云Firestore变得异常缓慢
 社区干货
社区干货
搞流式计算,大厂也没有什么神话
异常诊断等工具体系。来到 2019 年,流式计算要支撑的业务场景已经相当丰富,扩展到了实时数仓、安全和风控等,并且还在不断增加。单个场景需求也变得更加复杂:推荐业务越来越大,单个作业超过 5 万 Cores;实时数仓业务场景需要 SQL 来开发,且对数据准确性有了更高要求。然而,由于团队人手严重不足,工作进展很是缓慢。“只有两个人,Oncall 轮流值周。不用值周的时候,往往都在解决上一周 Oncall 遗留的问题。”张光辉如此形...
应用性能前端监控,字节跳动这些年经验都在这了
平台可帮助客户发现多类异常问题,并及时报警,做分配处理,同时平台提供了丰富的归因能力,包括且不限于异常分析、多维分析、自定义上报、单点日志查询等,结合灵活的报表能力可了解各类指标的趋势变化。更多功能介绍,... **慢加载列表**列出了加载比较缓慢的页面,方便您进行针对性优化: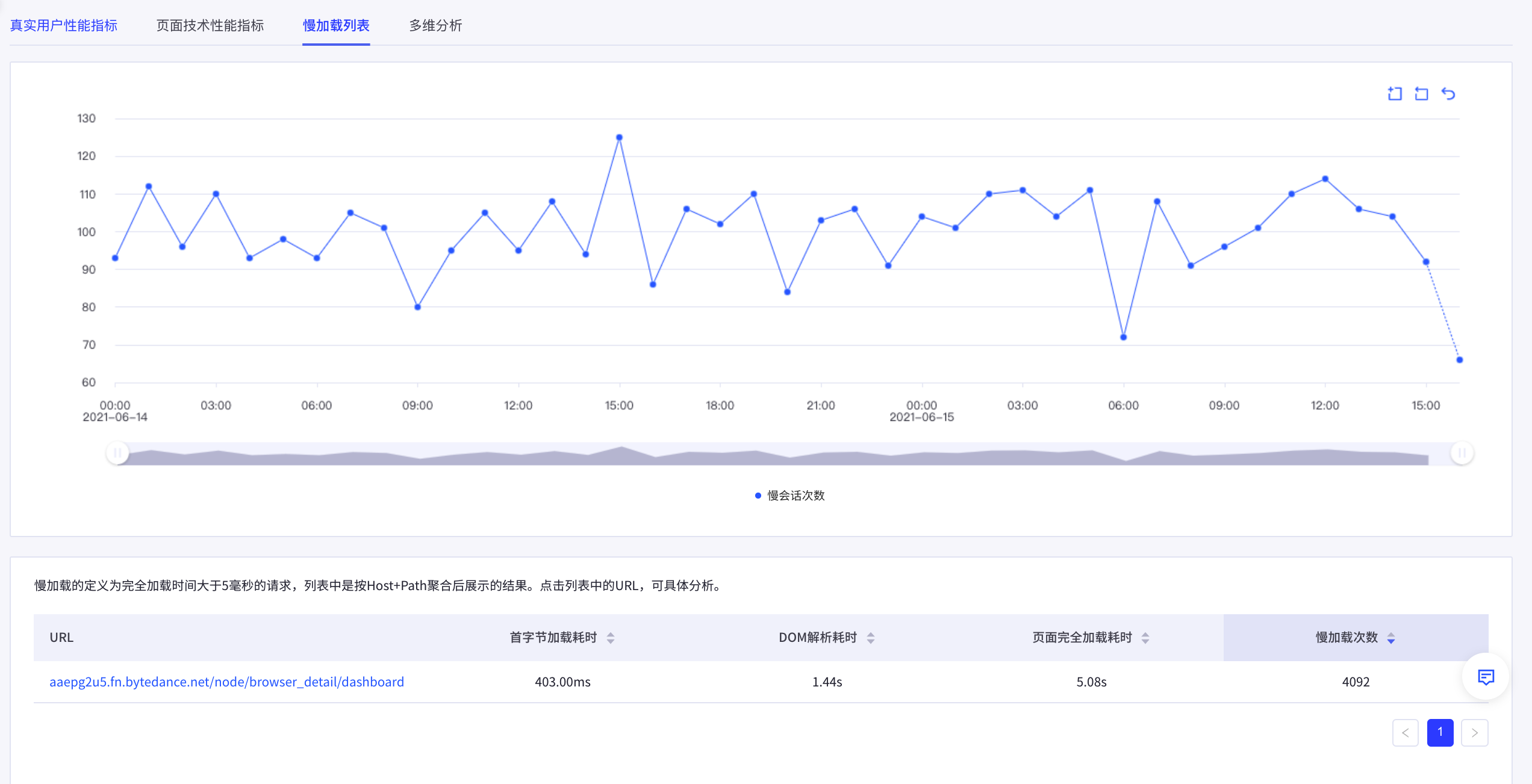在慢加载列表中,给出...
集简云 x 青岛安特翔天丨零代码连接氚云与金蝶云星辰,创新跨系统数据传输的方式
报销费用以及进销存等数据都需要企业人员同步到金蝶云星辰中创建相应的凭证。 **但随着业务不断增长,这个流程开始出现了一些不便之处,尤其是日常处理大量数据的情况下,维护数据同步变得异常困难。具体如下:**... 企业人员在氚云上提交出差/请假/收付款等审批后,审批人需在电脑端登录氚云才可审批单据,经常遇到一个领导在外出差无法及时登录电脑,导致审批流程进展缓慢,阻碍后续工作开展,整个审批流程不灵活,无法实现自动化运转...
搞流式计算,大厂也没有什么神话
异常诊断等工具体系。来到 2019 年,流式计算要支撑的业务场景已经相当丰富,扩展到了实时数仓、安全和风控等,并且还在不断增加。单个场景需求也变得更加复杂:推荐业务越来越大,单个作业超过 5 万 Cores;实时数仓业务场景需要 SQL 来开发,且对数据准确性有了更高要求。然而,由于团队人手严重不足,工作进展很是缓慢。“只有两个人,Oncall 轮流值周。不用值周的时候,往往都在解决上一周 Oncall 遗留的问题。”张光辉如此形容。...
 特惠活动
特惠活动
 云Firestore变得异常缓慢-优选内容
云Firestore变得异常缓慢-优选内容
 云Firestore变得异常缓慢-相关内容
云Firestore变得异常缓慢-相关内容
搞流式计算,大厂也没有什么神话
异常诊断等工具体系。来到 2019 年,流式计算要支撑的业务场景已经相当丰富,扩展到了实时数仓、安全和风控等,并且还在不断增加。单个场景需求也变得更加复杂:推荐业务越来越大,单个作业超过 5 万 Cores;实时数仓业务场景需要 SQL 来开发,且对数据准确性有了更高要求。然而,由于团队人手严重不足,工作进展很是缓慢。“只有两个人,Oncall 轮流值周。不用值周的时候,往往都在解决上一周 Oncall 遗留的问题。”张光辉如此形容。...
探索云原生化的服务架构体系的技术风向,攻克云原生化微服务架构的痛点和特性 | 社区征文
服务2.0时代:系统变得复杂,互联网和移动互联网发展迅猛。解决快速迭代复杂系统的架构成为下一代关键。- 服务3.0时代:云计算提供快速交付资源的基础设施,采用微服务架构提升研发效率,解决复杂系统的难题。-... 多语言发展缓慢、SDK模式重、升级困难等问题。**SDK模式重**:引入了Agent技术(Java字节码增强)缓解了SDK生命周期管理问题,但并未解决多语言问题。##### 解决方案为了解决多语言问题,有两种方案:1. Sideca...
居家办公没有“血泪史”| 社区征文
居家办公变得越来越多,甚至有些公司已经开始永久允许员工在家办公了。这可能就是元宇宙的混沌状态。那么什么是居家办公,百度百科上,是指特定情况下,上班族居家基于互联网处理办公事务的一种办公模式。居家办公在... 但项目推进却异常缓慢。尤其涉及到多方协作的时候,特别需要有效的沟通工具。#### 3) 远程处理问题难去不了客户现场,处理问题只能靠远程。好的情况,客户会给开放个VPN。但多数情况下,都只能以后各种远程软件——...
Cloud Shuffle Service 在字节跳动 Spark 场景的应用实践
异常任务开启限流,不会让任务变慢或失败,大概率会使得任务变快 (限流减少重试,减轻 Server 压力);> 此处有必要解释一下,为什么任务会变得更快呢?原因在于当 Latency 升高时,Chunkr Fetch 开始堆积,大量排队,... 作业 CSS 失败自动 FallBack 到原生 Shuffle## 踩坑记录在实践的过程中,我们也踩了很多坑:### CSS 服务相关- **超大 Register Shuffle 启动缓慢** - 在最初的设计中,Register Shuffle 会对...
Flink OLAP 在字节跳动的查询优化和落地实践
优化这些阶段的耗时就变得非常重要。另外,字节 Flink OLAP 基于存算分离架构,有更加强烈的算子下推需求。另一个挑战是,OLAP 业务要求较高的 QPS,所以当 OLAP 集群频繁地创建和执行作业,某些情况下会导致集群出... 导致查找过程非常缓慢,同时整个 JM 大部分的 CPU 都消耗在这个步骤。通过定位发现,这些 Classloader 都是 UserCodeClassloader,用于动态加载用户的 Jar 包。从图中看出,新 Job 的 JobMaster 和 TM 上该 Job 的...
克服 ClickHouse 运维难题:ByteHouse 水平扩容功能上线
通过该方式实现均衡非常缓慢,可能花费数天乃至数个月才能追平。- 手动在节点之间移动分区,使节点间均衡。该方式需要大表均已设置比较合理的分区键(Partition Key),并且分片键也只能为 Random,并且需要手动计算分... 并且用户表的表结构也异常丰富。因此,社区提供的方案均不能满足字节内部业务诉求。基于以上背景,ByteHouse 自研集群扩容能力,解决自动化流程的问题,也为用户提供了性能开销更低的扩容方式。具体我们通过数据库...
分享远程办公经验,赢取社区大奖!
>> - **火山引擎** **应用性能监控全链路版(APMPlus)** :针对应用服务的品质、性能以及自定义埋点的APM 服务,通过先进的数据采集与监控技术,提供全链路应用性能监控服务,助力提升异常问题排查与解决的效率。申请... 示例:如何排查 RDS for MySQL 查询运行缓慢的问题|社区征文 https://developer.volcengine.com/articles/7047068964626628621 3. 文章评审将根据专家评审得分和文章点赞数量得分加权计算。> **文章得分=专家评...
【模板推荐】小鹅通自动化流程,教育企业提效利器
集简云平台内置大量自动化流程模板,用户可以在“模板中心”搜索应用名称,选择适合自己的场景,直接使用。本期分享 **小鹅通**自动化工作流程。