深度学习可以确定两个手写样本是否来自同一人吗?
 社区干货
社区干货
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
> 深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删... 覆盖了多个业务领域;这些数据还支持算法团队的特征调研、特征工程,并为模型的迭代和优化提供基础。目前字节跳动以及整个业界在机器学习和训练样本领域的一些趋势如下: 首先,**模型** **/样本** **越来越大**...
基于深度学习的工业缺陷检测详解——从0到1|社区征文
# beginning2023年可谓是人工智能浪潮翻涌的一年,AI在各个领域遍地开花。以我最熟悉的工业为例,深度学习也在其中起着重要作用。不知道小伙伴们熟不熟悉工业领域的缺陷检测腻?🧐🧐🧐今天就以钢轨表面缺陷为例,和大... 其中batchsize是每一批每一步的样本数。经过训练后就得到了如下图各类别的检测结果。可以看到轨面的AP最高,达到了0.98,说明算法对轨面类的识别性能最好,所以后续我们会使用轨面的预测框宽度和轨面实际的物理宽度...
golang pprof
后续我们可以看到更多类型的性能分析数据- Time:pprof文件采集开始的时间,精确到min- Duration:pprof持续的时间,后边的Total samples是样本数采集的时间执行`top`命令可以可以看到占用量逆序排列的函数,如... 如果需要传多个函数地址,则用加号做连接,如下。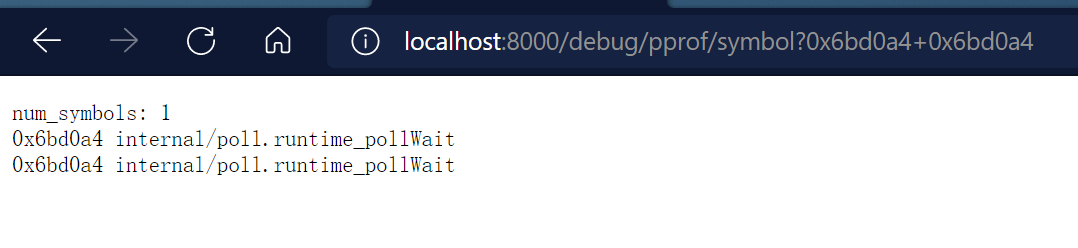3. `/debug/pprof/trace`获取程序...
AI赋能安全技术总结与展望| 社区征文
比如恶意样本检测、恶意流量检测、恶意域名检测、异常检测、网络钓鱼检测与防护、威胁情报构建等。人工智能不仅能够提高威胁检测能力,而且还能帮助安全运营分析师辅助决策。例如从无数的学术论文、博客、新闻报道中收集威胁情报,从而对每日海量的警报日志进行自动筛选,并结合人工智能技术对海量日志进行评分分级,从而大大减少了分析师的工作时间。在人工智能赋能安全蓬勃发展浪潮中,机器学习技术(包括深度学习技术)在应对网络空间...
 特惠活动
特惠活动
 深度学习可以确定两个手写样本是否来自同一人吗?-优选内容
深度学习可以确定两个手写样本是否来自同一人吗?-优选内容
 深度学习可以确定两个手写样本是否来自同一人吗?-相关内容
深度学习可以确定两个手写样本是否来自同一人吗?-相关内容
2022下半年《软考-系统架构设计师》备考经验分享
紧接着讲如何从多个维度评价一个软件架构设计(质量属性、软件质量评估方法),为了达到软件系统设计的预期标准,如何通过一些架构模式(或叫架构风格)来实现整个架构的设计。并额外列举了一些派生的架构模式和现实系统... 这一部分建议深度学习,因为在论文中写项目的背景、价值的时候可能也会用到,要深刻理解之后再开始刷题。#### 1.5 信息安全&法律常识(5%)这一部分内容是信息安全和法律常识的基础内容,信息安全包括:基础密码学(对称...
万字长文带你弄透Transformer原理|社区征文
> 🍊作者简介:[秃头小苏](https://juejin.cn/user/1359414174686455),致力于用最通俗的语言描述问题>> 🍊专栏推荐:[深度学习网络原理与实战](https://juejin.cn/column/7138749154150809637)>> 🍊近期目标:写好... 可以这么说,搞懂了这两个部分transformer你基本就掌握大部分了。接着我会讲解encoder和decoderr模块,明白的Multi-Head Attention后,其实encoder和decoder模块就非常简单了。最后,我会做一个总结,提出我的一些思考和...
人工智能之自然语言处理技术总结与展望| 社区征文
对机器学习和深度学习拥有自己独到的见解。今天给大家分享的是人工智能之自然语言处理技术总结与展望,欢迎大家在评论区留言,和大家一起成长进步。# 1. 背景 2021年5月20日,第五届世界智能大会在天津开幕。中... 分别对三个公开数据集的测试,在全样本训练、少样本学习、零样本学习场景下Prompt Learning方法远高于基于finetune的baseline。# 4. 数据增强 上文中提到的预训练模型和Prompt Learning本质上都属于如何利用...
AI安全技术总结与展望| 社区征文
人工智能内生安全主要包括:框架安全,如TensorFlow、Caffe、PyTorch等深度学习框架存在若干漏洞;数据安全,如数据丢失或者变形、噪声数据干扰人工智能研判结果;算法安全,如难以保证算法的正确性,对抗样本、自动驾驶中... 也可以自己组装,但耗时较大。因此,机器学习领域更多是应用已经开源的深度学习框架,但这些框架也不是绝对安全的,如TensorFlow,曾经被发现24个CVE编号的漏洞,其中危险等级严重的漏洞(critical severity)2个,高危(hig...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和... 覆盖了多个业务领域;这些数据还支持算法团队的特征调研、特征工程,并为模型的迭代和优化提供基础。目前字节跳动以及整个业界在机器学习和训练样本领域的一些趋势如下:首先, **模型** **/样本** **越来越大...
2023年 - 我的程序员之旅和成长故事
看看BOOS上有没有消息,导致我那两天效率特别低,别看人在房间里坐着背面试题,可是只有我自己知道,其实我那两天并没有背出啥名堂来。🔥到了下一周,我觉得不能这样再下去了,于是我开始调整心态,也学习了一下投递简... 因为约到了江苏这边好几个线下面试,而是当时疫情已经得到了控制,基本都是要求你线下面试的,所以没办法就一个人跑过来了。15个小时的硬座,一直做到了第二天八点钟,到站之后赶紧找了个宾馆住下来了,45块一晚上呢,我跟...
最新动态(2024年前)
设备联调3.0功能上线支持深度事件联调,支持老设备反复联调" 创建实验-开始调试 ,加了300ms防抖,多次点击只触发一次 feature示例代码展示undefined 2022年04月07日 V1.9.34版本 功能 【系统管理】数据管理模块合并至系统管理 【可视化实验】多页可视化实验:在一个版本中可以包含多个页面,适用于优化前后有关联的多个页面。 优化&修复: feature(byteio):创建实验时,为应用开启byteio 立即/定时的推送实验的目标受众:事件公共属性...
为君作磐石——人人都能搭建大规模推荐系统
多个目标的预估分来完成排序。 **对推荐系统来说,最核心的工作,便是构建精准的预估模型** 。这些年,业界的推荐模型一直朝着大规模、实时化、精细化的趋势不断演进。大规模是指数据量和模型非常大,训练样本达到百亿... Google 开源的机器学习系统,可以使用P artitioned Variable 来分布式地存储 Embedding,从而实现大规模训练。但由于 table size 固定,有 hash 冲突风险。* **PyTorch**:Facebook 开源的机器学习系统,使用 Ring A...
火山引擎大规模机器学习平台架构设计与应用实践
可以看到不同应用场景下的参数和数据集、模型训练过程中的网络通信带宽、训练资源数和时长都不尽相同。所以面对丰富的机器学习应用,我们的需求是多样的。针对这些需求,底层的计算、存储、网络等基础设施要提供强大的硬件,同时在这些硬件基础上还要提供强大的调度能力,才能为各种需求提供较好的服务,使集群利用率维持在较高水平。模型训练的第二个痛点是偏管理上的。比如在算法问题上,一个方法比另外一好,其中的原因多种多样,可...
