数据仓库的ods是什么
 社区干货
社区干货
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
从源系统同步过来的数据落到ODS层,但是要注意采集数据时需要能捕获到源系统表结构的变更,可以采用Flink CDC等。ODS层的数据落到Kakfa中,设置一个较长的保存周期。kafka直接作为数仓的存储层,优点是不关心数据的格... 但是Kafka本身不是一个数据库,不支持SQL查询,也不支持数据的索引和聚合,因此在数据分析方面的能力有限。另外Kafka是一个基于事件的系统,不同于传统的基于事实表和维度表的数据仓库建模方式,因此需要对数据的建模和...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效和精准的决策**第一个视角是从业务视角出发,我们可以提炼为三个字为**管**,**产**,**运**1、管是管理,即让管理层进行科学决策【不再是屁股决定脑袋的决策】2、产是产品,即让产品流程优化,快速迭代【不再自嗨...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。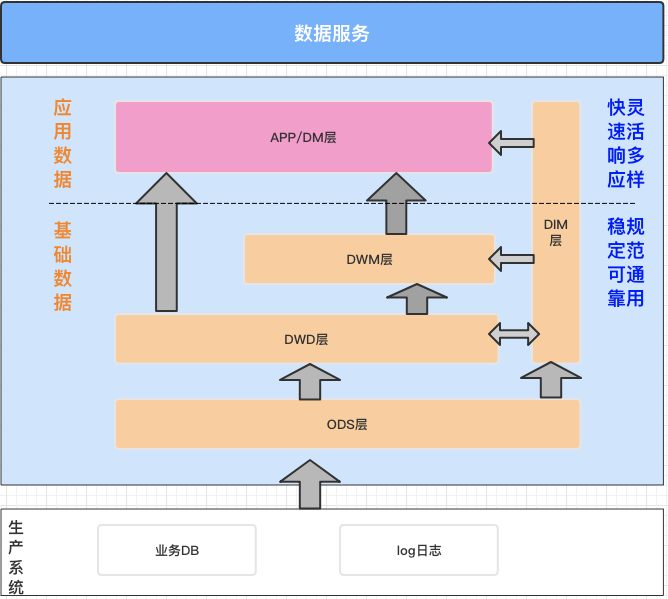本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
Apache Iceberg 中引入索引提升查询性能
Iceberg 等大数据生态组件,100% 开源兼容,可以帮助企业快速构建企业级大数据平台,降低运维门槛。秉承业界领先的 EMR Stateless 理念,火山引擎 EMR 可以实现集群级别的弹性伸缩,即无业务需求时释放集群,有业务需求时再拉起集群,配合智能化的冷热数据分层存储能力,助力企业在大数据基建领域进一步降本提效。基于火山引擎 EMR 产品,可以构建数据湖仓、近实时数仓、实时数仓等场景。例如,使用 Iceberg 构建数据湖仓,从 ODS 到 DWD ...
 特惠活动
特惠活动
 数据仓库的ods是什么-优选内容
数据仓库的ods是什么-优选内容
 数据仓库的ods是什么-相关内容
数据仓库的ods是什么-相关内容
实战分享(直播&PPT)
欢迎关注【字节跳动数据平台】视频号,第一时间获取更多技术分享。以下是关于大数据、湖仓一体、数据湖、数据仓库、开源、数据中台等主题的直播与演讲 PPT 等一手材料,欢迎自取与观看: 【Apache Hudi 中文社区技术交... 《数据湖化的新思考》《基于数据湖的样本存储与样本生成》 Hudi 中文社区技术交流会-第九期 2023.03.30《社区最新进展同步》《字节跳动基于 Hudi 的湖仓一体及应用实践》《电商流量基于 Hudi 的 ODS 落湖实践》 Hu...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效和精准的决策**第一个视角是从业务视角出发,我们可以提炼为三个字为**管**,**产**,**运**1、管是管理,即让管理层进行科学决策【不再是屁股决定脑袋的决策】2、产是产品,即让产品流程优化,快速迭代【不再自嗨...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
Apache Iceberg 中引入索引提升查询性能
Iceberg 等大数据生态组件,100% 开源兼容,可以帮助企业快速构建企业级大数据平台,降低运维门槛。秉承业界领先的 EMR Stateless 理念,火山引擎 EMR 可以实现集群级别的弹性伸缩,即无业务需求时释放集群,有业务需求时再拉起集群,配合智能化的冷热数据分层存储能力,助力企业在大数据基建领域进一步降本提效。基于火山引擎 EMR 产品,可以构建数据湖仓、近实时数仓、实时数仓等场景。例如,使用 Iceberg 构建数据湖仓,从 ODS 到 DWD ...
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
需要对数据进行行级更新和删除,传统的Hive表不支持行级数据操作,粒度都是表级的,如果采用传统Hive表形式,每次对数据进行更新的成本是非常高的,需要全表数据参与,后面经过调研,发现Iceberg是支持行级更新,并且和Spark结合的比较好,经过测试之后发现没有问题,后面数仓整体就迁到了Iceberg中。这次任务的执行语句描述:将ODS层的表按照主键去重后插入到DWD层中,表为分区表,DWD层表格式是iceberg格式。```sqlinsert overwrite t...
干货 | 这样做,能快速构建企业级数据湖仓
**数据湖** **仓开源趋势**==================== **趋势一:数据架构向 LakeHouse 方向发展**LakeHouse是什么?简言之,LakeHouse是在 DataLake 基础上融合了 Data Warehouse 特性的一... 近几年热门的 ClickHouse 和 Doris 也是 Native 化的表现。### **第二,向量化。**Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 Mone...
ByteHouse:基于ClickHouse的实时数仓能力升级解读
ByteHouse是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。全篇将从两个版块讲解ByteHouse的技术业务场景及实践经验。第一版块将核心介绍ByteHouse于字节内部的业务应用场景,以及使用ClickHouse打造实时数仓的经验。第二板块将集中讲解字节基于ByteHouse对金融行业实时数仓的现状的理解与思考。...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。2. 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一...
从思考到实践,企业级大数据平台的构建之路
点击上方👆蓝字关注我们! 伴随着移动互联网、5G、AI、IoT 的飞速发展,企业数据建设正处于更大规模和更多样的变化趋势中。传统自建数据仓库,在企业数据体量持续增长、业务时效性持续提升的情况下,已经很难应对更复杂、更多样化的场景需求,平台扩展和数据融合面临重重障碍。8 月18 日,火山引擎开发者社区技术大讲堂第四期将为大家从 **开源大数据生态**和 **源于字节跳动内部的智能实时湖仓**...
