简述数据仓库的体系结构家
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效... 操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织的。 2、集成的【大一统、全链路】 数据仓库中的数据是在对原有分散的数据库[数据抽取](h...
干货 | 看 SparkSQL 如何支撑企业级数仓
用来做异构数据的存储以及数据的冷备份。但是也有很多企业,特别是几乎完全以结构化数据为主的企业在实施上会把数据湖和企业数仓库合并,基于某个数仓平台合二为一。企业在考虑构建自身数仓体系的时候,虽然需要参考现有的行业技术体系,以及可以选择的组件服务,但是不能太过于局限于组件本身,寻找 100%开箱即用的产品。太过于局限于寻找完全契合的组件服务必然受限于服务本身的实现,给未来扩展留下巨大的约束。企业数据仓库架构必...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化... 企业级数据仓库场景中,需要融合来自多个业务系统数据库的业务数据,主要是交易记录,例如银行存取记录、用户订单记录等,通常是数千万至数亿条规模;用户行为日志是数据量最大的数据源,包括用户访问日志、用户操作记录...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转... 用来存储实际数据、索引等内容。 数据表的数据文件存储在远端的统一分布式存储系统中,与计算节点分离开来。底层存储系统可能会对应不同类型的分布式系统。例如 HDFS,Amazon S3, Google cloud storage,Azure ...
 特惠活动
特惠活动
 简述数据仓库的体系结构家-优选内容
简述数据仓库的体系结构家-优选内容
 简述数据仓库的体系结构家-相关内容
简述数据仓库的体系结构家-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... **可信**:数据干净、数据质量高。3. **丰富**:数据涵盖的业务足够广泛。4. **透明**:数据构成体系足够透明。## 二、数仓设计 数仓设计的3个维度:- **功能架构**:结构层次清晰。- **数据架构**:数据质...
ByteHouse技术白皮书正式发布,云数仓核心技术能力首次全面解读
《火山引擎云原生数据仓库 ByteHouse 技术白皮书》简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。# 三“高”一“低”:ByteHouse 核心技术能力全面解读 ClickHouse 作为近年来快速崛起的 OLAP 数据库管理系统,以其优异的查询性能引人瞩目, 在全球及国内众多大厂得到了大量的推广及应用。...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 数据存储层。** 服务接入层负责客户端数据和服务的接入,也就是 ByConity Server;ByConity 的计算资源层,由一个或者多个计算组构成,每个 Virtual Warehouse(VW)是一个计算组;数据存储层由分布式文件系统,如 HDFS、S...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 星形架构是一种非规范化的结构,其数据存储存在冗余,比如考虑商品的维度表,其品牌信息在商品的每一行中都存在,包括其品牌 ID 、名称、品牌拥有者等。通常很多商品的品牌都是一样的,所以在商品维度表中品牌的信息被...
DataLeap数据仓库流程最佳实践
经典数据仓库按照大类分为基础数据层、应用数据层。 本样例中,我们的数据仓库建设思路是: ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表) DWD(对ODS冗余表数据进行轻度过滤处理) DWM (基于DWD表与业务... c_birth_country string comment '出生国家', c_login string comment '登录信息', c_email_address string comment '邮件地址', c_last_review_date_sk bigint comment '上次评价日期', s_store_...
DataLeap数据仓库流程最佳实践
应用数据层。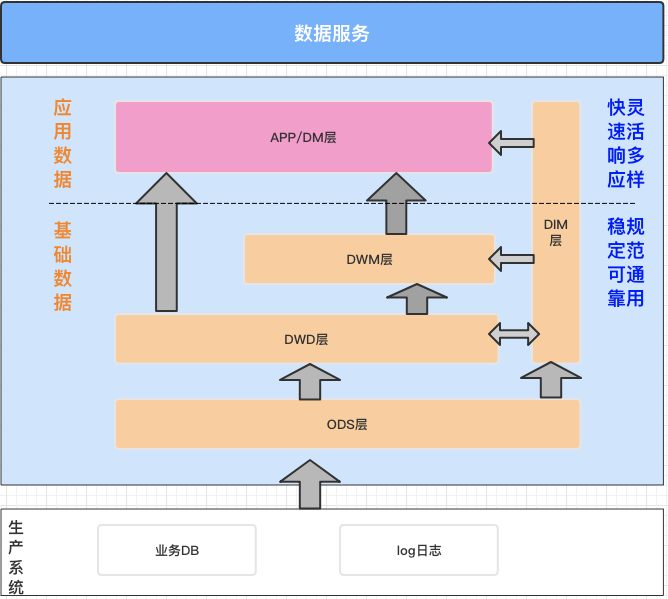本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始... c_birth_country string comment '出生国家', c_login string comment '登录信息', c_email_address string comment '邮件地址', c_last_review_date_sk bigint comment '上次评价日期', s_st...
SparkSQL 在企业级数仓建设的优势
用来做异构数据的存储以及数据的冷备份。但是也有很多企业,特别是几乎完全以结构化数据为主的企业在实施上会把数据湖和企业数仓库合并,基于某个数仓平台合二为一。企业在考虑构建自身数仓体系的时候,虽然需要参考现有的行业技术体系,以及可以选择的组件服务,但是不能太过于局限于组件本身,寻找100%开箱即用的产品。太过于局限于寻找完全契合的组件服务必然受限于服务本身的实现,给未来扩展留下巨大的约束。企业数据仓库架构必...
