hbase存储空间计算
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... Data Node 负责实际的数据存储和读取。用户文件被切分成块,复制成多副本,每个副本都存在不同的 Data Node 上,以达到容错容灾的效果。每个副本在 Data Node 上都以文件的形式存储,元信息在启动时被加载到内存中。...
一文读懂火山引擎云数据库产品及选型
或者需要更大的数据容量,那么也需要同时考虑数据库的可扩展性,通过扩展来获取更强的数据处理能力以及更大的数据存储空间,以保证业务应用可以平稳运行。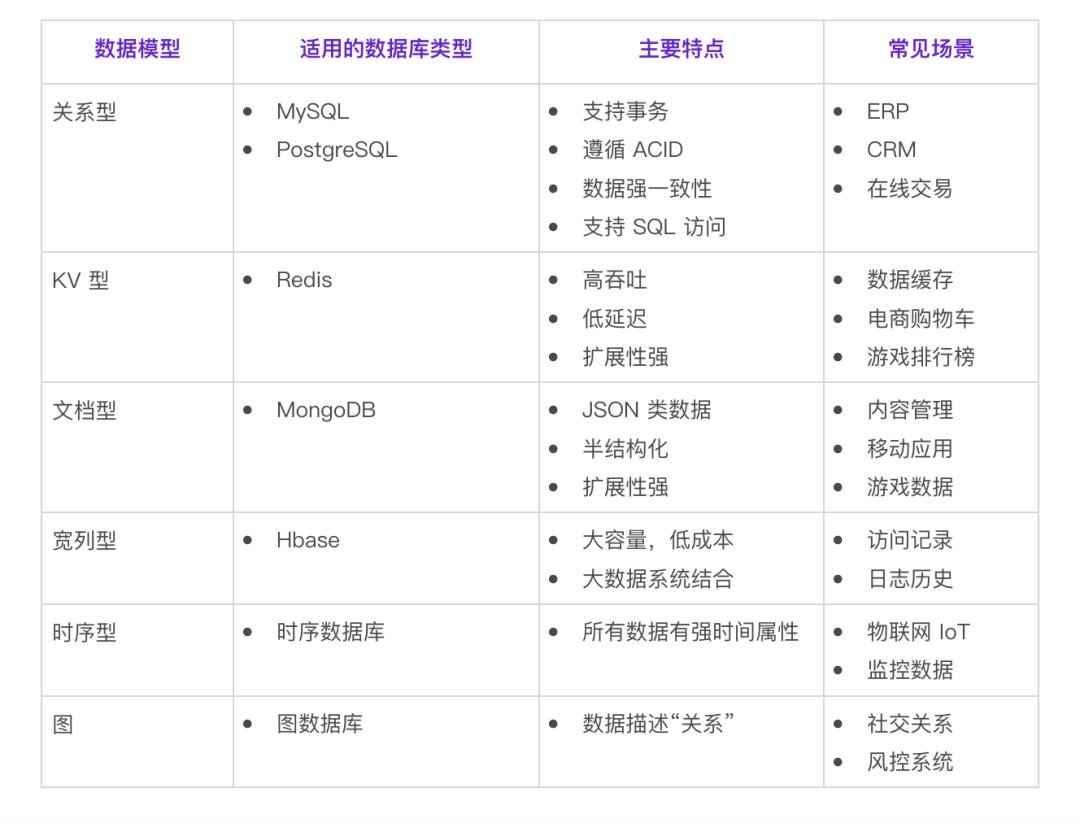## 火山引擎云数据库选型参考火山引擎云数据库提供了丰富的云数据库产品类型,包括开源数据库与自研数据库,同时也提供了完整的数据库生态服务...
「火山引擎」数据中台产品双月刊 VOL.04
帮助用户节约计算资源。的训练和推理,同时支持内存/SSD 混合介质的数...
 特惠活动
特惠活动
 hbase存储空间计算-优选内容
hbase存储空间计算-优选内容
 hbase存储空间计算-相关内容
hbase存储空间计算-相关内容
什么是表格数据库 HBase 版
火山引擎表格数据库 HBase 版是基于 Apache HBase 提供的全托管 NoSQL 服务,兼容标准 HBase 访问协议,具备低成本存储、高扩展吞吐等优势。 产品架构 如上图所示,表格数据库 HBase 版主要由 Master、RegionServer、ZooKeeper、HDFS 四部分组成: Master:Master 负责管理和协调 RegionServer,以及管理表的增删改查操作。每个 HBase 实例默认只能创建 2 个 Master 节点(主备)。 RegionServer:RegionServer 负责存放和管理 HRegion,以...
变配和退订说明
那么该实例的计算节点在这一小时内产生的使用费用为 10.32 元,详情如下: 前 30 分钟:(1.72 元/小时/节点 ÷ 3600 秒 × 60 秒 × 30 分钟)× 4 个节点 = 3.44 元 后 30 分钟:(3.44 元/小时/节点 ÷ 3600 秒 × 60 秒 × 30 分钟)× 4 个节点 = 6.88 元 总费用:3.44 元 + 6.88 元 = 10.32 元 说明 存储空间的使用费用不受配置变更的影响。 包年包月包年包月实例的配置变更分为资源升配、资源降配两种。 升配:在变更资源规格时,新...
HBase
String 传递给 HBase 的配置参数,如需了解具体的参数,请参见HBase Default Configuration。Flink 会将properties.删除,将剩余配置传递给底层 HBase 客户端。示例:'properties.hbase.security.authentication' = 'kerberos' 配置 Kerberos 认证。 结果表参数参数 是否必选 默认值 数据类型 描述 sink.buffer-flush.max-size 否 2mb MemorySize 写入 HBase 前,内存中缓存的数据量大小。调大该值有利于提高 HBase 的写...
配置 HBase 数据源
DataSail 中的 HBase 数据源为您提供读取和写入 HBase 的双向通道数据集成能力,实现不同数据源与 HBase 之间进行数据传输。下文为您介绍 HBase 数据同步的能力支持情况。 1 支持的版本HBase 使用的驱动版本是 HBas... *数据源名称 已在数据源管理中注册成功的 HBase 数据源,下拉可选。若还未建立相应数据源,可单击数据源管理按钮,前往创建 HBase 数据源。 *命名空间 下拉选择对应 HBase 数据源下存在的 namespace 空间。 *数...
开通容量型存储
容量型存储可作为冷数据存储介质,用于存储低频使用的数据,价格比普通存储介质更优惠。本文介绍如何开通容量型存储。 前提条件为已有实例开通容量型存储时,实例的状态必须为运行中。 操作步骤您可以选择以下任意一种方式开通容量型存储。 方式一:在创建实例时开通容量型存储 在创建实例时,选择开通容量型存储空间,详情请参见创建实例。 方式二:为已有实例开通容量型存储 登录 HBase 控制台。 在顶部菜单栏的左上角,选择实例所属...
服务概述
各服务指标及说明HDFS指标类型 说明 容量信息 展示存储空间的整体使用量 健康度 展示集群的块损坏,副本丢失等情况,用于维护 节点信息 展示集群的节点信息 NameNode RPC 端口上的调用队列长度 显示 NameNode 的 R... 内存状态 展示集群内存的状态,包括总量,已用量和剩余量。 任务状态 统计 YARN 中的任务的状态,包括提交的任务数,运行中的任务数,处于 Pending 状态的任务,运行完任务数,被杀死的任务数和执行失败的任务数。 HBase指...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... Data Node 负责实际的数据存储和读取。用户文件被切分成块,复制成多副本,每个副本都存在不同的 Data Node 上,以达到容错容灾的效果。每个副本在 Data Node 上都以文件的形式存储,元信息在启动时被加载到内存中。...
EMR-2.1.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - Z... hive_metastore 2.3.9 Hive元数据存储服务。 hive_server 2.3.9 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 2.3.9 Hive命令行客户端。 hdfs_namenode 2.10.2 用于跟踪HDFS文件名和数据块的服务。 hd...
EMR-2.4.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 HDFS 2.10.2 2.10.2 YARN 2.10.2 2.10.2 MapReduce2 2.10... hive_metastore 2.3.9 Hive元数据存储服务。 hive_server 2.3.9 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 2.3.9 Hive命令行客户端。 hdfs_namenode 2.10.2 用于跟踪HDFS文件名和数据块的服务。 hd...
