格式各异的数据提取到数据仓库中,并进行处理加工。 传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。... 因此会在数据分析的某一阶段,从整体链路中将数据导出,做一些不同于主链路的ETL操作,会出现两份数据存储。其次在这过程中也会出现两套不同的ETL逻辑。当数据量变大,计算冗余以及存储冗余所带来的成本压力也会愈发...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHous... 多租户管理:支持多租户模型,租户间互相隔离,独立计费。- RBAC 权限管理:支持库、表、列级,读、写、资源管理等权限。通过角色进行管理。- VW 自动启停,弹性扩展:计算资源按需分配,闲时关闭。降低总成本,提...
ByConity 技术详解之 ELT
格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。ByCon... 因此会在数据分析的某一阶段,从整体链路中将数据导出,做一些不同于主链路的ETL操作,会出现两份数据存储。其次在这过程中也会出现两套不同的ETL逻辑。当数据量变大,计算冗余以及存储冗余所带来的成本压力也会愈发...
 特惠活动
特惠活动
 数据仓库的逻辑模型通常采用-优选内容
数据仓库的逻辑模型通常采用-优选内容
 数据仓库的逻辑模型通常采用-相关内容
数据仓库的逻辑模型通常采用-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎... 生成逻辑执行计划,优化执行计划,调度和执行 query,并将最终结果返回给用户。服务节点是无状态的,意味着用户可以接入任意一个服务节点(当然如果有需要,也可以隔离开),并且可以水平扩展,意味着平台具备支持高并发查...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 通常来说,事实常以数值形式出现,而且一般都被大量文本形式的上下文包围着。这些文本形式的上下文描述了事实的“ 5个W ”( When 、 Where 、 What 、 Who 、 Why )信息,通常可被直观地分割为独立的逻辑块,每一个独...
观点|SparkSQL在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台EMR团队EMR 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技... 一个企业数仓的整体逻辑如上图所示,数仓在构建的时候通常需要ETL处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种ETL处理成为DWD层,再基于DWD层设计上层的数据模型层,形成DM,中间会有DWB/DWS作为部...
SparkSQL 在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有... 一个企业数仓的整体逻辑如上图所示,数仓在构建的时候通常需要ETL处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种ETL处理成为DWD层,再基于DWD层设计上层的数据模型层,形成DM,中间会有DWB/DWS作为部...
干货 | 看 SparkSQL 如何支撑企业级数仓
本文作者:惊帆 来自于数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDB... 一个企业数仓的整体逻辑如上图所示,数仓在构建的时候通常需要 ETL 处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种 ETL 处理成为 DWD 层,再基于 DWD 层设计上层的数据模型层,形成 DM,中间会有 DWB...
2022技术盘点之平台云原生架构演进之道|社区征文
逻辑数据加密及各云基础设施高可用部署,同时进行业务数据备份恢复和安全审计;- 系统层:通过对云服务器进行系统安全加固,漏洞补丁管理,云主机安全和云防火墙,确保系统安全。## 三 DevOpsSmartOps平台从DevOps到SecDevOps的演进之路。### 3.1 DevOps V1.0起初DevOps使用Gitlab CI进行管控。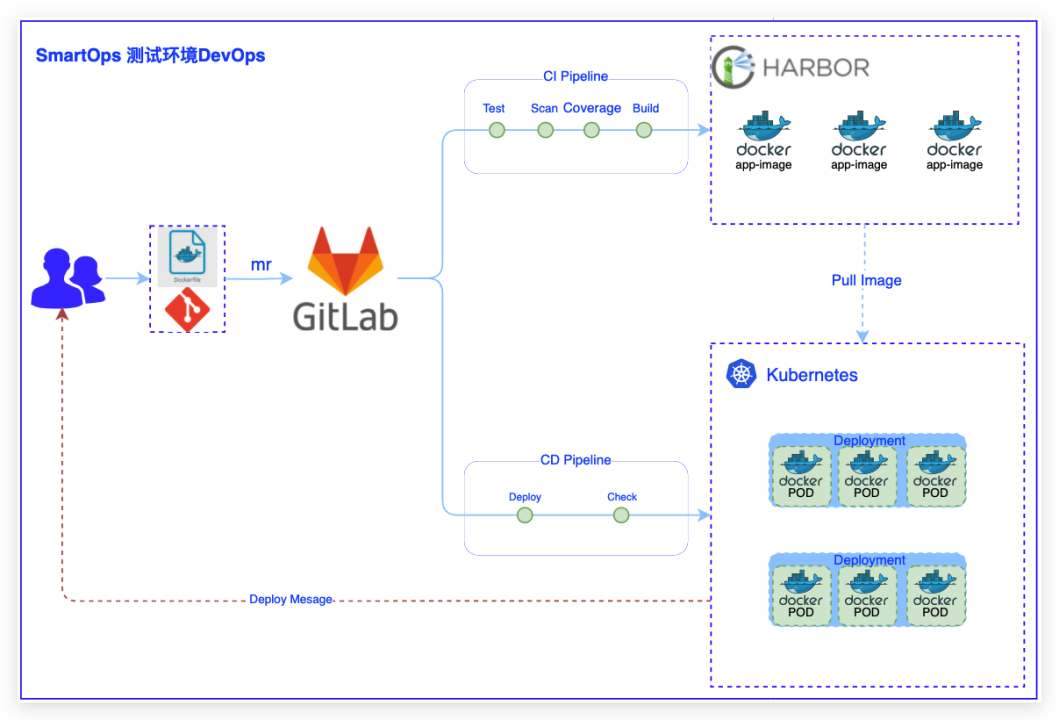- CI/CD:各业务代码仓库保...
干货 | ELT in ByteHouse 实践与展望
格式各异的数据提取到数据仓库中,并进行处理加工。 传统的数据转换过程一般采用 **Extract-Transform-Load (ETL)** 来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的 ETL 系统,因而... 因此会在数据分析的某一阶段,从整体链路中将数据导出,做一些不同于主链路的 ETL 操作,会出现两份数据存储。其次在这过程中也会出现两套不同的 ETL 逻辑。 当数据量变大,计算冗余以及存储冗余所带来的成本压...
火山引擎ByteHouse:4000字总结,Serverless在OLAP领域应用的五点思考
作为一款火山引擎推出的云原生数据仓库,ByteHouse基于开源ClickHouse构建,并在字节跳动内外部场景的检验下,对OLAP引擎能力、性能、运维、架构进一步升级。除此之外,ByteHouse也在Serverless方向探索,基于cloud-nat... 计算侧通常还是采用经典的shared-nothing架构,具备良好的水平伸缩扩展性,但是计算侧的无状态化程度直接关系到弹性能力的优劣,这其中元数据的管理和同步、统计信息的自动化、优化器的智能化都是关键的技术难点。形...
干货 | 这样做,能快速构建企业级数据湖仓
这种数据格式有三个实现: **Delta Lake** 、 **Iceberg** 和 **Hudi** 。三种格式的出发点略有不同,但是场景需求里都包含了事务支持和流式支持。在具体实现中,三种格式也采用了相似做法,即在数据湖的存储之上定... Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走...
