以插入方式为链表编写函数,按照降序的插入顺序 - 仅允许使用头节点。
 社区干货
社区干货
万字长文带你漫游数据结构世界|社区征文
**数据结构在计算机中的表示(又称为映像),称之为数据的物理结构,又称存储结构**。数据元素之前的关系在计算机中有两种不同的表示方法:**顺序映像和非顺序映像**,并且由此得到两种不同的存储结构:**顺序存储结构... 单向链表的查找更新比较简单,我们看看插入新节点的具体过程(这里只展示中间位置的插入,头尾插入比较简单):,执行 poll 方法的是运行在某个或者所有 CPU 上的内核线程(kernel thread),一旦执行就会持续处理 ,直到没有数据可供处理,然后进入 idle 状态。* 比如,当有网络包到达时,网卡发起硬件中断,于是会执行网卡硬件中断处理函数,中断处理...
Cilium 原理解析:网络数据包在内核中的流转过程
方式来接收网络包,它的核心概念就是不采用中断的方式读取数据,而是首先采用中断唤醒数据接收的服务程序,然后 poll 的方法来轮询数据。- 驱动注册的这个 poll 是一个主动式 poll(active poll),执行 poll 方法的是运行在某个或者所有 CPU 上的内核线程(kernel thread),一旦执行就会持续处理 ,直到没有数据可供处理,然后进入 idle 状态。- 比如,当有网络包到达时,网卡发起硬件中断,于是会执行网卡硬件中断处理函数,中断处...
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
## 一、Spark 架构原理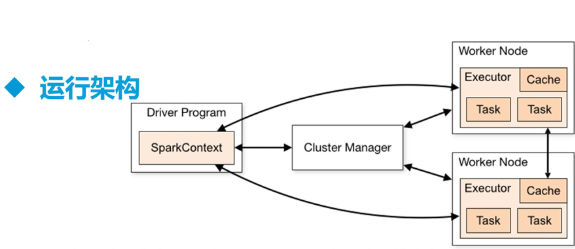> SparkContext 主导应用执行> > Cluster Manager 节点管理器> > 把算子RDD发送给 Worker Node> > Cache : Worker Node 之间共享信息、通信> > Executor 虚拟...
 特惠活动
特惠活动
 以插入方式为链表编写函数,按照降序的插入顺序 - 仅允许使用头节点。-优选内容
以插入方式为链表编写函数,按照降序的插入顺序 - 仅允许使用头节点。-优选内容
 以插入方式为链表编写函数,按照降序的插入顺序 - 仅允许使用头节点。-相关内容
以插入方式为链表编写函数,按照降序的插入顺序 - 仅允许使用头节点。-相关内容
数组函数
empty对于空数组返回1,对于非空数组返回0。 结果类型是UInt8。 该函数也适用于字符串。 notEmpty对于空数组返回0,对于非空数组返回1。 结果类型是UInt8。 该函数也适用于字符串。 length返回数组中的元素个数。 结... 其元素应该被测试为set的子集。 返回值 1, 如果set包含subset中的所有元素。 0, 否则。 特殊的定义 空数组是任何数组的子集。 «Null»作为数组中的元素值进行处理。 忽略两个数组中的元素值的顺序。 示例SE...
获取函数列表
函数名称(name) 默认根据name进行搜索 search Query String 否 test 搜索内容 order_type Query String 否 create_time 搜索类型创建时间(create_time) 更新时间(update_time) 函数域名(domain) 函数名称(name) 默认根据id进行排序 page Query Int32 否 1 页码 limit Query Int32 否 10 每页条数 order_by Query Int32 否 2 数据顺序,1为降序,2为升序(默认按照id的升序排列) 返回数据名称 类型 示例值 描述 sparrows []Sparro...
内置函数
字符串函数 FROM_JSON 根据给定的 JSON 字符串和输出格式信息,返回 ARRAY、 MAP 或 STRUCT 类型。 字符串函数 GET_JSON_OBJECT 在一个标准 JSON 字符串中,按照指定方式抽取指定的字符串。 字符串函数 INSTR 计算 ... 顺序排序,并且值为当前窗口内从开始行到当前行的累计计数值。 说明 当指定 distinct 关键字时,不能使用 order by。 如果指定的 order by 的值重复,非 Hive 兼容和 Hive 兼容的处理方式不同,请参见该部分的示例。...
硬核干货!一文掌握 binlog 、redo log、undo log|社区征文
一般的复制使用 STATEMENT 模式保存 binlog ,对于一些函数,STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog。 基于这三种模式需要注意的是:1)使用 row 格式的 binlog 时,在进行数据同步或恢复的时候... 因为直接修改磁盘数据的话,它是随机 IO,修改的数据分布在磁盘中不同的位置,需要来回的查找,所以命中率低,消耗大,而且一个小小的修改就不得不将整个页刷新到磁盘,利用率低;与之相对的是顺序 IO,磁盘的数据分布在磁...
表计算函数说明及常用场景示例
可以使用表计算来省略一些下载导出再在excel中二次处理的步骤。比如对指标汇总求和、移动计算等。 产品目前支持可视化进行表计算配置,除此之外,也可以通过增加字段,编写表计算函数来实现。本文将对表计算函数进行介... 为相同的值分配相同的排名,允许并列。使用可选的 “asc” 或者”desc” 参数指定升序或降序顺序。默认为降序。 示例RANK(sum([利润]), “asc”) along [地区],利用此函数,可以按照地区的利润求和进行升序排名,其中...
源码剖析之epoll
## 1. 源码剖析本篇主要分析`epoll_ctl`以及相关函数以下源码取自`4.10`### 1.1 epoll_ctl用于添加/调整/删除我们要监视的事件`fs/eventpoll.c````c/* * The following function implements the cont... 把当前epitem加入到文件的链表中 */ spin_lock(&tfile->f_lock); list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links); spin_unlock(&tfile->f_lock); /* * Add the current item to the RB tree. All ...
高阶函数
运算符, lambda(params, expr) 函数用于描述一个lambda函数用来传递给其他高阶函数。箭头的左侧有一个形式参数,它可以是一个标识符或多个标识符所组成的元祖。箭头的右侧是一个表达式,在这个表达式中可以使用形式参... 返回降序排序arr1的结果。如果指定了func函数,则排序顺序由func的结果决定。请注意,NULL和NaN在最后(NaN在NULL之前)。例如:SELECT arrayReverseSort([1, nan, 2, NULL, 3, nan, 4, NULL]) plaintext ┌─arrayReve...
数据清洗
添加合并行节点。点击其他需要合并的表右侧+按钮,拖拽至合并行算子左侧。在页面下方配置匹配关系,并点击执行保存配置。 2.4 聚合通过分组实现明细数据的聚合计算。 选择分组,拖拽字段到“分组” 选择聚合字段及方式: 拖拽字段到“聚合”,可更改聚合方式、设置聚合后的字段名称 2.5 计算列计算列算子,支持自定义表达式,使用Spark函数处理上游字段并添加新字段。计算列的配置流程可以表格形式清晰展示新增的字段。 2.6 筛选行选...
自定义看板
为指标名称。图例字段默认展示最大、最小、平均和当前的指标取值。 指标 支持选择需要查询的指标,允许添加多个。支持主机、进程、容器、服务、自定义指标相关的指标。 筛选 筛选维度。 时间区间统计方式 默认... 默认为2位,支持配置为无、1位、2位、3位和4位。 指标 支持选择需要查询的指标。支持配置为主机、进程、容器、服务和自定义指标的指标。当添加了多个原始指标后,仅展示最后添加的指标。 所选函数统计方式 统计方...
