机器学习平台
机器学习平台



文档指南

请输入


- 文档首页
 机器学习平台最佳实践如何在火山引擎中5分钟部署 ComfyUI
机器学习平台最佳实践如何在火山引擎中5分钟部署 ComfyUI

如何在火山引擎中5分钟部署 ComfyUI
前言
机器学习云平台为用户提供了强大的AI算法开发工具,整合云原生的工具+算力(GPU、CPU云服务器),加速开发和部署流程。本案例旨在展示如何利用 MLP 快速部署 ComfyUI ,以实现高效的图像生成和处理。
快速体验
DEMO
- 本实践所参考的源码:GitHub - ComfyUI_examples
预期结果
填写各项参数及 Prompt 后,点击 Queue Prompt,即可获得图像输出。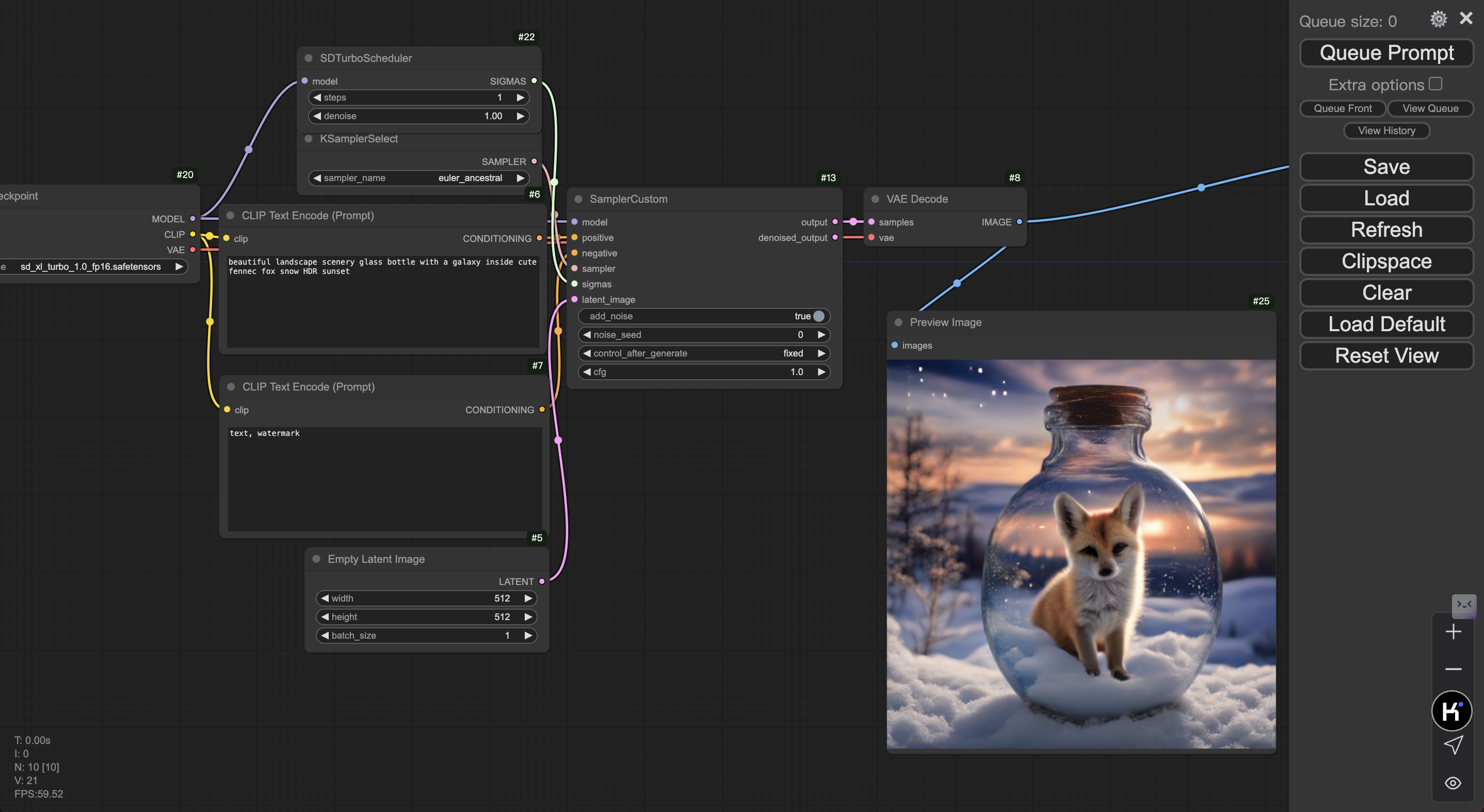
快速部署实践
前置依赖
本方案以 ComfyUI 为例,在开始执行操作前,请确认您已经完成以下准备工作:
- 请确认您已经完成快速入门中的配置。
- 确认当前已有可用队列的算力情况,建议队列内有任意 GPU 资源,CPU 生图可能会耗费大量时间
- 确保在算力所在可用区内有一个公网类型的负载均衡实例,若无请前往 负载均衡控制台 创建(在线服务依赖)
方式一:开发机部署
Step1:创建开发机
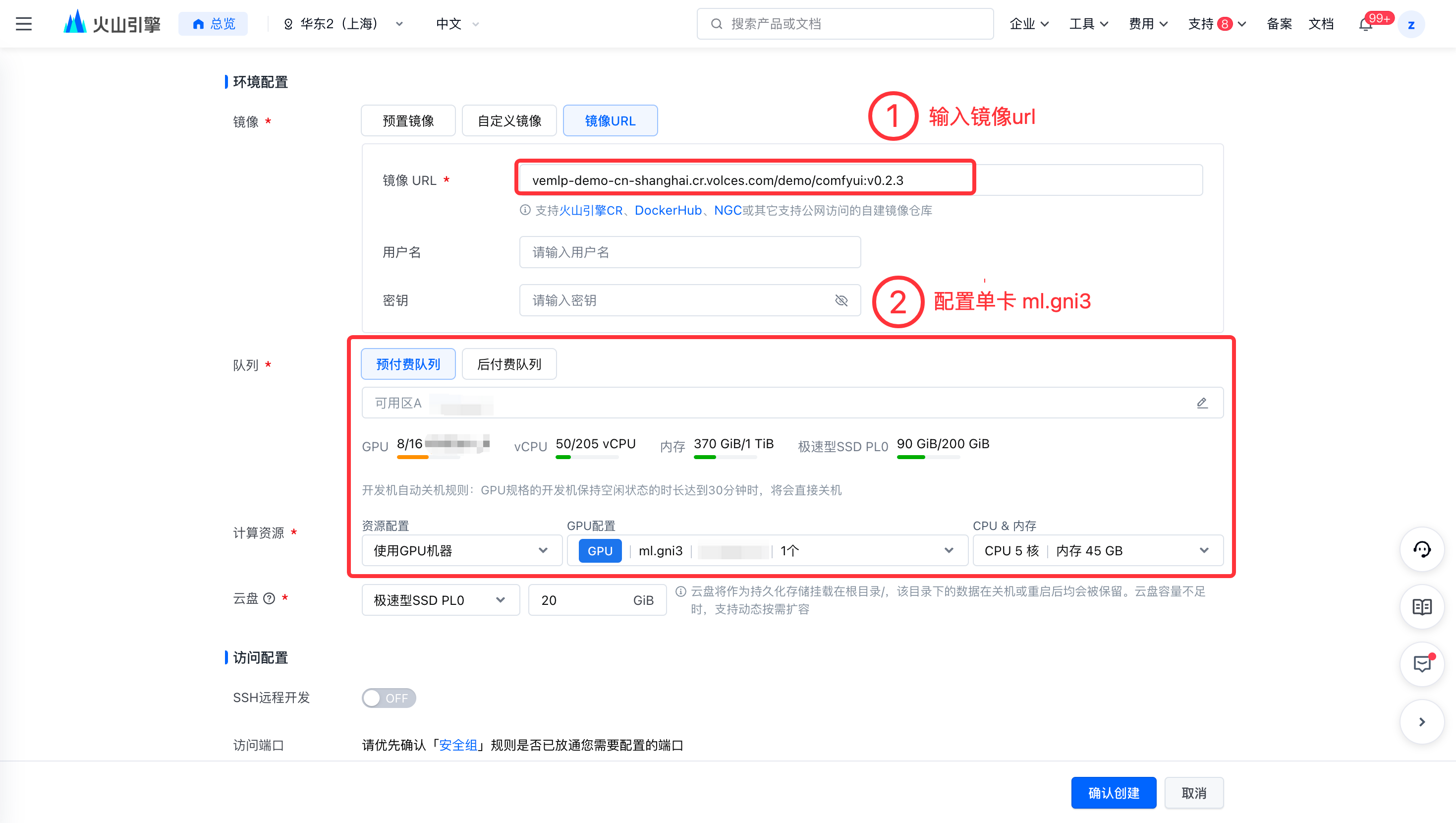
进入在开发机控制台,创建开发机并进行资源部署,具体操作详见创建开发机--机器学习平台-火山引擎。关键配置如下:
- 资源规格:配置以下资源规格。
- CPU 实例:8C/64G/20GB云盘。
- GPU 卡数:至少 1 卡,最佳实践采用一台 ml.gni3。
- 镜像:选择镜像 URL,填入
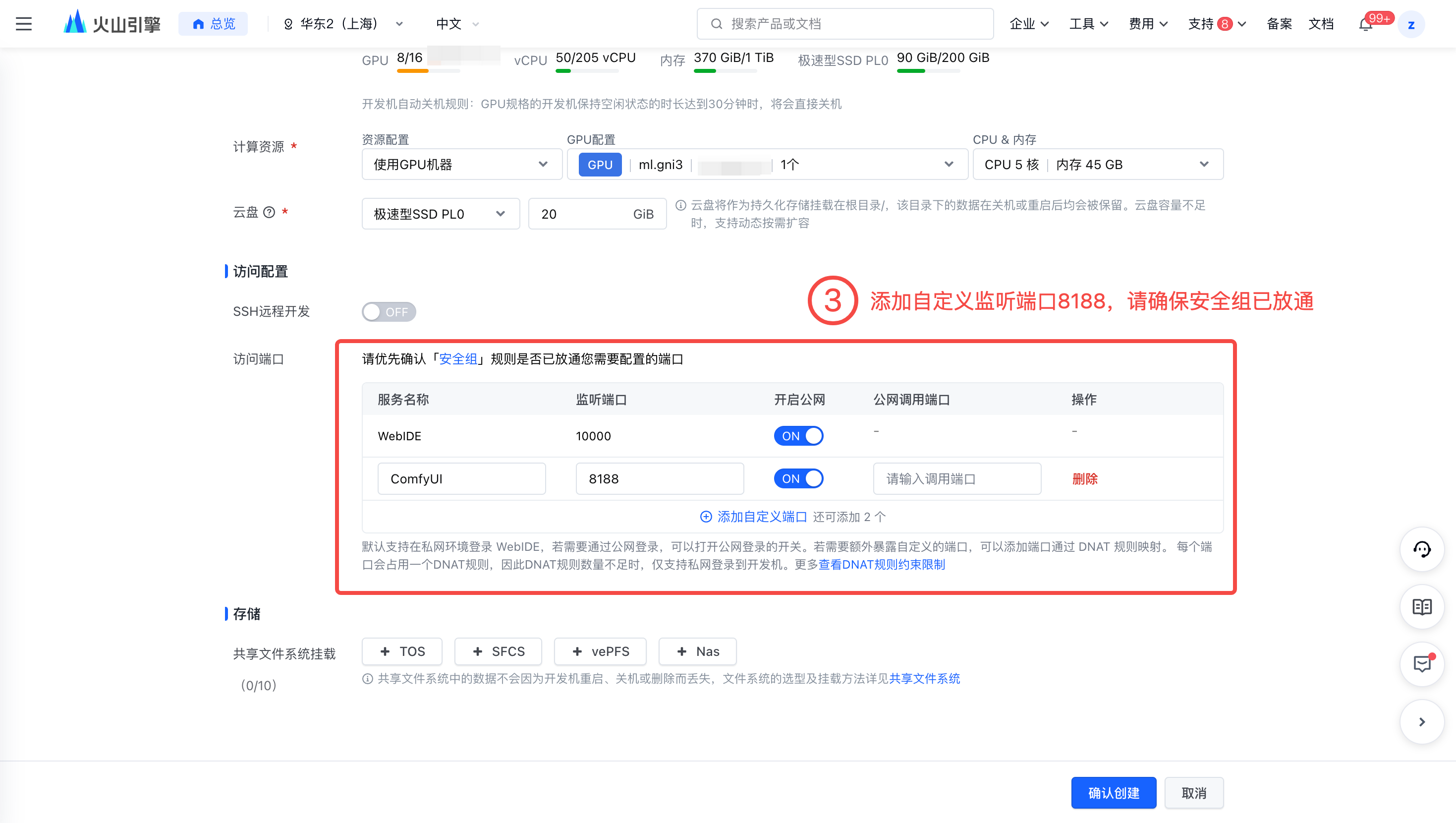
vemlp-demo-cn-shanghai.cr.volces.com/demo/comfyui:v0.2.3 - 访问端口:至少开启 SSH/WebIDE 中的一项,本实践选择 WebIDE。并添加自定义端口-监听端口 8188,请确保安全组已放通 8188。
- 确认创建后,自动跳转开发机详情页。由于拉取的镜像较大,首次创建开发机时间预计 10 分钟。
Step2:部署 ComfyUI 并下载样例模型
开发机内执行以下命令,其中下载模型时,请根据开发机所处的 Region 执行相应的内网下载命令。其中,模型内网单流下载速度约为 50MB/s,预期需要 2min 左右。注意服务起在 0.0.0.0:8188。
cd ~/code/ComfyUI/models/checkpoints # 华东2(上海)执行以下命令下载 wget vemlp-demo-cn-shanghai.tos-cn-shanghai.ivolces.com/models/sd_xl_turbo_1.0_fp16.safetensors # 华北2(北京)执行以下命令下载 wget vemlp-demo-cn-beijing.tos-cn-beijing.ivolces.com/models/sd_xl_turbo_1.0_fp16.safetensors python ~/code/ComfyUI/main.py --listen 0.0.0.0
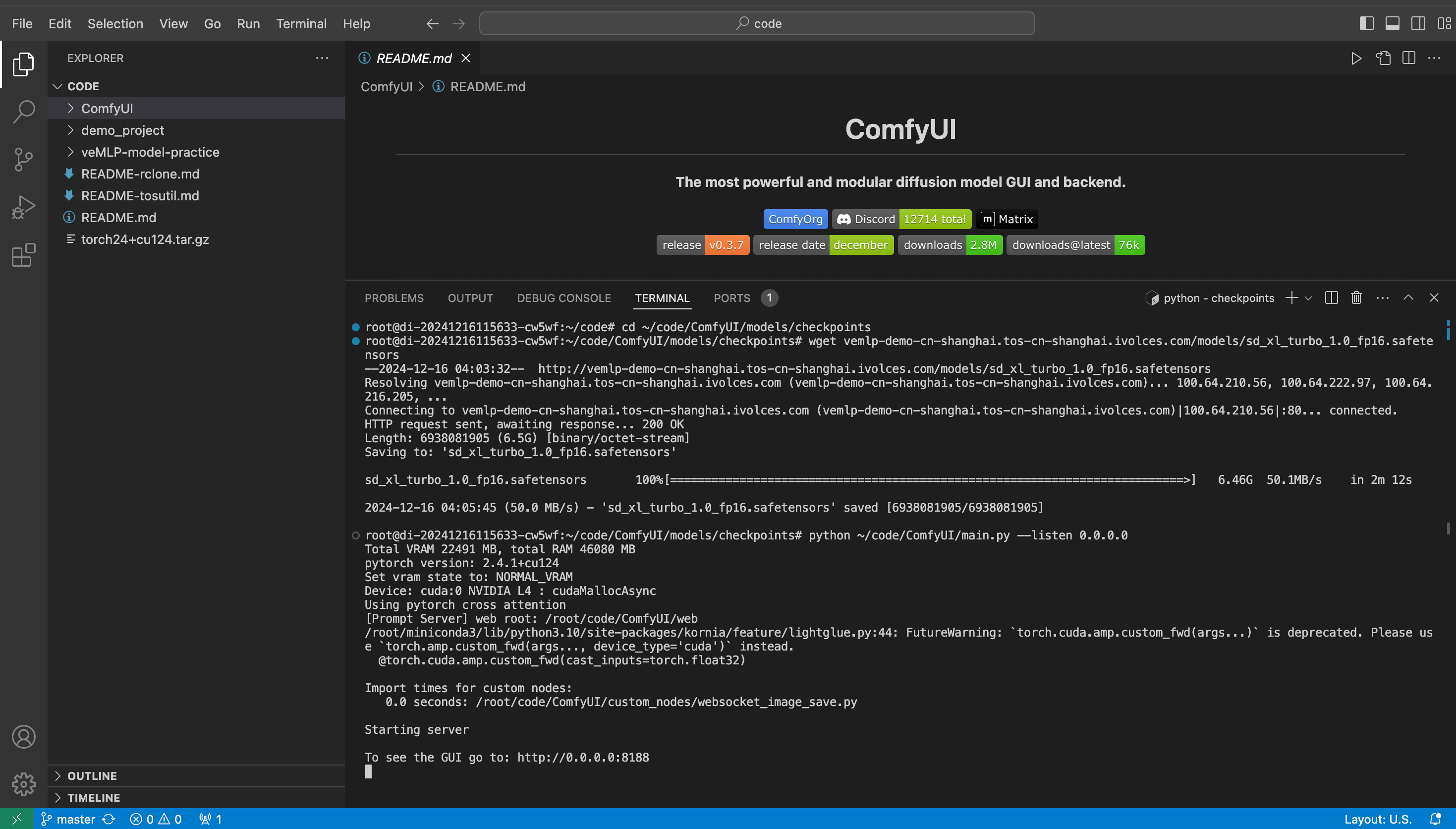
Step3:访问 ComfyUI 服务
在 Terminal 内 command+点击 http://0.0.0.0:8188 或者 在 开发机详情页-访问配置 获取访问地址在浏览器打开,即可进入 ComfyUI 服务界面。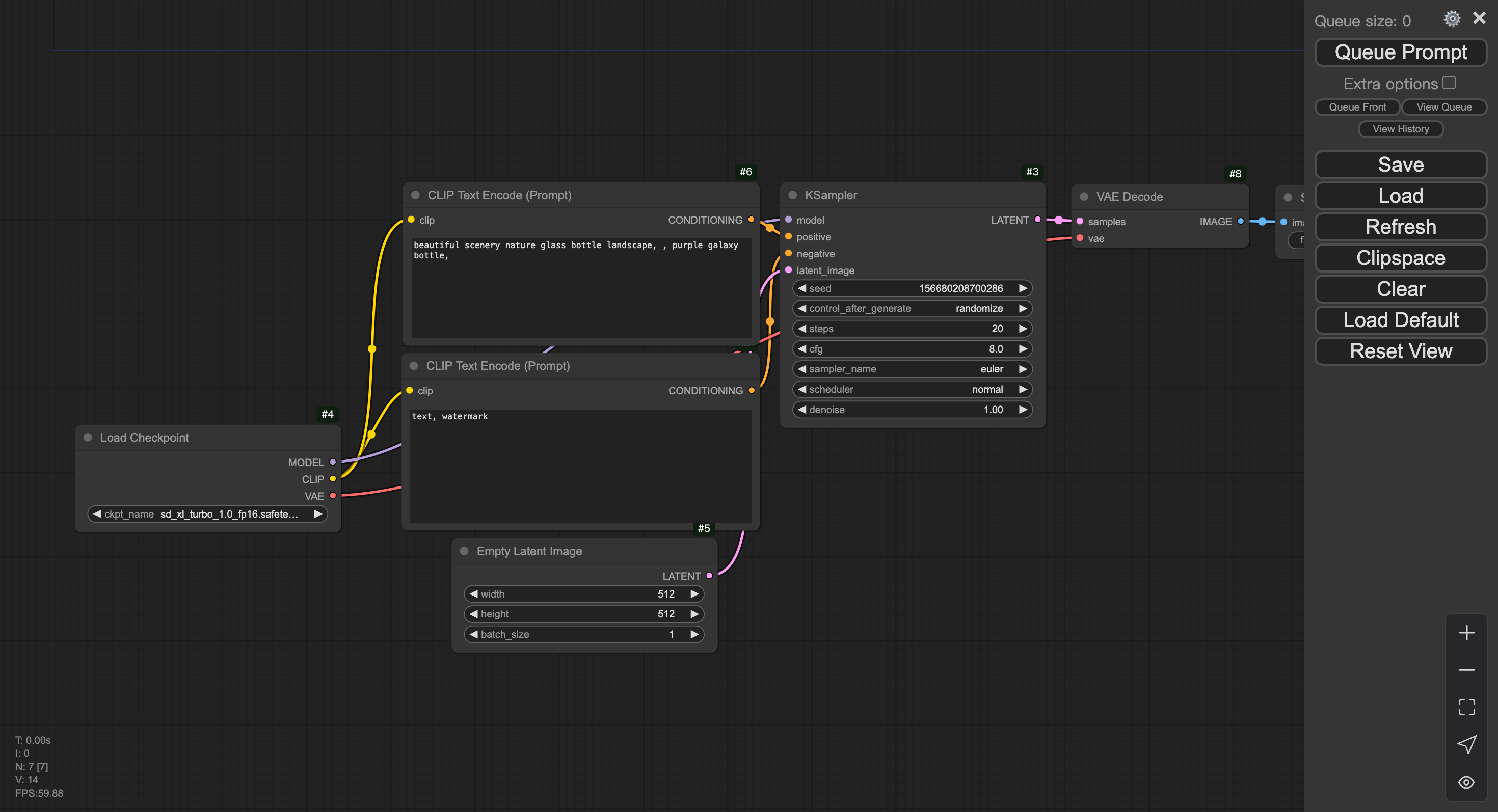
Step4:导入样例 Workflow 并生图
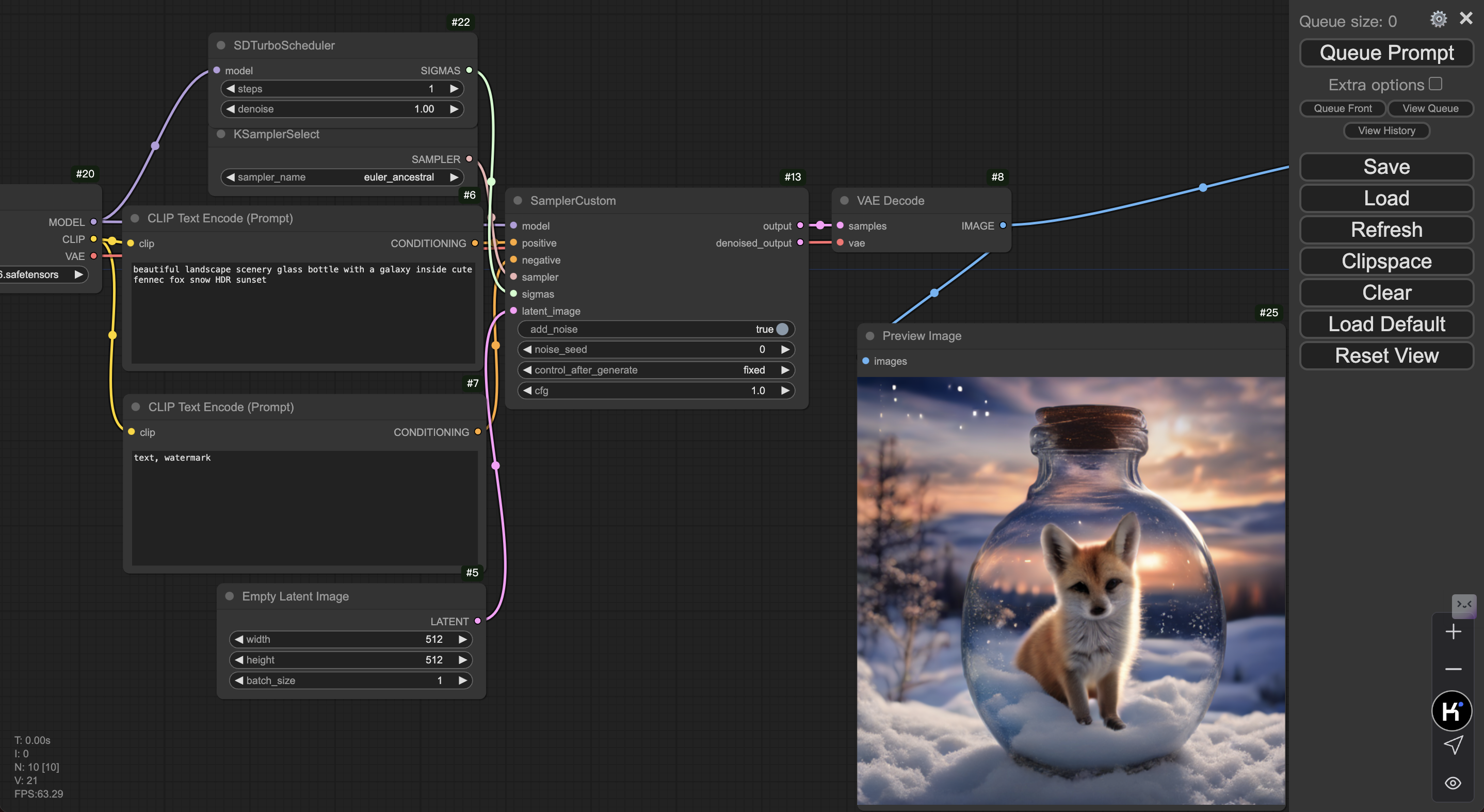
- 首先保存样例图片。

- 在 ComfyUI 界面 load 该样例图片(或将文件拖到界面内)以导入 Workflow。
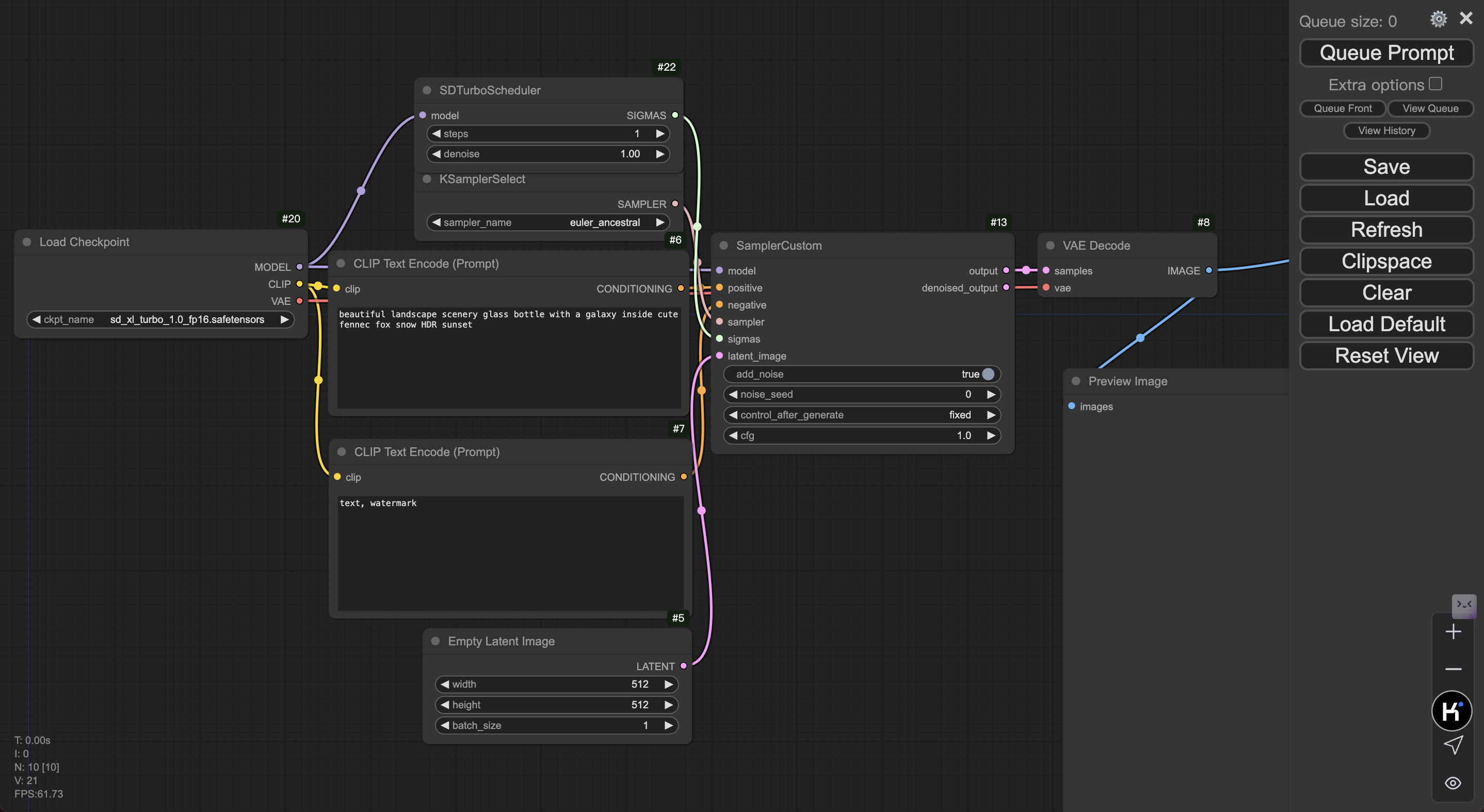
- 点击右上角 Queue Prompt,首次推理可能需要等待大约 1 分钟。
- 部署完成后,开发机内可见日志输出,ComfyUI 上可见图像输出。
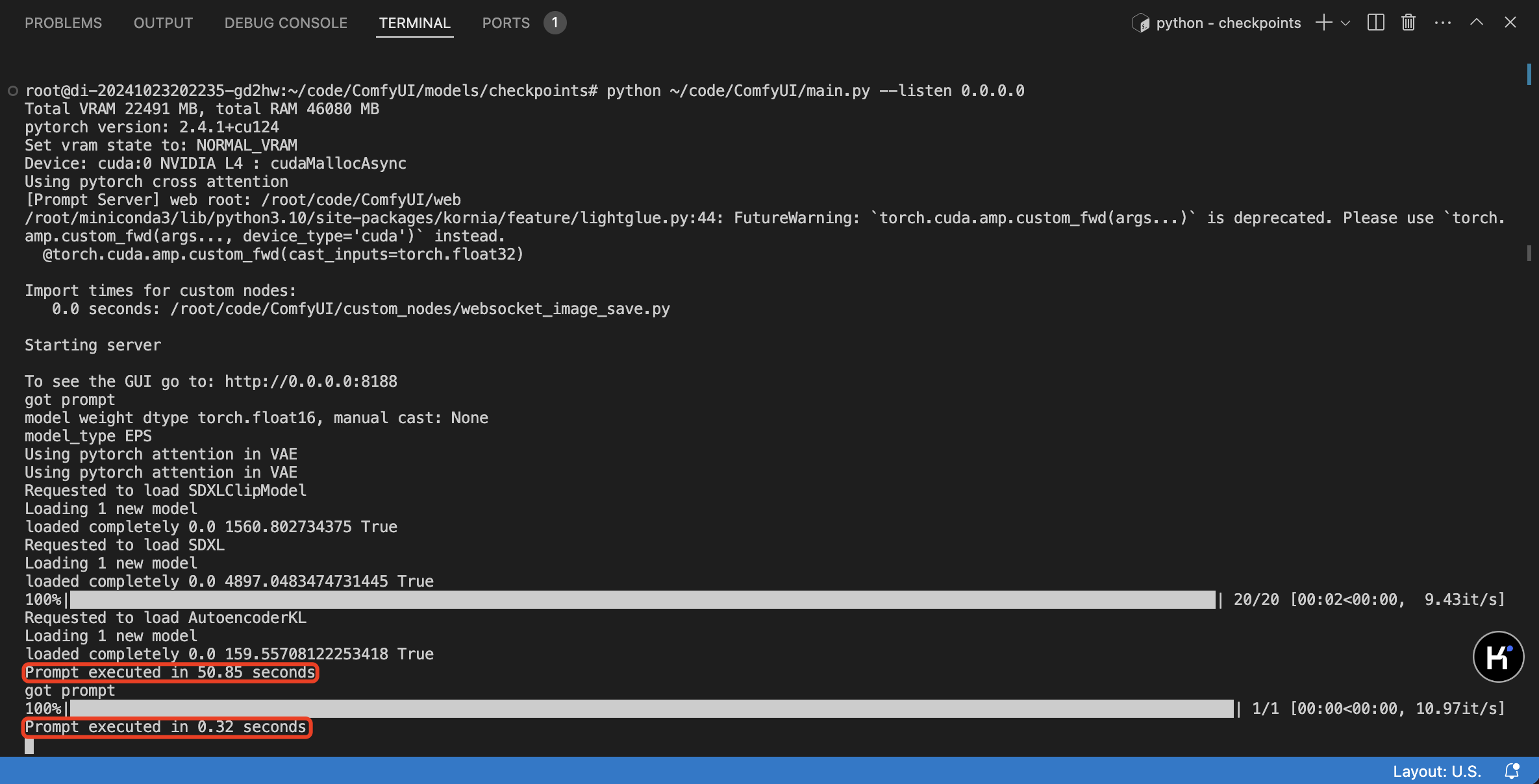
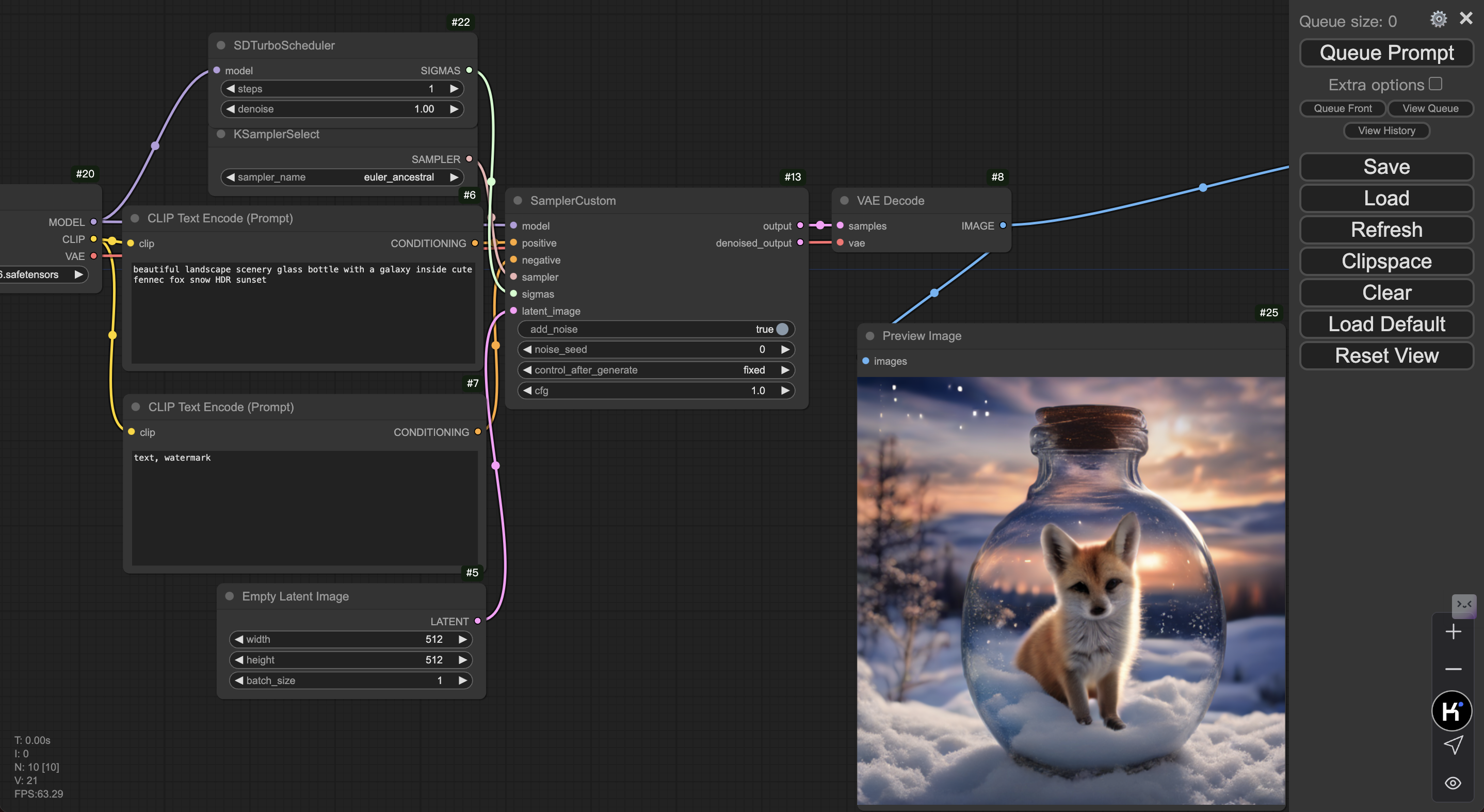
方式二:在线服务部署
Step1:创建在线服务
进入在线服务控制台,创建推理服务并进行资源部署,关键配置如下:
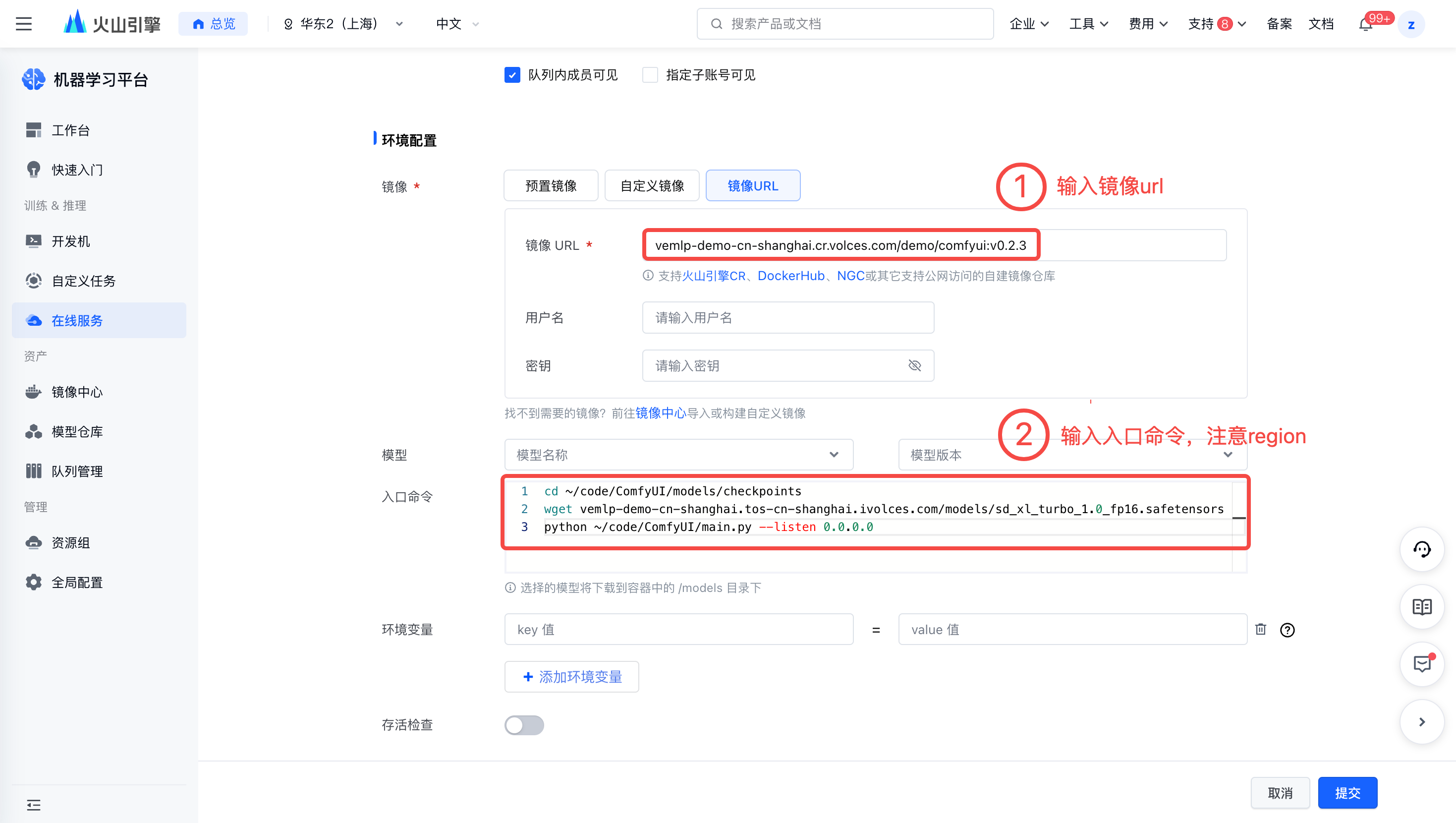
- 镜像:选择镜像 URL,填入
vemlp-demo-cn-shanghai.cr.volces.com/demo/comfyui:v0.2.3 - 入口命令:型需根据在线服务所处的 Region 执行相应的内网模型下载命令。
cd ~/code/ComfyUI/models/checkpoints # 华东2(上海)执行以下命令下载 wget vemlp-demo-cn-shanghai.tos-cn-shanghai.ivolces.com/models/sd_xl_turbo_1.0_fp16.safetensors # 华北2(北京)执行以下命令下载 wget vemlp-demo-cn-beijing.tos-cn-beijing.ivolces.com/models/sd_xl_turbo_1.0_fp16.safetensors python ~/code/ComfyUI/main.py --listen 0.0.0.0
说明
生产业务中,模型建议通过挂载共享存储 vePFS/SFCS 拉取,以保证扩容效率。
- 子网与安全组:配置安全中,请确保已放通8188。
- 端口:添加自定义端口,监听端口设置为8188,调用端口可任意选择。
- 负载均衡器:「前置依赖」 中创建的负载均衡。
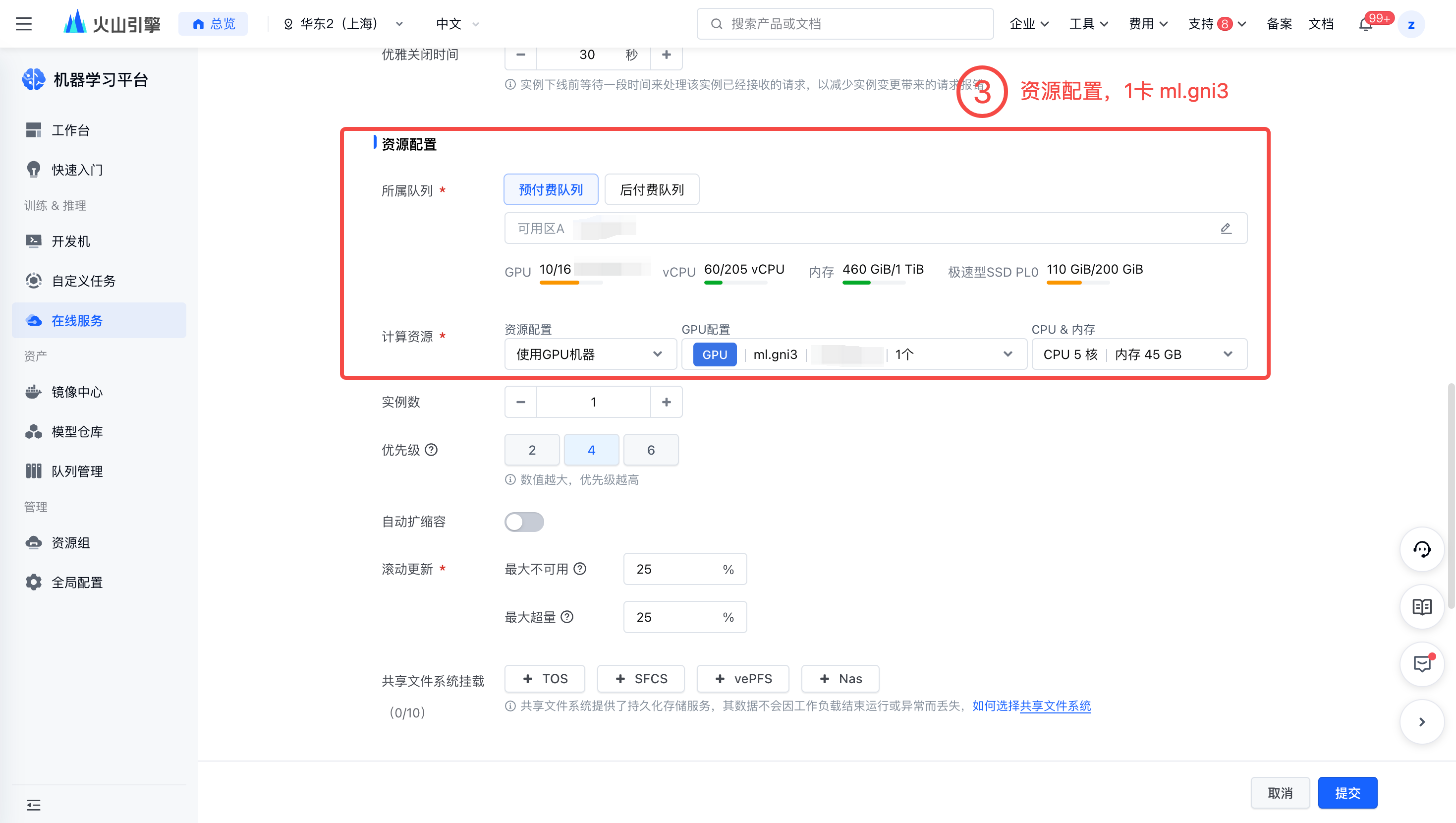
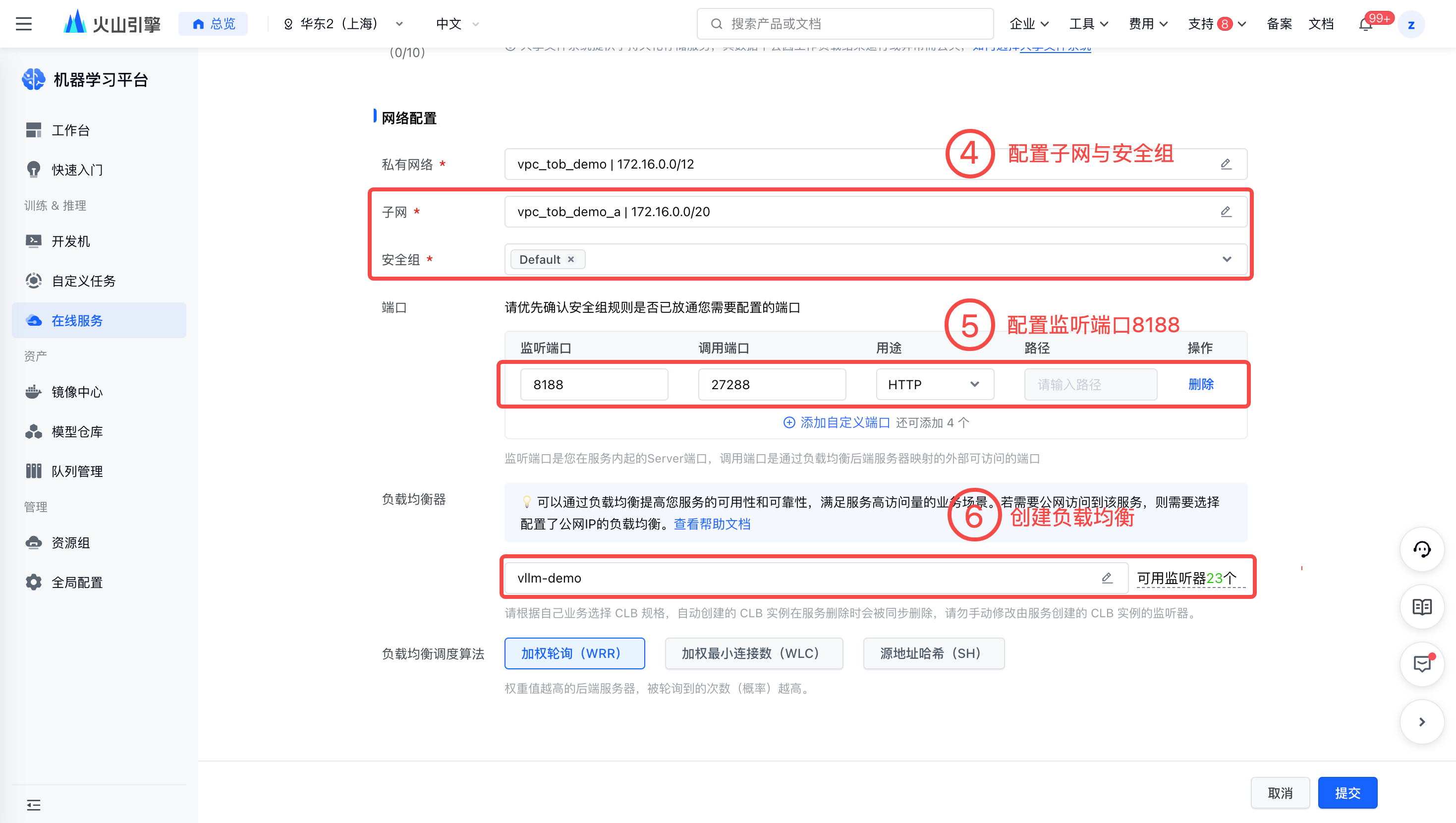
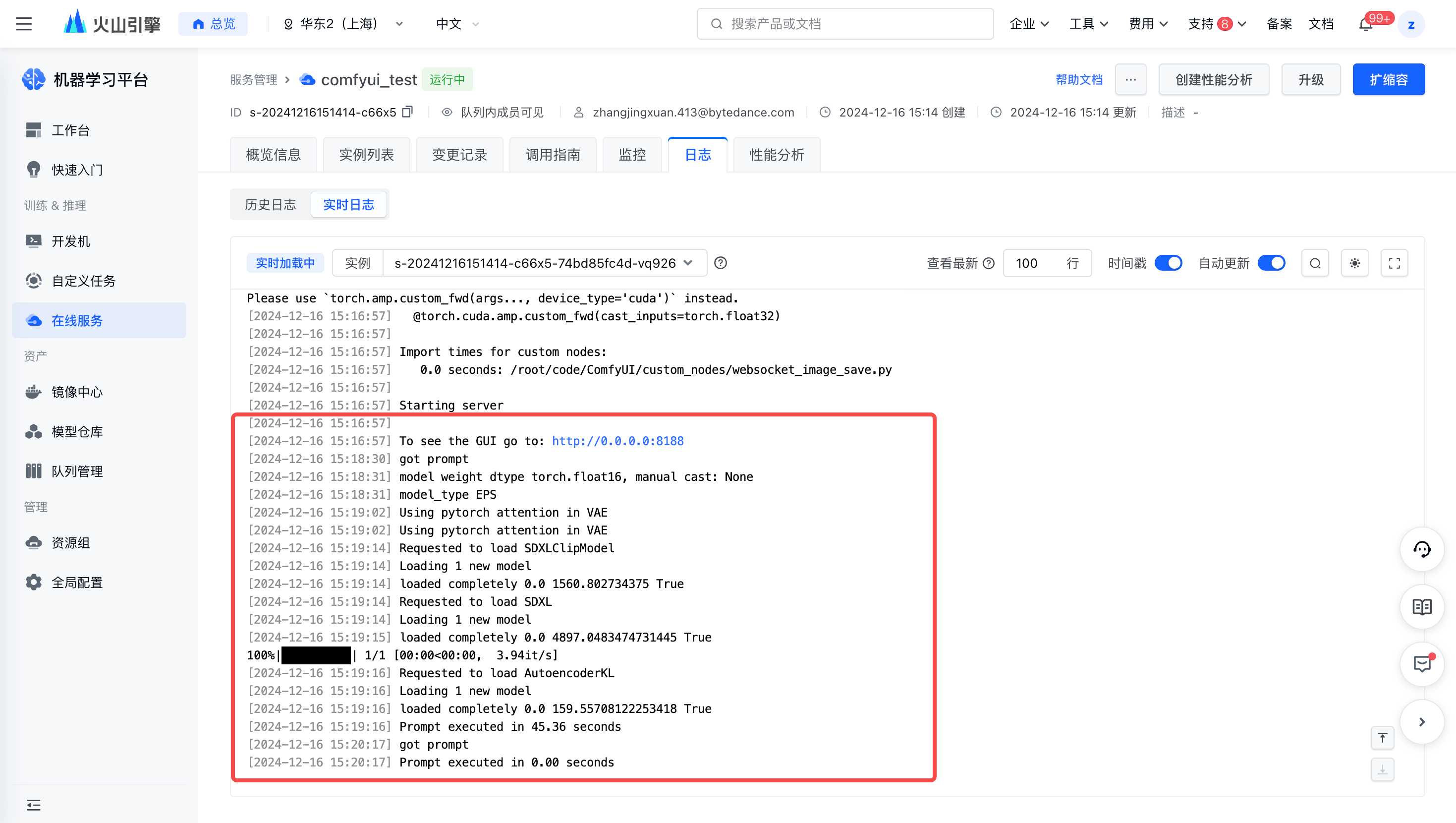
完成上述配置后,可以在【服务详情页-日志】处看到,模型内网单流下载速度约为 50MB/s,预期需要 2min 左右。注意服务起在 0.0.0.0:8188。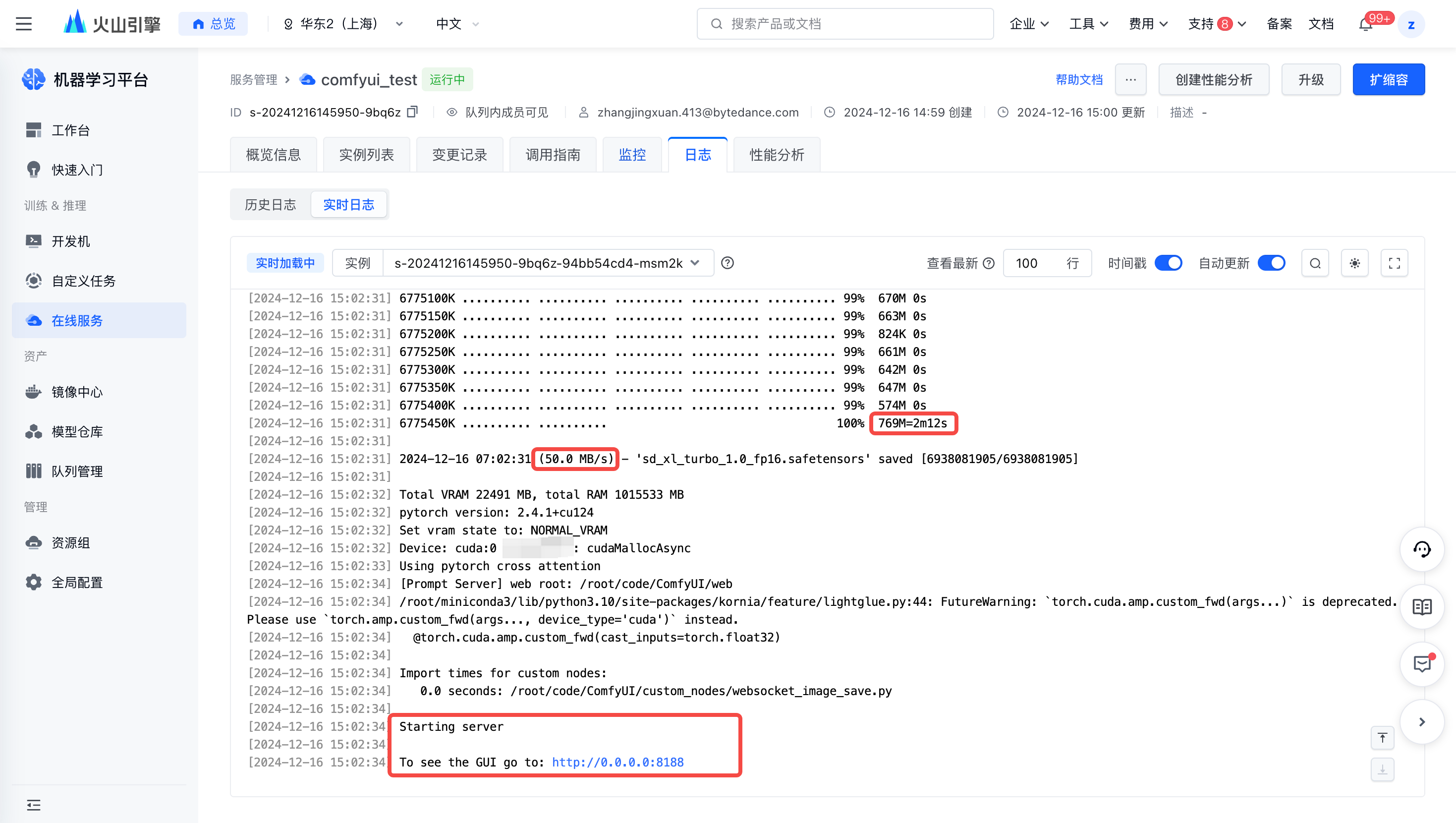
Step2:访问 ComfyUI 服务
进入已创建的在线服务【详情页 - 调用指南】,获取公网访问地址并在浏览器打开。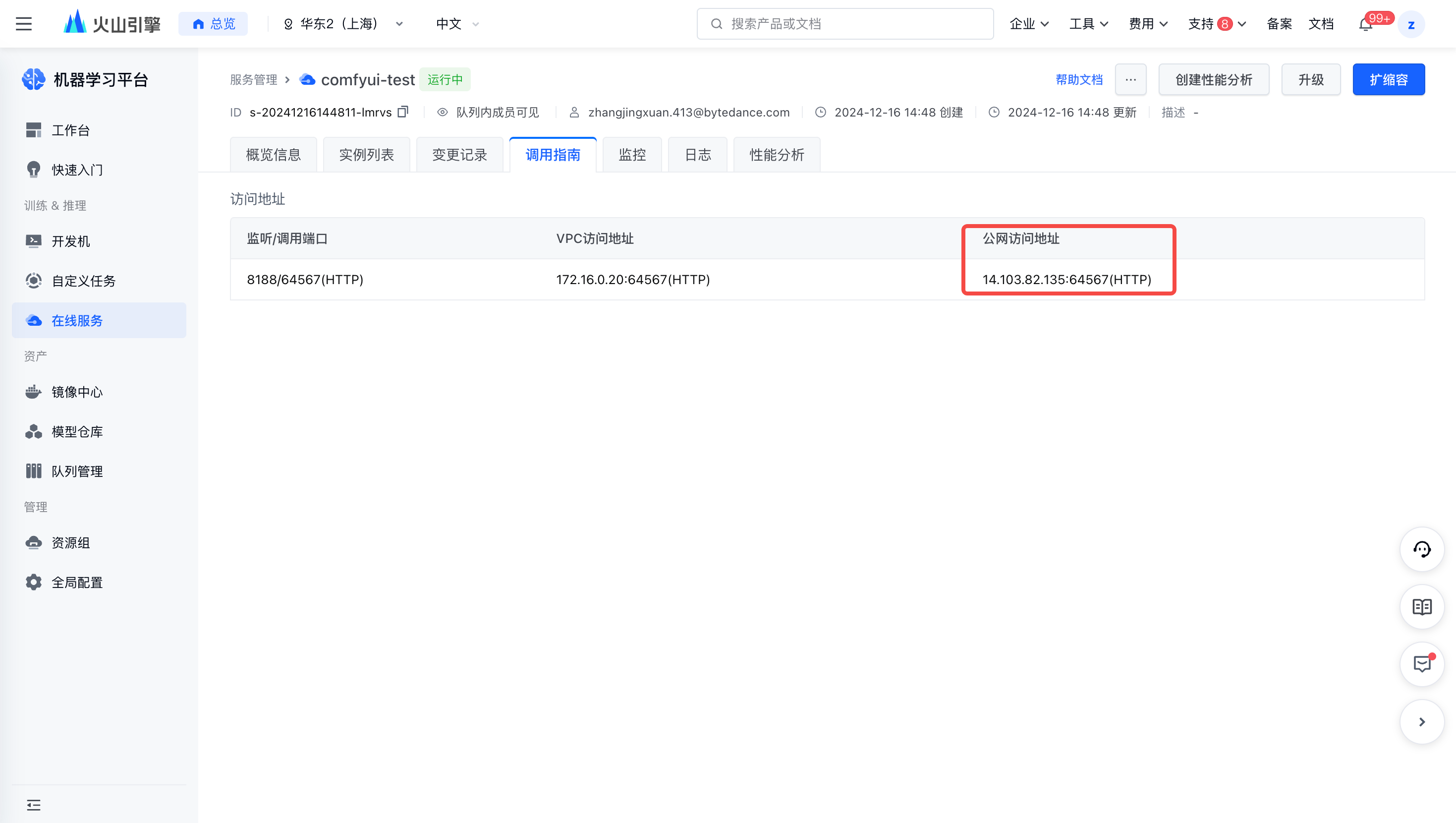
Step3:导入样例 Workflow 并生图
- 首先保存样例图片。
- 在 ComfyUI 界面 load 该样例图片(或将文件拖到界面内)以导入 Workflow。
- 点击右上角 Queue Prompt,首次推理可能需要等待大约 1 分钟。
- 部署完成后,开发机内可见日志输出,ComfyUI 上可见图像输出。
最近更新时间:2025.07.23 17:22:03
这个页面对您有帮助吗?
有用
有用
无用
无用