清除手机缓存是否会清除Firestore持久化?
 社区干货
社区干货
借助 MAD 助力你的 Android 应用开发|社区征文
Fragment.viewModels( noinline ownerProducer: () -> ViewModelStoreOwner = { this }, noinline factoryProducer: (() -> Factory)? = null) = createViewModelLazy(VM::class, { ownerProducer().view... { TODO("Not yet implemented") }}```以 `getBannerList` 为例,先从数据库请求本地数据加速显示,然后再请求远程数据源更新数据,同时进行持久化,便于下次请求。UI 层的逻辑很简单,订阅 ViewModel...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
查询防火墙:systemctl status firewalld开启防火墙:systemctl start firewalld查询指定端口是否已开: firewall-cmd --query-port=8089/tcp停止防火墙:systemctl stop firewalld.service关闭防火墙:systemctl d... 可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API,当下较为热门的查询性能缓存。**```yum源方式安装:示例:包存在yum install -y redis配置:/etc/redis.conf启动:redis/usr/sbin/redis-s...
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
## 一、Pulsar 介绍Apache Pulsar 是 Apache 软件基金会的顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据... 消费者将在内存缓存所有的块消息,直到收到所有的消息块。将这些消息合并成为原始的消息 M1,发送给处理进程。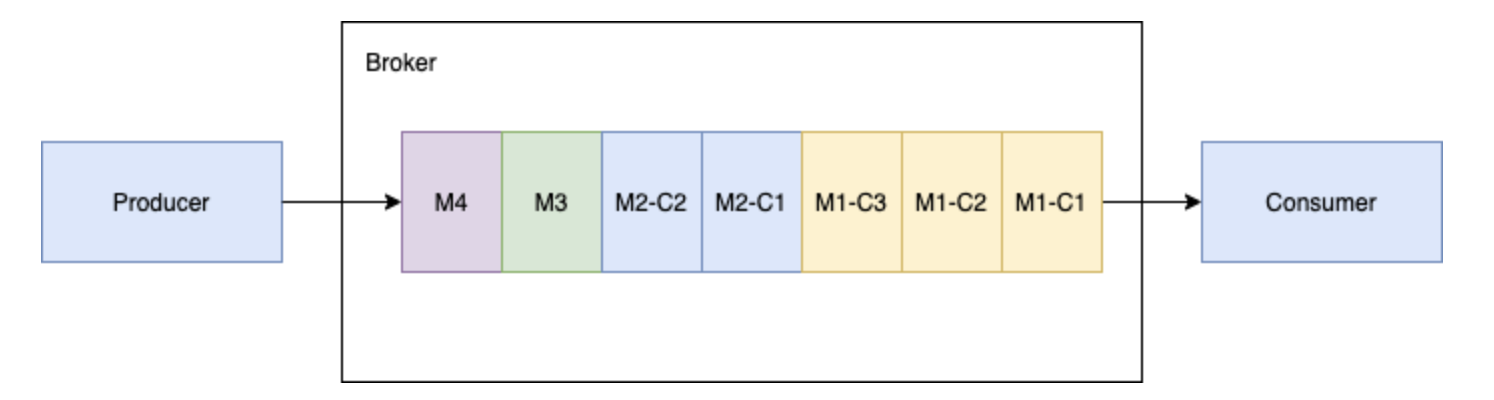##### 3...
20000字详解大厂实时数仓建设 | 社区征文
我们用到了 Flink SQL 的 Early Fire 机制,从 Source 数据源取数据,之后做了 DID 的分桶。比如最开始紫色的部分按这个做分桶,先做分桶的原因是防止某一个 DID 存在热点的问题。分桶之后会有一个叫做 Local Window ... 我们做了二级缓存的操作。如图中上方,我们读取 DWD 层的数据然后做基础汇总,核心是窗口维度聚合生成 4 种不同粒度的数据,分别是大盘多维汇总 topic、直播间多维汇总 topic、作者多维汇总 topic、用户多维汇总 to...
 特惠活动
特惠活动
 清除手机缓存是否会清除Firestore持久化?-优选内容
清除手机缓存是否会清除Firestore持久化?-优选内容
 清除手机缓存是否会清除Firestore持久化?-相关内容
清除手机缓存是否会清除Firestore持久化?-相关内容
20000字详解大厂实时数仓建设 | 社区征文
我们用到了 Flink SQL 的 Early Fire 机制,从 Source 数据源取数据,之后做了 DID 的分桶。比如最开始紫色的部分按这个做分桶,先做分桶的原因是防止某一个 DID 存在热点的问题。分桶之后会有一个叫做 Local Window ... 我们做了二级缓存的操作。如图中上方,我们读取 DWD 层的数据然后做基础汇总,核心是窗口维度聚合生成 4 种不同粒度的数据,分别是大盘多维汇总 topic、直播间多维汇总 topic、作者多维汇总 topic、用户多维汇总 to...
干货|湖仓一体架构在火山引擎LAS的探索与实践
这就意味着有大批量的任务去访问ByteLake的MetaStore Service。在这种场景下,ByteLake MetaStore Service就会成为一个性能瓶颈。 为了突破这个瓶颈,除了无限的堆加资源之外,另一个比较有效的方案就是增加缓存。通过元数据服务端去缓存比较热点的数据,比如Commit Metadata和Table Metadata,来达到服务端的性能提升。 另外一块,是在引擎侧做优化。比如在Flink引擎层面将Timeline的读取优化到 JobManager 端。同...
浅谈分布式操作系统 KubeWharf 的第二批开源项目|社区征文
是否应将 event 报告为一个跨度: - 持久化处理的最后一个 event 的时间戳,并在重启后忽略该时间戳之前的事件。虽然事件的接收顺序不一定有保证(由于客户端时钟偏差、控制器 — apiserver — etcd 往返的不一致延迟等原因),但这种延迟相对较小,可以消除由于控制器重启导致的大多数重复。- 验证 event 的 resourceVersion 是否发生了变化,避免由于重列导致的重复 event。#### **将对象状态与审计日志关联**在研究审...
云原生之旅:一年的变革、成长与启示|社区征文
同时还需要考虑持久化存储、缓存等问题。# 云原生到底哪里好?综合来说云原生可以打通微服务开发、测试、部署、发布的整个流程环节,在云原生架构下,底层的服务或者是API都由将部署到云中,等价于将繁重的运维工作转移给了云平台供应商, 但这也得益于云计算的基础设施更加廉价。详细来说一下个人认为的以下三个优势:兼容的接口,并为所有查询引擎提供统一的元数据视图,解决了异构数据源的元数据管理问题。CatalogService 整体分三层,第一层是 Catalog Federation,提供统一的视图和跨地... KVStore 中存储着 UI 显示所需的完备信息。对于 History Server 的用户来说,绝大多数情况下我们只关心任务的最终状态,而无需关心引起状态变化的具体 event。因此,我们可以只将 KVStore 持久化下来,而不需要存储大量...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
并且提供对历史数据的更新删除能力 Upsert/Update/Delete; **●** 跟 Spark、Flink、Presto 等计算引擎集成比较好。