hbase宽表split
 社区干货
社区干货
一文读懂火山引擎云数据库产品及选型
其中主流的商业关系型数据库代表有 Oracle、SQL Server、DB2 等;主流的开源关系型数据库代表有 MySQL、PostgreSQL、MariaDB 等。**NoSQL**,Not Only SQL,"不仅仅是 SQL",广泛应用于以互联网业务为代表的场景。NoSQL 数据库又可以**细分为 KV 型 NoSQL 数据库(以 Redis 为代表)、文档型 NoSQL 数据库(以 MongoDB 为代表)、宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以...
干货 | 这样做,能快速构建企业级数据湖仓
分析实时化的表现有(近)实时引擎和流引擎。 * **(近)实时引擎**+ ClickHouse:近实时 OLAP 引擎,宽表查询性能优异+ Doris:近实时全场景 OLAP 引擎+ Druid:牺牲明细查询,将 OLAP 实时化,毫秒级返回* **流引... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
基于火山引擎 EMR 构建企业级数据湖仓
分析实时化的表现有(近)实时引擎和流引擎。- (近)实时引擎 - ClickHouse:近实时 OLAP 引擎,宽表查询性能优异 - Doris:近实时全场景 OLAP 引擎 - Druid:牺牲明细查询,将 OLAP 实时化,毫秒级... 然后把提取出来的特征再返存到湖仓或者 HBase 等键值存储。 基于这些离线的数据可以进行离线训练,比如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
基于es倒排索引+宽表模型,数据检索性能大幅度提升,上一组案例效果。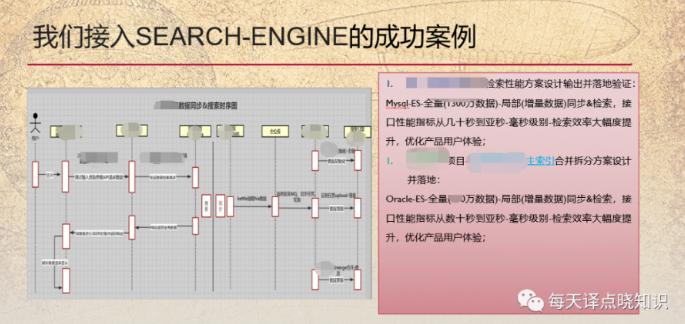随着查询越... HBase、Vertica、Impala、Greenplum、 ClickHouse. 其中,**Hive:** 使用一种类似SQL查询语言,作用在分布式存储系统的文件之上,通常用于进行离线数据处理操作-MapReduce,支持多种不同的执行引擎-Hive on Ma...
 特惠活动
特惠活动
 hbase宽表split-优选内容
hbase宽表split-优选内容
 hbase宽表split-相关内容
hbase宽表split-相关内容
基于火山引擎 EMR 构建企业级数据湖仓
分析实时化的表现有(近)实时引擎和流引擎。- (近)实时引擎 - ClickHouse:近实时 OLAP 引擎,宽表查询性能优异 - Doris:近实时全场景 OLAP 引擎 - Druid:牺牲明细查询,将 OLAP 实时化,毫秒级... 然后把提取出来的特征再返存到湖仓或者 HBase 等键值存储。 基于这些离线的数据可以进行离线训练,比如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
基于es倒排索引+宽表模型,数据检索性能大幅度提升,上一组案例效果。随着查询越... HBase、Vertica、Impala、Greenplum、 ClickHouse. 其中,**Hive:** 使用一种类似SQL查询语言,作用在分布式存储系统的文件之上,通常用于进行离线数据处理操作-MapReduce,支持多种不同的执行引擎-Hive on Ma...
20000字详解大厂实时数仓建设 | 社区征文
同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时... 构建最细粒度的明细层事实表;结合顺风车分析师在离线侧的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,完成宽表化处理,之后基于当前顺风车业务方对实时数据的需求重点,重点建设交易、财务、体验、安...
一文读懂火山引擎云数据库产品及选型
其中主流的商业关系型数据库代表有Oracle、SQL Server、DB2等;主流的开源关系型数据库代表有MySQL、PostgreSQL、MariaDB等。NoSQL,**N**ot **O**nly **SQL**,"不仅仅是SQL",广泛应用于以互联网业务为代表的场景。NoSQL数据库又可以细分为KV型NoSQL数据库(以Redis为代表)、文档型NoSQL数据库(以MongoDB为代表)、宽列型NoSQL数据库(以HBase为代表)、时序型NoSQL数据库(以InfluxDB为代表)以及图NoSQL数据库(以Neo4j为代表)。虽然这...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBase 发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。 | 重量级,Record Key ... Split 的,单个 File Group 数据过大将导致查询并发降低,性能下降。 **一般说来建议单个桶的大小控制在 3 GB 左右。**- 同时我们也应该避免桶的数量过多,过多的桶数量则会造成单个桶的数据量太小,造成小文件情况...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBase 发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。 | 重量级,Record Key 到 Fil... Split 的,单个 File Group 数据过大将导致查询并发降低,性能下降。 **一般说来建议单个桶的大小控制在 3GB 左右。*** 同时我们也应该避免桶的数量过多,过多的桶数量则会造成单个桶的数据量太小,造成小文件情况。...
干货|Hudi Bucket Index 在字节跳动的设计与实践
Hbase index 类型,但在字节跳动大规模数据入湖、探索分析等场景中,我们仍然碰到了现有索引类型无法解决的挑战,因此在实践中我们开发了 Bucket Index 的索引方式。## 业务场景挑战字节跳动某业务部门需要利用实... Split 的,单个 File Group 数据过大将导致查询并发降低,性能下降。 **一般说来建议单个桶的大小控制在 3GB 左右。**- 同时我们也应该避免桶的数量过多,过多的桶数量则会造成单个桶的数据量太小,造成小文件情况。...
一文读懂火山引擎云数据库产品及选型
其中主流的商业关系型数据库代表有 Oracle、SQL Server、DB2 等;主流的开源关系型数据库代表有 MySQL、PostgreSQL、MariaDB 等。**NoSQL**,Not Only SQL,"不仅仅是 SQL",广泛应用于以互联网业务为代表的场景。NoSQL 数据库又可以 **细分为 KV 型 NoSQL 数据库(以 Redis 为代表)、文档型 NoSQL 数据库(以 MongoDB 为代表)、宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据...
Hudi Bucket Index 在字节跳动的设计与实践
**HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBase 发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。 | 重量级,Record Key 到 File... 表的目标大小和未来数据增长情况。* **桶的数量过小会降低整体引擎的并行速度**,原因不难理解:当数据量增大时, 单个 File Group 对应的数据将增大,而 Hudi 表是以 File Group 为单位将数据切割生成 inputSplit ...
