分布式爬虫与一致性
 社区干货
社区干货
分布式数据缓存中的一致性哈希算法|社区征文
一致性哈希算法在分布式缓存领域的 MemCache,负载均衡领域的 Nginx 以及各类 RPC 框架中都有广泛的应用,它主要是为了解决传统哈希函数添加哈希表槽位数后要将关键字重新映射的问题。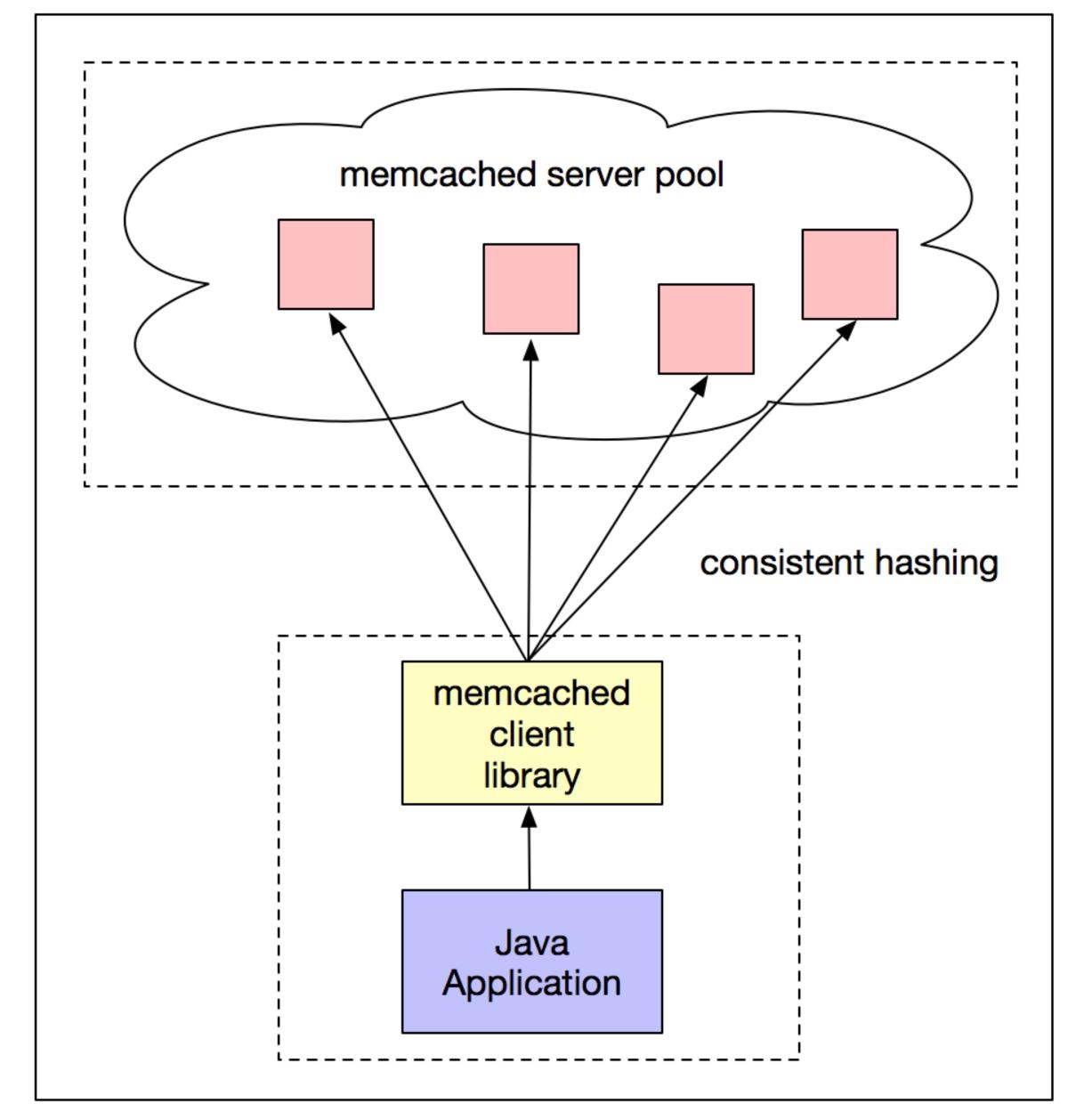本文会介绍一致性哈希算法的原理及其实现,并给出其不同哈希函数实现的性能数据对比,探讨 Redis 集群的数据分片实...
火山引擎ByteHouse:ClickHouse如何保证海量数据一致性
分布式特点,ClickHouse可以满足大规模数据的分析和查询需求,因此字节研发团队以开源ClickHouse为基础,推出火山引擎云原生数据仓库ByteHouse。 在日常工作中,研发人员经常会遇到业务链路过长,导致流程稳定性和数据一致性难保障的问题,这在分布式、跨服务的场景中更为明显。本篇文章提出针对这一问题的解决思路:在火山引擎ByteHouse中构建轻量级流程引擎,来解决数据一致性问题。 使用轻量级流程引擎可以帮我们使用统一...
业务中台数据一致性方案|社区征文
以保证业务数据的一致性。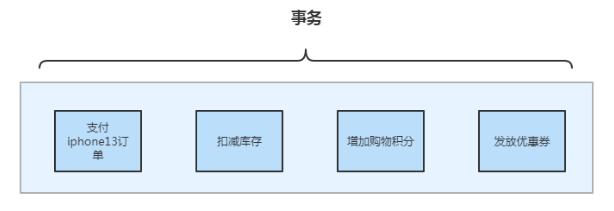## 2、分布式事务随着业务的不断发展,业务复杂度也在不断的增长,企业基于微服务架构向下沉淀出了通用的业务中台,数据的访问形式变得复杂了,服务节点间的数据访问通过 API 接口进行。原本单数据库实例只能保证数据库实例内部的事务,但是在跨数据库实例以及分布式业务调...
数据一致性离不开的checkpoint机制 |社区征文
Flink 容错机制的核心部分是通过持续创建分布式数据流和算子状态的快照。这些快照充当一致的检查点(**snapshots**),系统可以在发生故障时回退到这些检查点(**checkpoints**)。Flink 使用 [Chandy-Lamport algorithm](https://en.wikipedia.org/wiki/Chandy-Lamport_algorithm) 算法的一种变体,称为异步 barrier 快照(*asynchronous barrier snapshotting*)。当 checkpoint coordinator(job manager 的一部分)指示 task manager...
 特惠活动
特惠活动
 分布式爬虫与一致性-优选内容
分布式爬虫与一致性-优选内容
 分布式爬虫与一致性-相关内容
分布式爬虫与一致性-相关内容
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
如果要保证强一致性,势必要引入 `2PC` 或 `Paxos` 等分布式一致性协议,或者分布式锁等等,这个在实现上是有难度的,而且一定会对性能有影响。如果真的对数据的一致性要求这么高,那引入缓存是否真的有必要呢?## 2. 缓存的使用策略在使用缓存时,通常有以下几种缓存使用策略用于提升系统性能:- `Cache-Aside Pattern`(旁路缓存,业务系统常用)- `Read-Through Pattern`- `Write-Through Pattern`- `Write-Behind Pattern`...
探索云原生化的服务架构体系的技术风向,攻克云原生化微服务架构的痛点和特性 | 社区征文
容器化和容器编排:容器化是将应用程序及其依赖项打包到一个独立的单元中,称为容器。容器可以在不同的环境中运行,并提供了隔离、可移植和一致性的好处。容器编排工具(如Kubernetes)可以管理大规模容器集群的部署... 云原生-微服务框架的核心挑战在于屏蔽分布式系统复杂度和多语言差异,从而让开发者能够像单体应用一样开发微服务应用。在这里以Dubbo框架为例,Dubbo框架,快速成为国内首选,但存在着序列化协议语言相关性高、多语言...
字节跳动 NoSQL 的探索与实践
作者:王佳毅|火山引擎存储&数据库解决方案负责人> 本文整理自火山引擎开发者社区技术大讲堂第三期演讲,主要为大家介绍了 NoSQL 的前世今生和发展脉搏,以及字节跳动 NoSQL 的实践。## NoSQL 应用的现状什么是 NoSQL?我们知道关系型数据库强调 CAP 理论:Consistency,Availability 和 Partition Tolerance,这三者不可兼得。谈到 NoSQL,我们会引入 BASE 概念:- **Basically Available**:分布式系统在出现故障时允许损失部分...
大数据学习架构实践|社区征文
分布式系统相较于单机系统,就像足球与网球单打。足球是一个团体运动,需要团队成员之间的协调与调度、配合与补防,而网球单打则完全是自己能力的体现,在场上没有团队的概念。> 分布式系统遵循CAP原则:> - C:Consistency,一致性> - A:Available,可用性> - P:Partition Tolerance,分区容错性一致性是指由于在分布式系统中,存在一个数据的多个备份,因此当数据发生变化后,我们需要保证该数据在不同地方的一致性;可用性是指...
助力极致体验,火山引擎边缘计算最佳实践
为视频云业务提供全局一致性的用户体验,**通过优质的边缘节点和全域分布式的网络带宽,及多种异构算力资源,为视频云提供更低时延的网络接入能力、更优化的网络带宽成本、丰富的异构算力资源和智能调度**,满足视频云中的直播特效、虚拟主播、数字人、云游戏等场景对渲染算力的需求,支撑更多的创新玩法,带来更极致的互动体验。# **02 火山引擎边缘计算,新一代创新算力解决方案**