Kmeans标签返回NaN聚类
 社区干货
社区干货
浅谈AI机器学习及实践总结 | 社区征文
分类问题的标签是离散的数值,比如人脸识别、判断是否正确等,判断两款运营策略哪种更有效。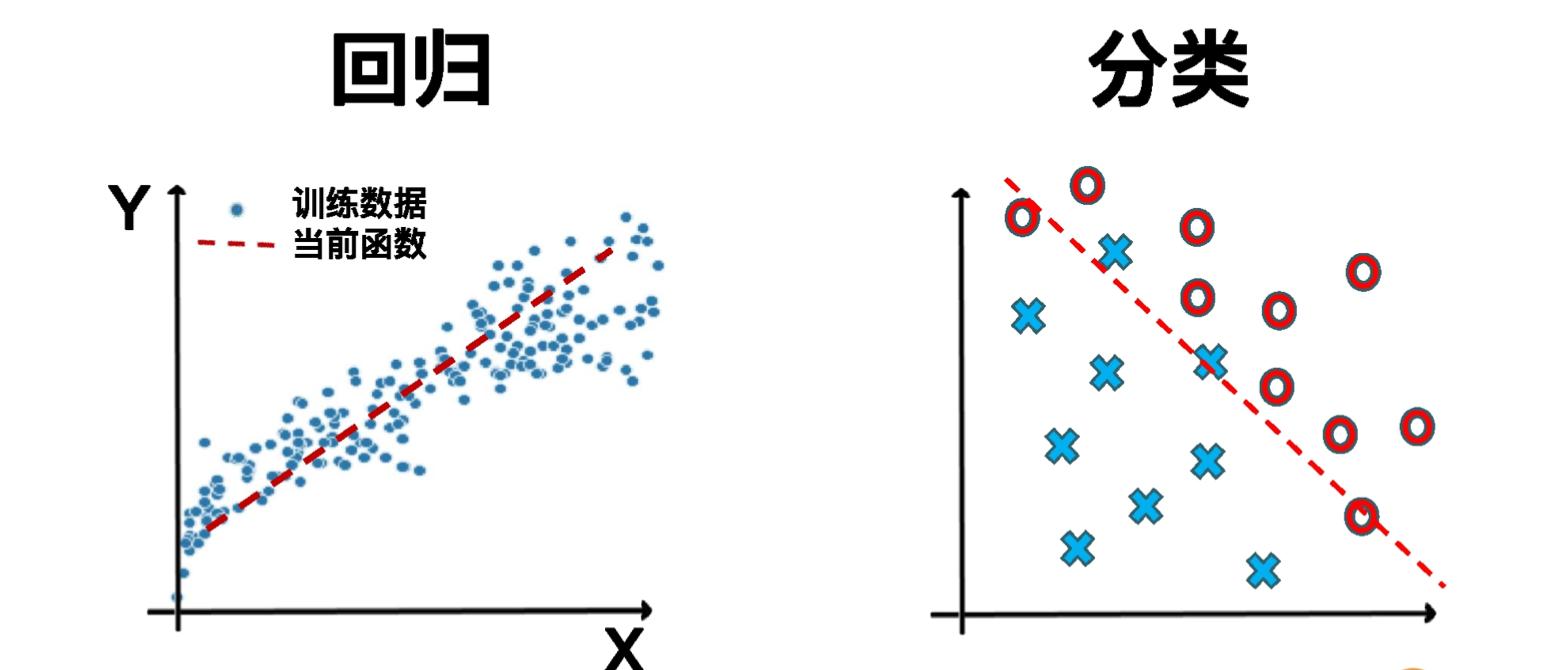分类算法:逻辑回归、决策树分类、SVM分类、贝叶斯分类、随机森林、XGBoost、KNN...回归算法:线性回归、 决策树回归、SVN回归、贝叶斯回归...- 无监督学习:训练数据集没有标签,多应用在聚类、降维等...
观点|词云指北(上):谈谈词云算法的发展
=&rk3s=8031ce6d&x-expires=1716222056&x-signature=6OcB1tlwS4%2BxSUpv6s8DNju4S%2B0%3D)其输入为分布在地理区域内点的二维坐标,每个点都与一个或多个单词相关联,算法大致步骤为:1. **使用 k-means 对有相同标签的点进行聚类。** 可能有相隔很远的两个点有相同的标签,此时会被聚集成两簇,如上图中的 Tomme。聚类后的每个簇各代表一个单词。2. **聚类后,为每个簇设置合适的角度来更好的覆盖该簇的点。** 这里采用的是主成...
[数据库论文研读] HTAP行列混存 & 智能转换
简单来说就是一种非常朴素的数据挖掘算法——**KMeans。对于每一张表T,我们能够采集到近期访问表T的query集合Q,然后给定一个参数K,算法如下:****一言以蔽之,就是对近期访问过表T的query集合作聚类,聚类输出为多个聚簇(cluster),每个聚簇(cluster)会有...
「火山引擎」数智平台VeDI增长营销季刊VOL.05
「聚类模型」**- 支持聚类模型功能,用户通过聚类模型( K-means算法)可以根据特征快速拆分已有人群,搭配后续针对性的营销策略。- 聚类模型( K-means算法)可以根据特征快速拆分已有人群,场景举例: - ... 如通过车的标签数据找到车对应的潜在客户。**名词解释:** 主体又称实体/对象,常指可被运营增长或洞察分析的人/车/场等。**场景介绍:** 在汽车行业数字化营销中,除了要关注“车主”,也要关注“车”本身,如何从单...
 特惠活动
特惠活动
 Kmeans标签返回NaN聚类-优选内容
Kmeans标签返回NaN聚类-优选内容
 Kmeans标签返回NaN聚类-相关内容
Kmeans标签返回NaN聚类-相关内容
[数据库论文研读] HTAP行列混存 & 智能转换
简单来说就是一种非常朴素的数据挖掘算法——**KMeans。对于每一张表T,我们能够采集到近期访问表T的query集合Q,然后给定一个参数K,算法如下:****一言以蔽之,就是对近期访问过表T的query集合作聚类,聚类输出为多个聚簇(cluster),每个聚簇(cluster)会有...
「火山引擎」数智平台VeDI增长营销季刊VOL.05
「聚类模型」**- 支持聚类模型功能,用户通过聚类模型( K-means算法)可以根据特征快速拆分已有人群,搭配后续针对性的营销策略。- 聚类模型( K-means算法)可以根据特征快速拆分已有人群,场景举例: - ... 如通过车的标签数据找到车对应的潜在客户。**名词解释:** 主体又称实体/对象,常指可被运营增长或洞察分析的人/车/场等。**场景介绍:** 在汽车行业数字化营销中,除了要关注“车主”,也要关注“车”本身,如何从单...
时效准确率提升之承运商路由网络挖掘
=&rk3s=8031ce6d&x-expires=1716222048&x-signature=KcPl7SYO%2B7cCCeecbvnSFkUvdlM%3D)下图是承运商接口返回的预计送达时效的宽松指数,可以看到在接近目的地时,承诺时效才比较准确。绘制上述图时使用的是kmeans聚类算法,kmeans聚类算法需要指定聚类的个数。故需要使用 **Knee/Elbow** 这类的算法进行聚类...
Katalyst:字节跳动云原生成本优化实践
k-means 聚类算法 | 0.35 | 0.48 | 0.6 || 系统指标 PID 算法 | 0.39 | 0.54 | 0.66 || 系统指标 模型预估 + PID 算法 | 0.42 | 0.57 | 0.67 | ### 4.2 实践:离线无感接入在进入第三阶段后,我们需要对离线进行云原生化改造。改造方式主要有两种,一种是已经在 K8s 体系中的服务,我们将基于 Virtual Kubelet 的方式实现资...
常用名词
关系标签体系和画像系统。应用场景:主要应用于企业的后链路营销和运营 DMP(数据管理平台) 数据来源:DMP的数据主要来自媒体自身的数据与第三方机构的数据,其触点主要是媒体提供的触点,涵盖大量广告投放端的监播数... K-Means聚类 评估 二分类评估、多分类评估、聚类评估、回归评估 2.2 标签体系概念 解释说明 标签 基于行为/属性等数据,基于业务逻辑或模型能力创建的有业务指导意义,标签值可枚举的形式 标签体系 由标签构成,以...
概述
K-Means聚类、决策树回归、ARIMA模型等多样化的机器学习算子,帮助用户完成数据建模工作。 2.使用限制 用户需具备 项目编辑 权限或者 可视化建模模块的查看/新建任务 权限,才能使用该功能。 可视化建模中部分功能为 付费能力,如有需要,请联系您的商务经理 3.核心功能 功能名称 功能说明 备注 基础版可视化建模功能 离线可视化建模任务: 数据清洗:支持「字段设置」、「IDMapping算子」 输出节点:支持「输出」、「输出标签」算子...
得物推荐引擎 - DGraph
=&rk3s=8031ce6d&x-expires=1716222048&x-signature=pKDIbPsyRLH8WGGzJJcrN6k2rXM%3D)**图8 倒排(Invert)索引** **Embedding索引**基于开源的Kmeans聚类。Kmeans聚类后,引擎会以每个中心向量(centroids)为基点,构建倒排,倒排的数据结构也是RoaringBitmap,同一个聚簇的向量都回插入同一个RoaringBitmap里面。这样的好处是,可以在向量检索中包含普通文本索引,比如你可以在向量召回的基础上限...
概述
K-Means聚类、决策树回归、ARIMA模型等多样化的机器学习算子,帮助用户完成数据建模工作。 需完成: 配置ID mapping数据集 处理数据源,输出所需数据集 第三步:数据打通,构建OneID体系 系统支持可视化地配置ID... 即后续建标签、圈人时可用的数据源。 需完成: 数据源登记:如行为数据、属性数据、明细数据 属性管理:如行为事件、主体属性等
算数函数
请注意:下文中的一些示例引用自 ClickHouse 社区文档 并经过一定修改确保可以在 ByteHouse 中正常使用。 absCalculates the absolute value of the number (a). That is, if a < 0, it returns -a. For unsigned t... or ‘nan’. Syntax sql divide(a, b) a / b operatorArguments a – The number. b – The number. Returned value Value in floating-point type Example sql SELECT divide(50, 2);Result: plain%20text ┌─...
