hbase单独启动节点
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 节点是 Data Node。Data Node 负责实际的数据存储和读取。用户文件被切分成块,复制成多副本,每个副本都存在不同的 Data Node 上,以达到容错容灾的效果。每个副本在 Data Node 上都以文件的形式存储,元信息在启动时...
2022技术盘点之平台云原生架构演进之道|社区征文
动态分配临时 Runner 到空闲的节点上创建,降低出现因某节点资源利用率高,还排队等待在该节点的情况。- 扩展性好:当 Kubernetes 集群的资源严重不足而导致临时 Runner 排队等待时,可以很容易的添加一个 Kubernetes Node 到集群中,从而实现横向扩展。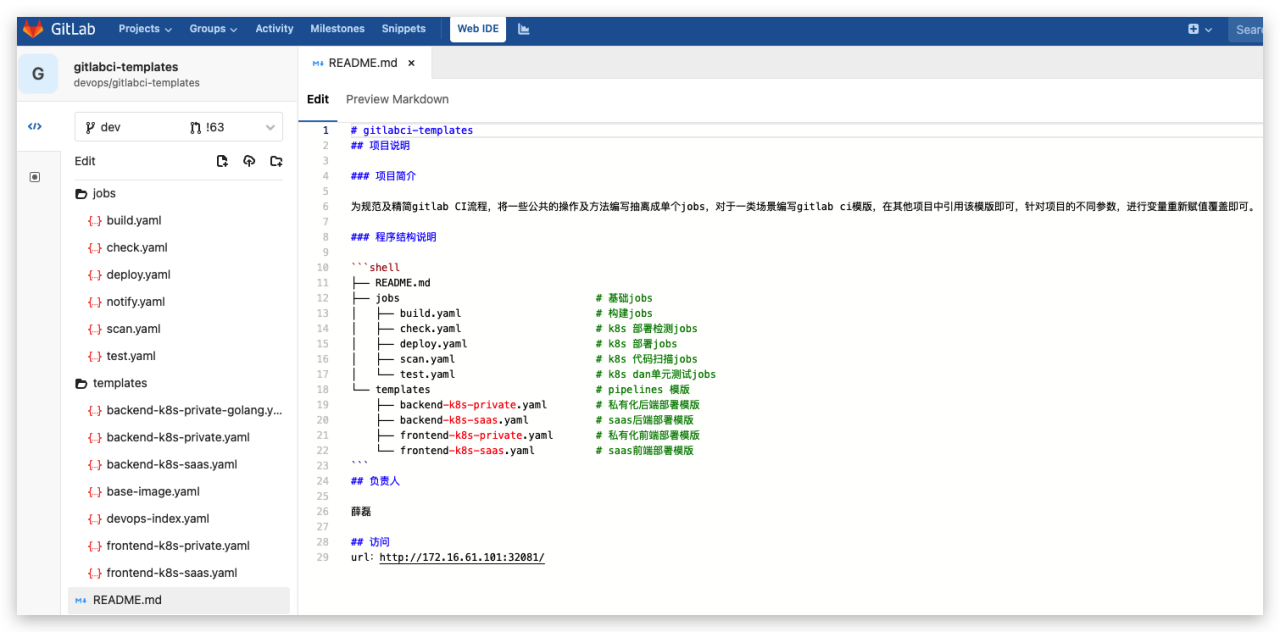利用Gitlab CI 共享模块库,可最大程度实现CI代码复用性。### 3.2 DevOp...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储* Yarn,Flink 的计算框架平台数据* Spark,MapReduce 的计算相关数据存储**02****字节跳动特色的 HDFS 架构**在深入相关的技术细节之前,我... 节点是 Data Node。Data Node 负责实际的数据存储和读取。用户文件被切分成块,复制成多副本,每个副本都存在不同的 Data Node 上,以达到容错容灾的效果。每个副本在 Data Node 上都以文件的形式存储,元信息在启动时...
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续... 提升NUMA节点和内存数据的命中率、尽量减少CPU中断和上下文切换。l **内存层面**:尽可能提升内存数据命中率和访存速率、NUMA节点内CPU核心尽可能访存节点内内存数据。l **磁盘层面**:提升磁盘IO吞吐率、读写...
 特惠活动
特惠活动
 hbase单独启动节点-优选内容
hbase单独启动节点-优选内容
 hbase单独启动节点-相关内容
hbase单独启动节点-相关内容
更改节点规格
本文介绍如何更改 HBase 实例的节点规格。 注意事项更改节点规格过程中,实例可能会出现 1~3 分钟的断连。请谨慎操作。建议在业务低峰期执行变配操作,并确保客户端配置了正确的重试机制。 Master 节点与 Region Server 节点的规格可以同升同降,也可以一升一降,或仅变更其中一种节点的规格。 操作步骤登录 HBase 控制台。 在顶部菜单栏的左上角,选择实例所属的地域。 在实例列表页,单击目标实例名称。 在实例信息页的配置信息...
增减节点数量
本文介绍如何增减 HBase 实例 Region Server 的节点数量。 注意事项仅支持增减 Region Server 节点的数量,节点数量范围为 2~100 个。Master 节点数量固定为 2,不支持增减。 缩减节点数量过程中实例可能会出现 1~3 分钟的断连。请谨慎操作。建议在业务低峰期执行变配操作,并确保客户端配置了正确的重试机制。 操作步骤登录 HBase 控制台。 在顶部菜单栏的左上角,选择实例所属的地域。 您可以通过以下任意一种方式进入增减节点...
EMR-2.4.0 版本说明
Tez 0.10.1 - Knox 1.5.0 1.5.0 Openldap 2.5.13 2.5.13 Zookeeper 3.7.0 3.7.0 Ossa 1.0.0 - HBase 1.6.0 1.6.0 Flink 1.16.1 - Presto 0.280 - Trino 412 - DolphinScheduler 3.1.7 - Iceberg 1.2.0 - Hudi 0.12.2 - Airflow 2.4.2 - Hue 4.11.0 - Sqoop 1.4.7 - Impala 3.4.1 - Kudu 1.14.0 - Phoenix 4.16.1 4.16.1 Ranger 1.2.0 - Flume 1.9.0 - 发布说明 更改、增强和解决的问题【组件】优化Hive on Tez的任务启动流程,加...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 节点是 Data Node。Data Node 负责实际的数据存储和读取。用户文件被切分成块,复制成多副本,每个副本都存在不同的 Data Node 上,以达到容错容灾的效果。每个副本在 Data Node 上都以文件的形式存储,元信息在启动时...
EMR 1.3.1版本说明
Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本remote_base_log_folder Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集群 TensorFlow集群 Doris集群 Puls... 集群服务上下线:支持将某一节点上的一个组件下线(当组件实例数达到最小数量限制时就不能再继续下线)。 【组件】Trino Bloom索引增强,包括 支持在CREATE INDEX时,为Bloom索引设置roperties参数; 只支持对Iceberg表...
EMR-3.0.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集... 不再依赖/etc/hosts: 集群内通信可以使用长短hostname:emr-master-1和emr-2tfyq6eeoq5g1j17w0zo-master-1 集群所在VPC内与集群内ECS通信可以使用完整的域名(见节点管理-节点组列表的DNS列)如:emr-2tfyq6eeoq5g1j1...
EMR 1.2.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本组件 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSear... 安装启动服务时,为了避免随机端口占有组件的端口号, 已为各组件预留了端口号。 Hadoop集群HA模式增强:MASTER从2个节点变成3个节点,增强Hadoop集群下各个组件的高可用性。 新增守护精灵的功能, 对于组件进程的异...
EMR-3.5.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 S... 优化Hive on Tez的任务启动流程,加载本地jar到ClassPath,替换从HDFS下载。 【组件】StarRocks组件适配火山云对象存储TOS服务,同时该组件中增加CN服务。 【组件】Hue组件版本由4.10.0升级至4.11.0版本。 【组件】...
EMR 1.3.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本组件 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSear... 可以通过手工启动集群服务解决,实现集群的正常运行。 组件版本 下面列出了 EMR 和此版本一起安装的组件。 组件 版本 描述 zookeeper_server 3.7.0 用于维护配置信息、命名、提供分布式同步的集中式服务。 zookeepe...
