hbase没有主键怎么查
 社区干货
社区干货
字节跳动基于 Hudi 的实时数据湖平台
Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group 中。底层存储由多个 file group 构成,有其特定的 file ID。File group 内的文件分为 base file 和 log file, log file 记录对 b... Hbase index 以及 Bucket Index,其中 **Bucket Index 尚未合并到主分支**。 ## 字节跳动基于Hudi的实时数据湖平台 字节跳动基于 Hudi 的实时数据湖平台,通过秒级数据可见支持实时数仓。除了提供 Hud...
揭秘|字节跳动基于Hudi的实时数据湖平台
Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group中。底层存储由多个 file group 构成,有其特定的 file ID。File group 内的文件分为 base file 和 log file, log file 记录对 ba... Hbase index 以及 Bucket Index,其中 **Bucket Index 尚未合并到主分支**。 字节跳动基于Hudi的实时数据湖平台 字节跳动基于 Hudi 的实时数据湖平台,通过...
揭秘|字节跳动基于Hudi的实时数据湖平台
需要将数据从类 Hbase的存储导出到离线存储中,并且可以提供高效的 OLAP 访问。因此我们基于数据湖构建BigTable 的 CDC。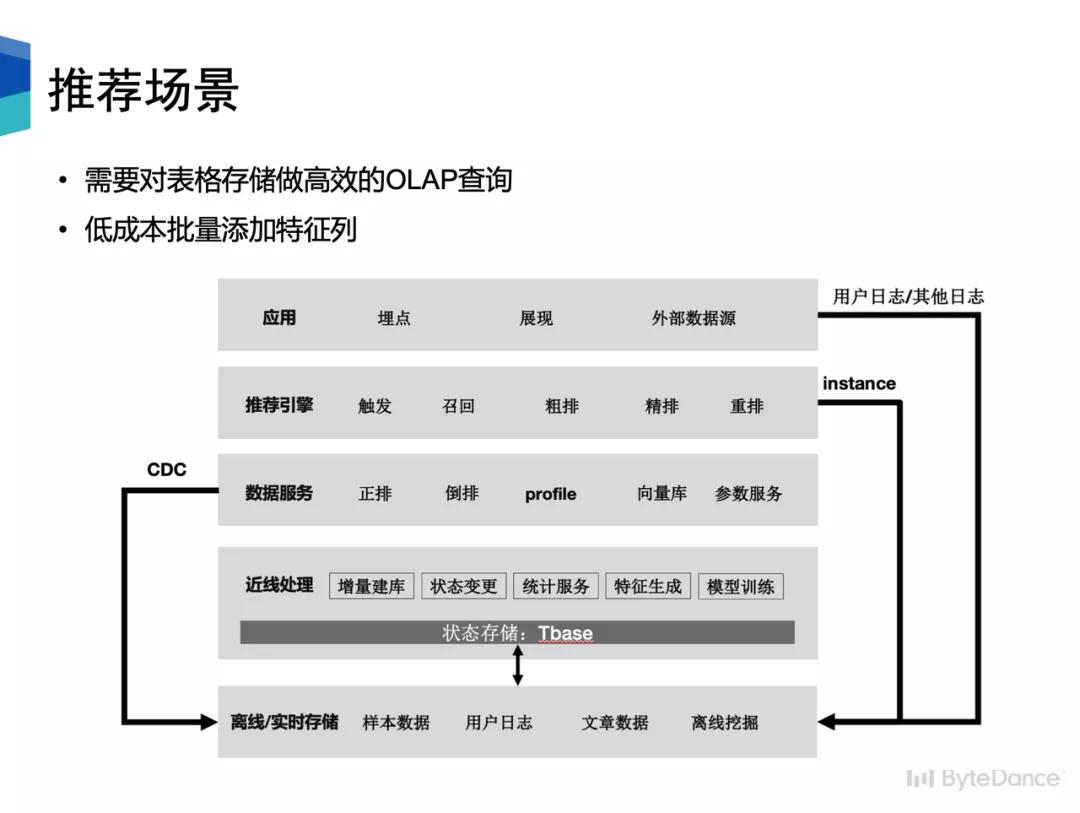此外,在特征工程和模型训练场景中,需要将推荐系统 Serving 时获得的数据和端上埋点数据这两类实时数据流通过主键合并到一起,作为机器学习样本。因此我们希望可以借助数据湖...
字节跳动基于 Hudi 的机器学习应用场景
秒级的点查;高效的谓词下推查询能力;存在基于主键/外建的 join。在写方面需支持以下能力:基于主键的 upsert;针对部分 cell 的插入与更新;针对行/列/cell 的删除;基于外键的 upsert。在这样的背景下,我们了解 H... 这个方案受到了经典 BigTable 存储 Apache HBase 的启发,将 IO pattern 不同的数据使用不同的文件进行存储,以减少不必要的读写放大。原理是将同一个 FileGroup 的不同列数据存储在不同的文件中,在读时进行合并。这...
 特惠活动
特惠活动
 hbase没有主键怎么查-优选内容
hbase没有主键怎么查-优选内容
 hbase没有主键怎么查-相关内容
hbase没有主键怎么查-相关内容
揭秘|字节跳动基于Hudi的实时数据湖平台
需要将数据从类 Hbase的存储导出到离线存储中,并且可以提供高效的 OLAP 访问。因此我们基于数据湖构建BigTable 的 CDC。此外,在特征工程和模型训练场景中,需要将推荐系统 Serving 时获得的数据和端上埋点数据这两类实时数据流通过主键合并到一起,作为机器学习样本。因此我们希望可以借助数据湖...
字节跳动基于 Hudi 的机器学习应用场景
秒级的点查;高效的谓词下推查询能力;存在基于主键/外建的 join。在写方面需支持以下能力:基于主键的 upsert;针对部分 cell 的插入与更新;针对行/列/cell 的删除;基于外键的 upsert。在这样的背景下,我们了解 H... 这个方案受到了经典 BigTable 存储 Apache HBase 的启发,将 IO pattern 不同的数据使用不同的文件进行存储,以减少不必要的读写放大。原理是将同一个 FileGroup 的不同列数据存储在不同的文件中,在读时进行合并。这...
案例 | 火山引擎 EMR StarRocks 在旅游和广告行业中的应用
实时同步到 Primary key 主键模型中同时提供高并发的查询服务。此外,StarRocks 还支持联邦查询,可以无缝同步外部 Catalog,包括 Hive、Iceberg、Hudi、Delta lake 的外表,实现离线和实时的统一、湖和仓的联邦分析... 然后持久化到 HBase 中。这套历史框架给客户带来了许多困扰:1. Cube 定义成本高:增加一个 Cube 数据的成本较高,需要配置各种任务;1. 运维成本高:Kylin 依赖组件多,需要管理 Hive/Spark,HBase,调度平台的可用性...
字节跳动数据湖索引演进
引入了索引的概念:索引将数据的主键与文件名进行映射,可以快速找到未更新数据所在的文件,有效地减少读取和写入文件的数量。当源头数据中的记录存在主键重复的情况下,需要保留最新一条数据即可。****(4)在分析侧,业务会基于 Hudi 数据集,通过 Presto/Spark 查询引擎,构建可视化的 BI 报表看板,供运营或分析师自助进行近实时数据分析...
