hbase大批量写入优化
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
并创新地开发出HBase分布式事务处理等新技术,从而推出了Trafodion,并将全部代码开源,贡献给社区。应客户的要求,为了能够让业务系统在国产化环境下性能达到最优,对系统从硬件到软件做了全方位的性能优化,包括BIOS... 读写密集型业务尽可能IO分流。l **网络层面**:提升网络IO速率、尽量减少不必要的网络数据传输。l **应用层面**:提升线程并发数,充分利用CPU的多核特点,降低热点资源竞争、减少或避免锁、微服务化、分布式架构...
大数据学习架构实践|社区征文
适合大规模的数据存储,解决了大批量大规模数据的存储问题。2)HBase列式存储在HDFS基础上,采用了列式存储的HBase数据库,解决了数据稀疏性的问题。并且由于HBase中数据结构的优化,使得快速实时查询在HBase上成为可能。# **4、大数据技术生态**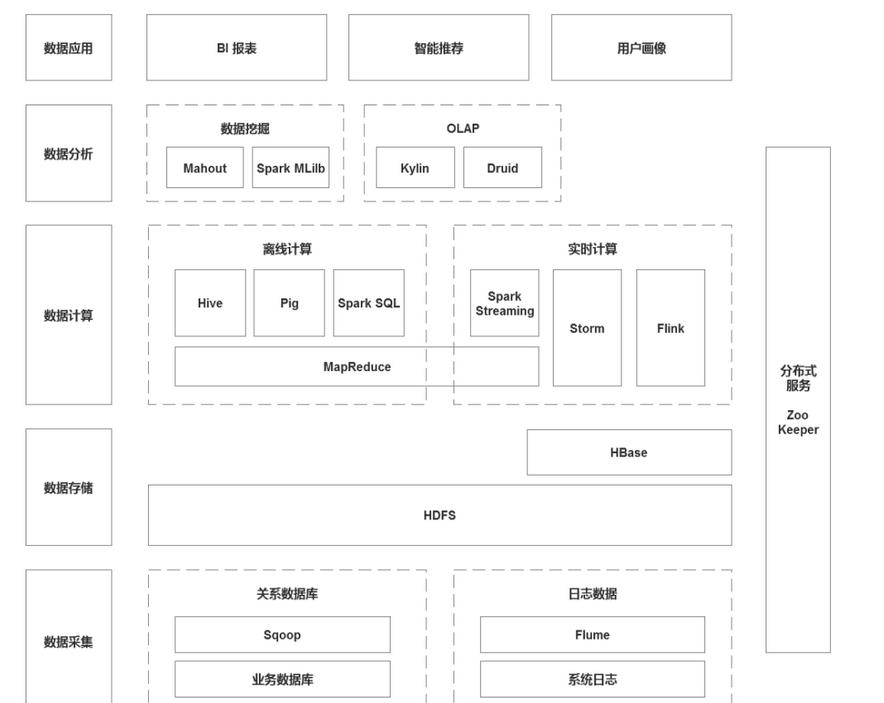## **4.1 数据采集**1)Sqoop:Sqoop是关系型数据...
20000字详解大厂实时数仓建设 | 社区征文
该层主要的工作是把实时汇总数据写入应用系统的数据库中,包括用于大屏显示和实时 OLAP 的 Druid 数据库(该数据库除了写入应用数据,也可以写入明细数据完成汇总指标的计算)中,用于实时数据接口服务的 Hbase 数据库,... 最终写入到了目标 Topic。这个目标 Topic 会导入到 OLAP 引擎,供给多个不同的服务,包括移动版服务,大屏服务,指标看板服务等。这个方案有三个方面的优势,分别是稳定性、时效性和准确性。首先是稳定性。松耦合可...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... **读写分离**1. Ingestion Server 负责数据的导入,Compaction Server 负责将数据定期 Merge。数据导入后,Ingestion Server 会写 WAL,同时数据进入内存 Buffer,Buffer 满了 Flush 成列存文件到 Cloud Store 上,并...
 特惠活动
特惠活动
 hbase大批量写入优化-优选内容
hbase大批量写入优化-优选内容
 hbase大批量写入优化-相关内容
hbase大批量写入优化-相关内容
EMR-3.6.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... HBase集群类型、Flink集群类型、自定义集群类型适配Kerberos,该特性属于白名单功能。 更改、增强和解决的问题【组件】Tez版本升级由0.10.1升级到0.10.2 【组件】Spark组件开箱参数优化,以及内核优化提高SQL执行性...
EMR-3.6.2 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... 在用户管理模块通过IAM用户导入方式导入用户时,修复Ranger中同步的用户名异常问题。 【组件】在管控页面上,对Hive组件服务参数中的元数据库密码进行加密展示。 组件版本 下面列出了 EMR 和此版本一起安装的组件。...
EMR-3.6.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... 并提供开箱参数优化。参考Proton发行版本。 【组件】Flink组件中支持自定义参数功能。 【组件】Kafka组件中支持自定义参数功能。 【组件】Trino组件中修复access-control.properties文件内容。 【组件】修复扩...
EMR-2.2.0 版本说明
HBase集群中集成Knox组件用于访问代理;并集成了YARN和MapReduce2; 【组件】Flink引擎支持avro,csv,debezium-json和avro-confluent等格式; 【组件】修复Presto写入TOS的潜在问题; 【组件】Hive适配CFS, 支持外部... Iceberg适配TOS的读写,支持与PySpark的交互; 【组件】Dolphin Scheduler升级至3.1.3; 【组件】存算分离场景下,优化Spark引擎和MapReudce的写入性能。 已知问题通过Sqoop从SQL Server导入数据时,存在编码异常问题...
基于国产化环境的金融级业务系统性能优化实践|社区征文
并创新地开发出HBase分布式事务处理等新技术,从而推出了Trafodion,并将全部代码开源,贡献给社区。应客户的要求,为了能够让业务系统在国产化环境下性能达到最优,对系统从硬件到软件做了全方位的性能优化,包括BIOS... 读写密集型业务尽可能IO分流。l **网络层面**:提升网络IO速率、尽量减少不必要的网络数据传输。l **应用层面**:提升线程并发数,充分利用CPU的多核特点,降低热点资源竞争、减少或避免锁、微服务化、分布式架构...
EMR-2.4.0 版本说明
Hive 2.3.9 - Spark 2.4.8 - Tez 0.10.1 - Knox 1.5.0 1.5.0 Openldap 2.5.13 2.5.13 Zookeeper 3.7.0 3.7.0 Ossa 1.0.0 - HBase 1.6.0 1.6.0 Flink 1.16.1 - Presto 0.280 - Trino 412 - DolphinScheduler 3.1.7 - Iceberg 1.2.0 - Hudi 0.12.2 - Airflow 2.4.2 - Hue 4.11.0 - Sqoop 1.4.7 - Impala 3.4.1 - Kudu 1.14.0 - Phoenix 4.16.1 4.16.1 Ranger 1.2.0 - Flume 1.9.0 - 发布说明 更改、增强和解决的问题【组件】优化Hi...
EMR-2.1.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - Z... 预计会在后续版本进行优化; 使用YARN session模式下会偶现YARN Application中断,如果遇到可使用其他模式进行作业提交Flink作业或者联系售后进行处理; Hue上传文件转Hive表,编辑Field可能出现不生效的场景,如需要...
大数据学习架构实践|社区征文
适合大规模的数据存储,解决了大批量大规模数据的存储问题。2)HBase列式存储在HDFS基础上,采用了列式存储的HBase数据库,解决了数据稀疏性的问题。并且由于HBase中数据结构的优化,使得快速实时查询在HBase上成为可能。# **4、大数据技术生态**## **4.1 数据采集**1)Sqoop:Sqoop是关系型数据...
EMR-3.2.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集... 修复Presto写入TOS的潜在问题; 【集群】Kafka集群高可用优化,修复潜在的内置组件出现单点问题导致集群操作异常问题; 【组件】Flink升级至1.16.0,引入StarRocks、Doris、HBase和ByteHouse Connector,支持MySQL Si...
