简述数据仓库的应用
 社区干货
社区干货
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 以下为 ByteHouse 技术白皮书前两个版块摘录。# 1.ByteHous...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
ByteHouse技术白皮书正式发布,云数仓核心技术能力首次全面解读
云原生数据仓库凭借更灵活、更具弹性化的特性,以及有效降低资源、人力成本的能力,在云市场上受到越来越多的关注,逐渐成为企业数字化基础设施中的关键“底座”。 《火山引擎云原生数据仓库 ByteHouse 技术白皮书》简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。# 三“高”一“低”:ByteHou...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
 特惠活动
特惠活动
 简述数据仓库的应用-优选内容
简述数据仓库的应用-优选内容
 简述数据仓库的应用-相关内容
简述数据仓库的应用-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书整体架构设计版块摘录。** [点...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。2. 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况” 经典数据仓库按照大类分为基础数据层、应用数据层。 本样例中,我们的数据仓库建设思路是: ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表) DWD(对ODS冗余表数据进行轻度过滤处理) DWM (基于DWD表与业务需求,轻度聚合最近三天的数据) APP (基于DWD或DWM,...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。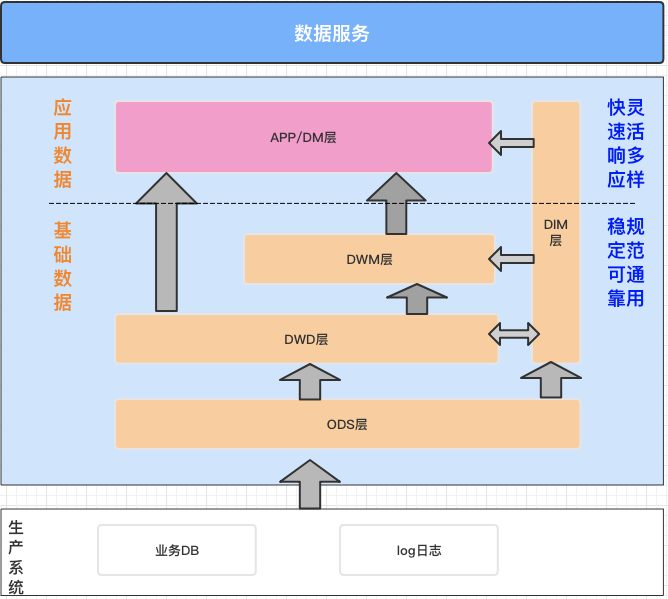本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
ByteHouse:基于ClickHouse的实时数仓能力升级解读
ByteHouse是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。全篇将从两个版块讲解ByteHouse的技术业务场景及实践经验。第一版块将核心介绍ByteHouse于字节内部的业务应用场景,以及使用ClickHouse打造实时数仓的经验。第二板块将集中讲解字节基于ByteHouse对金融行业实时数仓的现状的理解与思考。...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 可加性对于数据分析来说至关重要,因为数据应用一般不仅检索事实表的单行数据,而往往一次性检索数百、数千乃至百万行的事实,并且处理这么多行的最有用的和最常见的事就是将它们加起来,而且是从各个角度和维度加起来...
元数据迁移
1 迁移和部署 Apache Hive 到火山引擎 EMRApache Hive 是一个开源的数据仓库和分析包,它运行在 Apache Hadoop 集群之上。Hive 元存储库包含对表的描述和构成其基础的基础数据,包括分区名称和数据类型。Hive 是可以在火山引擎 E-MapReduce(简称“EMR”)上运行的服务组件之一。火山引擎 EMR 集群的 Hive 元数据可以选择内置数据库、外置数据库和 Metastore 服务三种: 内置数据库作为 Hive 元数据建议只应用于开发和测试环境。 使用...
