启动etcd服务时,“在初始集群配置中找不到本地名称""。
 社区干货
社区干货
轻量级 Kubernetes 多租户方案的探索与实践
KubeZoo 作为一个网关服务,部署在 API Server 的前端。它会抓取所有来自租户的 API 请求,然后注入租户的相关信息,最后把请求转发给 API Server,同时也会处理 API Server 的响应,把响应再返回给租户。KubeZoo 的核心功能是对租户的请求进行协议转换,使得每个租户看到的都是独占的 Kubernetes 集群。对于后端集群来说,多个租户实际上是利用了 Namespace 的原生隔离性机制而共享了同一个集群的资源。通过上面的架构图可以看出,K...
火山引擎 Redis 云原生实践
当发现 Master 节点不可用时,会主动执行 Failover, 把 Slave 节点提升成 Master,保证 Redis 服务的高可用。- **提供集群模式**:单体 Redis 实例受限于物理机内存,当需要很大的 Redis 集群容量时,可以使用 Redis... 这些不同的工作负载资源可以实现服务的配置变更,例如更新 image、升级 binary、进行副本的扩缩容等。- **水平扩缩容**:K8s 天然支持水平扩缩容,可以基于 Pod 的 CPU 利用率、内存利用率以及第三方自定义 metri...
KubeWharf | 大规模K8S集群管理系统
当k8s集群规模逐渐扩大的时候,k8s默认使用的分布式存储系统etcd是最容易出现性能瓶颈的地方之一,kubebrain项目就是用来解决etcd性能不足这个问题的。kubebrain架构图如下所示:进行... etcd-io/etcd/tree/main/etcdctl#snapshot-save-filename](https://github.com/etcd-io/etcd/tree/main/etcdctl#snapshot-save-filename)**如果您有其他问题,欢迎您联系火山引擎**[技术支持服务](https://console...
 特惠活动
特惠活动
 启动etcd服务时,“在初始集群配置中找不到本地名称""。-优选内容
启动etcd服务时,“在初始集群配置中找不到本地名称""。-优选内容
 启动etcd服务时,“在初始集群配置中找不到本地名称""。-相关内容
启动etcd服务时,“在初始集群配置中找不到本地名称""。-相关内容
字节跳动高性能 Kubernetes 元信息存储方案探索与实践
可以取代 etcd 的元信息存储系统,目前支撑着线上超过 20,000 节点的超大规模 Kubernetes 集群的稳定运行。项目地址:github.com/kubewharf/kubebrain分布式应用编排调度系统 Kubernetes 已经成为云原生应... 在存储引擎中指向一组特定的 KeyValue。ResourceLock 中包含主节点的地址以及租约的时长等信息。KubeBrain 进程启动后均以从节点的身份对自己进行初始化,并且会自动在后台进行竞选。竞选时,首先尝试读取当前的...
私有云 PaaS 场景下的 Kubernetes 集群部署实践
Kube-Proxy 这个组件主要负责当前节点上的网络路由等配置,有两种部署模式:* **iptables 模式**:使用 iptables 分发的路由规则* **IPVS 模式**:使用内核的 IPVS 路由功能两种模式从功能上对 Kubernetes 集... 作为一个集群的控制面。我们会在每个 Master 节点上启动 etcd 服务, **etcd 通过相互绑定,实现独立的 etcd 集群** 。在每个 Master 节点上会运行 API Server、Controller Manager、Scheduler 等组件,它们不会像 e...
Kubernetes 生态,从繁荣走向碎片化 | 社区征文
服务于产业与实业,分布式云+ 云原生,将成为云基础设施新范式,赋能新云原生企业敏捷创新,推动云原生生态有序繁荣,让云无处不在,让智能无所不及。**## 1.2. Kubernetes 架构及扩展性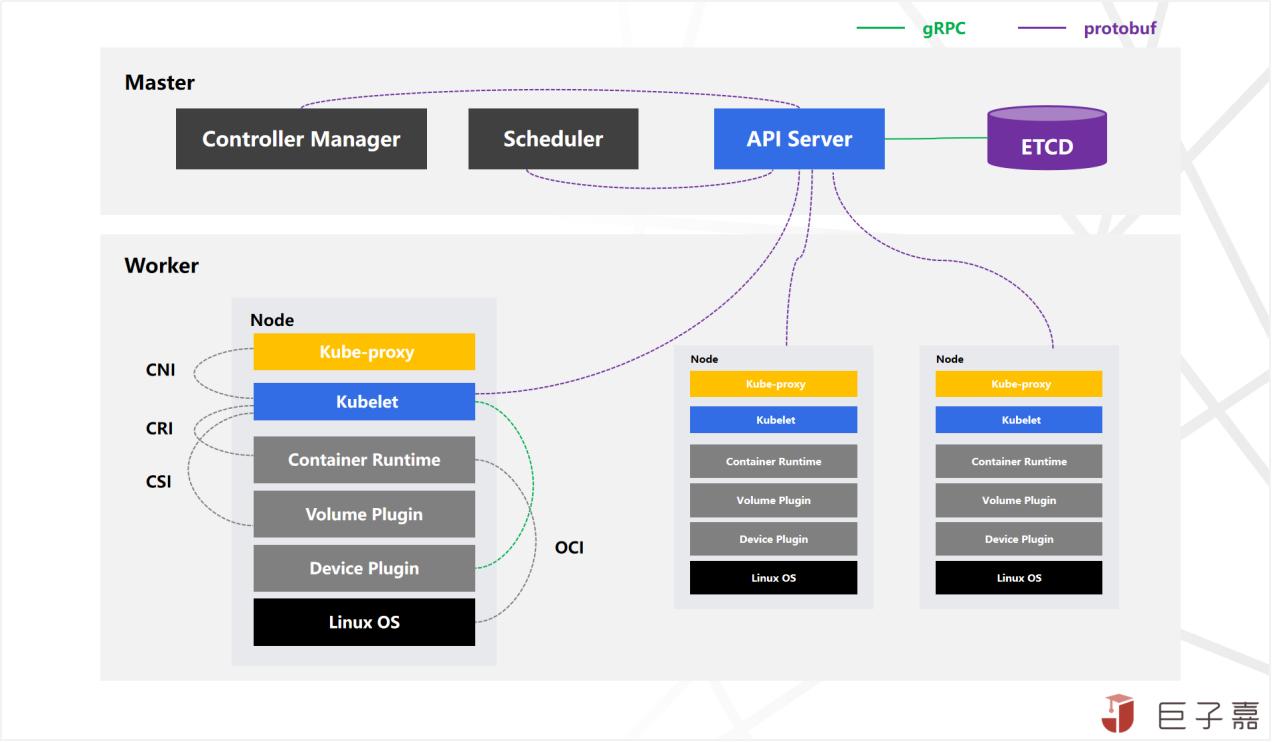Kubernetes 主要由以下几个核心组件组成:**(1) etcd** 保存整个集群的状态;**(2) ...
KubeZoo:字节跳动轻量级多租户开源解决方案
但面对集群管理,如何提升多租户集群管理能力仍是困扰开发者和企业的一个关键问题。以私有云为例。在这类环境中,企业的云原生基础设施大多被微服务平台、大数据、机器学习和存储云原生等平台占据,它们对上层用户屏... 但是超过 100 个 ECS 节点的集群寥寥无几。事实上,绝大部分 Kubernetes 集群的规格都非常之小,几十核、上百核是常态。相比计算资源,托管版的 Kubernetes 的控制面占据了一定的资源,如高可靠的 Master 和 etcd 等等...
深入云原生—基于KubeWharf深度剖析-以公司实际应用场景为例深度解读|社区征文
用于在本地和云端 Kubernetes 集群之间进行通信。● Godel Scheduler 是一个高性能的 Kubernetes 调度器,用于在 Kubernetes 集群中智能地调度容器。KubeWharf是一个分布式操作系统,由字节跳动基础架构团队在应... 从而实现对 etcd 功能的完全兼容。**具体配置如下:**```## key-prefix 参数key-prefix = "/kubebrain"## compatible-with-etcd 参数compatible-with-etcd = true```KubeBrain 编译与启动只是整个使用流...
基于共享存储的 leader 选举:在存算分离架构云数仓 ByConity 中的实践
我们通常使用 DNS 这类成熟方案来进行节点之间的服务发现,使用 Zookeeper、Etcd、Consul 这类成熟组件在副本节点之间进行 leader-follower 选举以实现集群的高可用,在配置、使用、运维管理都有一定的复杂度。在... 保证可见性顺序的本地内存,用节点的定期 Get 轮询去模拟 Linux 内核的线程唤醒通知机制,我们就可以用 ByConity 所使用的高可用 Foudation DB KV 存储,通过模拟 CAS 操作去同步多个节点之间对“谁是 leader”这个问...
集群监控实践和常用大盘
步骤二:导入监控大盘在集群中完成部署 Grafana 后,您可以下载下文中提供的监控大盘,并导入到 Grafana 系统中使用。操作步骤如下: 本地环境中使用 kubectl 连接集群,并执行以下命令,配置 Grafana 服务的端口映射。... 在下拉菜单中选择 import,进入导入大盘页面。 单击 Upload dashboard JSON file,并选择保存在本地的监控大盘 JSON 文件。 配置监控大盘的基本信息并选择数据源。配置项 说明 Name (可选)根据需要修改监控大盘的名称...
字节跳动开源 Kelemetry:面向 Kubernetes 控制面的全局追踪系统
在传统的分布式追踪中,“追踪”通常对应于用户请求期间的内部调用。特别是,当用户请求到达时,追踪会从根跨度开始,然后每个内部RPC调用会启动一个新的子跨度。由于父跨度的持续时间通常是其子跨度的超集,追踪可以直... 我们通过将每个事件分到其所属的半小时时间段中,将每个追踪的持续时间限制为30分钟。例如,发生在12:56的事件将被分组到12:30-13:00的对象跨度中。我们使用分布式KV存储来存储(集群、资源类型、命名空间、名称、...
基本概念
边缘托管中,Kubernetes 集群的 Master 节点由边缘托管服务集中管理和维护,用户不需要关心。API Server:提供各模块之间的数据交互和通信的枢纽。 ETCD:分布式数据存储组件,负责存储集群的配置信息。 Controller Man... Container Runtime:容器运行时,如 Containerd,主要用于拉取容器镜像,管理容器的全生命周期。 Yurt-Hub:YurtHub 通过本地缓存资源,使得 Pod 以及 Kubelet 在云边网络断连的情况下也能够通过 YurtHub 获取所需资源而...
