数据仓库的ods层是指
 社区干货
社区干货
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
从源系统同步过来的数据落到ODS层,但是要注意采集数据时需要能捕获到源系统表结构的变更,可以采用Flink CDC等。ODS层的数据落到Kakfa中,设置一个较长的保存周期。kafka直接作为数仓的存储层,优点是不关心数据的格... 但是Kafka本身不是一个数据库,不支持SQL查询,也不支持数据的索引和聚合,因此在数据分析方面的能力有限。另外Kafka是一个基于事件的系统,不同于传统的基于事实表和维度表的数据仓库建模方式,因此需要对数据的建模和...
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
需要对数据进行行级更新和删除,传统的Hive表不支持行级数据操作,粒度都是表级的,如果采用传统Hive表形式,每次对数据进行更新的成本是非常高的,需要全表数据参与,后面经过调研,发现Iceberg是支持行级更新,并且和Spark结合的比较好,经过测试之后发现没有问题,后面数仓整体就迁到了Iceberg中。这次任务的执行语句描述:将ODS层的表按照主键去重后插入到DWD层中,表为分区表,DWD层表格式是iceberg格式。```sqlinsert overwrite t...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。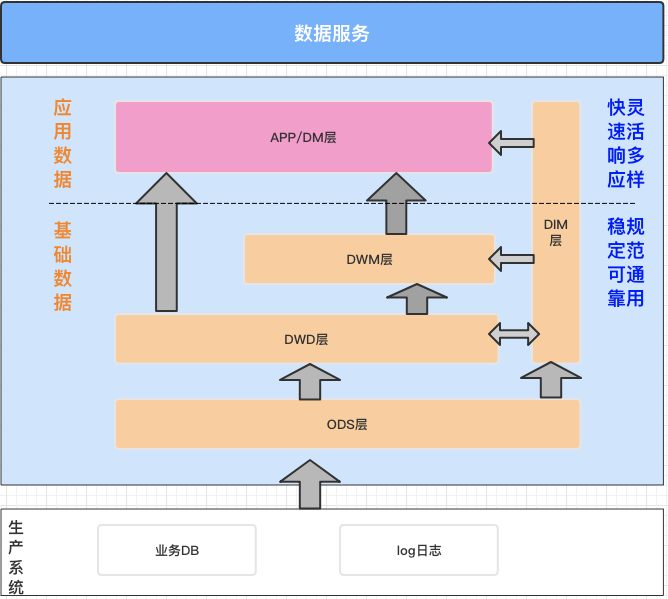本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效和精准的决策**第一个视角是从业务视角出发,我们可以提炼为三个字为**管**,**产**,**运**1、管是管理,即让管理层进行科学决策【不再是屁股决定脑... 不管是哪一种,都逃脱不了以下的常用分层架构- ODS:操作型数据(Operational Data Store),指结构与源系统基本保持一致的增量或者全量数据。作为DW数据的一个数据准备区,同时又承担基础数据记录历史变化,之所以保...
 特惠活动
特惠活动
 数据仓库的ods层是指-优选内容
数据仓库的ods层是指-优选内容
 数据仓库的ods层是指-相关内容
数据仓库的ods层是指-相关内容
新建数据表
1 数据表介绍库级 库Owner 表名 表Owner 表中文 调度频率 数据来源 专题管理 ods demo02 ods.exam_event_df demo02 考试过程表 小时 数据集成 描述:考试过程表 数据研发项目:Demo_Workshop 数据安全等级:L3 表权限负责人:demo02 产品线:ARK 业务域:教育-ARK(EK) 主题:行为主题 专题:ARK演示 层级:ODS dim demo02 dim.student_info_df demo02 学生信息表 天 数据集成 描述:学生信息表 数据研发项目:Demo...
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
需要对数据进行行级更新和删除,传统的Hive表不支持行级数据操作,粒度都是表级的,如果采用传统Hive表形式,每次对数据进行更新的成本是非常高的,需要全表数据参与,后面经过调研,发现Iceberg是支持行级更新,并且和Spark结合的比较好,经过测试之后发现没有问题,后面数仓整体就迁到了Iceberg中。这次任务的执行语句描述:将ODS层的表按照主键去重后插入到DWD层中,表为分区表,DWD层表格式是iceberg格式。```sqlinsert overwrite t...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效和精准的决策**第一个视角是从业务视角出发,我们可以提炼为三个字为**管**,**产**,**运**1、管是管理,即让管理层进行科学决策【不再是屁股决定脑... 不管是哪一种,都逃脱不了以下的常用分层架构- ODS:操作型数据(Operational Data Store),指结构与源系统基本保持一致的增量或者全量数据。作为DW数据的一个数据准备区,同时又承担基础数据记录历史变化,之所以保...
创建专题设置
“数据专题”以业务视角出发,将服务于同一业务场景的表归纳整理,形成数据仓库,方便使用者查询及管理。以营销场景为例,可以按照商品中心、会员中心等方向,形成对应数仓。PS:专题中,涉及到产品线、业务域、主题、层级... 层级 添加库:单击“添加库”按钮,以此数据las schema库,添加 ods、dim、dwd、dwm 库。 点击确认选择,再点击确认后保存成功 可按需编辑专题调整等操作,同时支持目录刷新
使用说明
数据校验等功能,既解决了数据湖数据混乱难于治理的问题,也解决了数据仓库数据封闭、信息损失以及时效性不强的问题。 Lakehouse 定位(图片来源于 Spark-Submit 2022) 基于 Delta Lake 可以构建所谓的 Lakehouse 解决方案,原始数据以流式或者批式的方式写入 Delta Lake,在 Delta Lake 内部完成 Bronze Table 到 Gold Table 的 transform 过程(类比数据仓库的 ODS 到 ADS 的过程)。不论是原始表、中间表和结果表,都支持上层多种查询...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、身份验证、查询优化器,事务管理、安全管理、元数据管理,以及运维监控、数据查询等可视化操作功能。 **服务层主要包括如下组件:**- **资源管理器**资源管理器(Resource Manager)负责对计算资源进行统一的...
实战分享(直播&PPT)
欢迎关注【字节跳动数据平台】视频号,第一时间获取更多技术分享。以下是关于大数据、湖仓一体、数据湖、数据仓库、开源、数据中台等主题的直播与演讲 PPT 等一手材料,欢迎自取与观看: 【Apache Hudi 中文社区技术交... 《数据湖化的新思考》《基于数据湖的样本存储与样本生成》 Hudi 中文社区技术交流会-第九期 2023.03.30《社区最新进展同步》《字节跳动基于 Hudi 的湖仓一体及应用实践》《电商流量基于 Hudi 的 ODS 落湖实践》 Hu...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHous... 存储计算分离:解决了全局元数据管理,过多小文件存储性能差等等技术难题。在最小化性能损耗的情况下,实现存储层与计算层的分离,独立扩缩容。- 新一代 MPP 架构:结合 Shared-nothing 的计算层以及 Shared-eve...
