hbase3层结构的顺序
 社区干货
社区干货
20000字详解大厂实时数仓建设 | 社区征文
数仓具体架构如下图所示: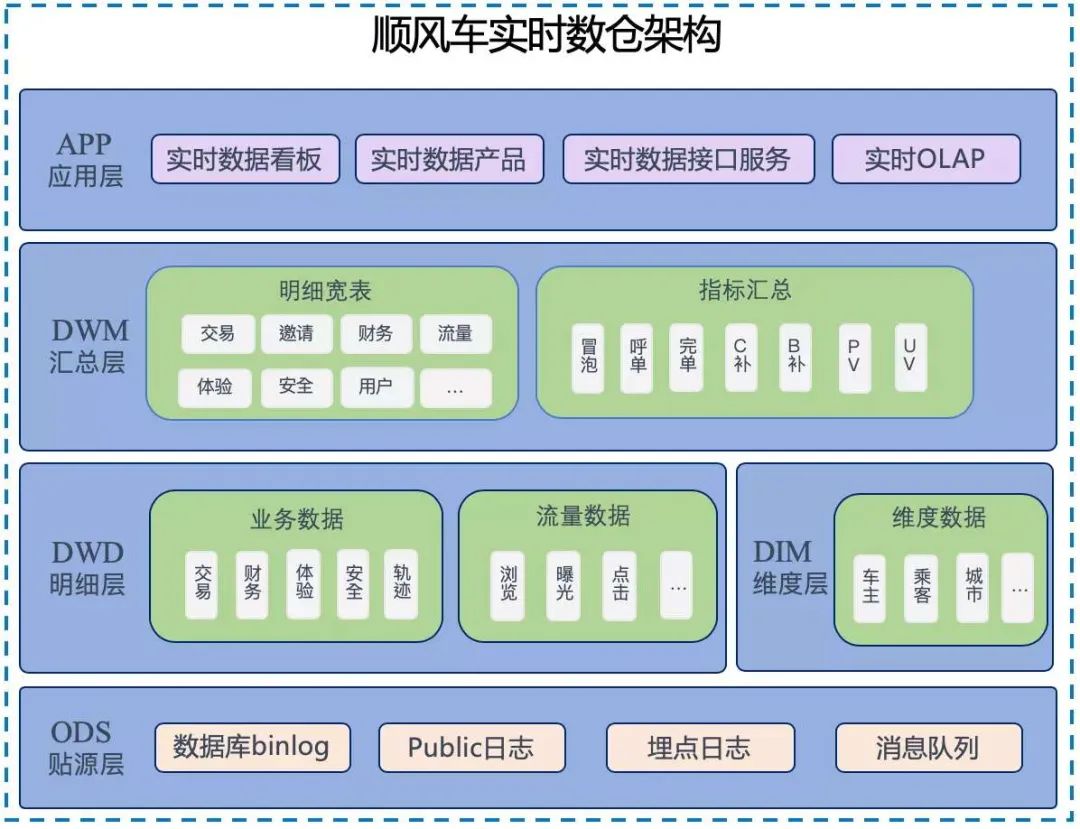从数据架构图来看,顺风车实时数仓和对应的离线数仓有很多类似的地方。例如分层结构;比如 ODS 层,明细层,汇总层,乃至应用... 渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要...
基于国产化环境的金融级业务系统性能优化实践|社区征文
系统总体架构设计如下所示: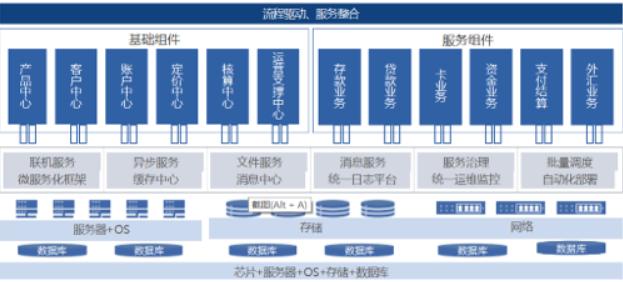- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
Wherehows架构相对简单,采用Backend + ETL的模式。初期版本,主要利用Wherehows的存储设计和ETL框架,自研实现前后端的功能模块。随着字节跳动业务的快速发展, 公司内各类存储引擎不断引入,数据生产者和消费者的痛... ### 存储层针对不同场景,选用的不同的存储:- Meta Store:存放全量元数据和血缘关系,当前使用的是HBase- Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch- Model St...
干货 | 字节跳动构建Data Catalog数据目录系统的实践(下)
[上篇围绕Data Catalog调研思路及技术架构展开。](http://mp.weixin.qq.com/s?__biz=MzkwMzMwOTQwMg==&mid=2247492653&idx=1&sn=2a74b3c1908049ad320a9b2b1b8e202e&chksm=c09a9518f7ed1c0e7cc8dcbaa7e23d29b2f9020... 以我们定义过的目录结构和先后顺序加载。这也为后面的标准化奠定了基础。**02 -****数据接入标准化**为了最终达成降低接入和维护成本的目标,统一了类型系统之后,第二步就是接入流程的标准化。我...
 特惠活动
特惠活动
 hbase3层结构的顺序-优选内容
hbase3层结构的顺序-优选内容
 hbase3层结构的顺序-相关内容
hbase3层结构的顺序-相关内容
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
Wherehows架构相对简单,采用Backend + ETL的模式。初期版本,主要利用Wherehows的存储设计和ETL框架,自研实现前后端的功能模块。随着字节跳动业务的快速发展, 公司内各类存储引擎不断引入,数据生产者和消费者的痛... ### 存储层针对不同场景,选用的不同的存储:- Meta Store:存放全量元数据和血缘关系,当前使用的是HBase- Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch- Model St...
干货 | 字节跳动构建Data Catalog数据目录系统的实践(下)
[上篇围绕Data Catalog调研思路及技术架构展开。](http://mp.weixin.qq.com/s?__biz=MzkwMzMwOTQwMg==&mid=2247492653&idx=1&sn=2a74b3c1908049ad320a9b2b1b8e202e&chksm=c09a9518f7ed1c0e7cc8dcbaa7e23d29b2f9020... 以我们定义过的目录结构和先后顺序加载。这也为后面的标准化奠定了基础。**02 -****数据接入标准化**为了最终达成降低接入和维护成本的目标,统一了类型系统之后,第二步就是接入流程的标准化。我...
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
以我们定义过的目录结构和先后顺序加载。这也为后面的标准化奠定了基础。## 数据接入标准化为了最终达成降低接入和维护成本的目标,统一了类型系统之后,第二步就是接入流程的标准化。火山引擎 DataLeap 研发人... =&rk3s=8031ce6d&x-expires=1714926084&x-signature=QUFnjw4hNCcZTvvM8ABT6O6Vx7E%3D)火山引擎 DataLeap 研发人员设计的元数据搜索,架构如上图所示。粗略来看,可以划分为两大部分:- 离线部分:负责汇集各类与...
9年演进史:字节跳动 10EB 级大数据存储实战
顺序和随机读 - 超大数据规模 - 易扩展,容错率高## HDFS 在字节跳动的发展字节跳动已经应用 HDFS 非常长的时间了。经历了 9 年的发展,目前已直接支持了十多种数据平台,间接支持了上百种业务发展。从集... HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H...
我的大数据学习总结 |社区征文
HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学习分布式原理和架构也很重要。这个学习顺序参考了我之前的工作和学习经历情况后订定。需要注意,大数据领域的技术很多很广,如Flink也值得研究。本人给出的仅作为一个参考案例,学习者还需结合实际情况选择合适的学习路径。。更新后,支持用户快速创建具有排除条件的分群包,使得新建分群包结果含义为人群不属于event_x 的用户。举例说明: 为了筛选出全量用户中最近7天小程序活动互动>3次,但没... 从下到上增序排列的排列顺序。*注意事项:使用时请选择按标签排序 项目中心 更新类型 功能描述 产品截图说明 新增 项目中心新增在线服务模块,支持对在线服务任务进行管理,主要新增功能包括: 任务状态查询:用...
干货|DataLeap数据资产实战:如何实现存储优化?
=&rk3s=8031ce6d&x-expires=1714926045&x-signature=pekjigB%2Bc3efaZoU6voXs8F%2FB2E%3D) **●**因投入成本过高,我们不接受自己运维有状态集群,排除了HBase和Cassandra;=============================... 表结构是4列(id, g\_key, g\_column, g\_value),除自增ID外, **对应key-column-value model的数据模型,key+column是一个聚集索引。**========================================================================...
[数据库系统] 业界列式存储浅析
两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况下,数据一般采用一个一个的数据块进行存储,利用顺序读写提升性能。行存的实现一般是将一行数据完整的从头到尾连续存储(超长的字段一般会单独存储,行内记录逻辑地址),连续多行构成一个页,页的尾部通常会存储索引来解决record不定长时的快速查找问题,数据排列结构如下图所示:如图所示,Krypton 支持两层分区,第一层叫做 Partition,第二层我们称为 Tablet,每一层都支持 Range/Hash/List 的分区策略。每...
