hbase写数据的并发数
 社区干货
社区干货
揭秘|字节跳动基于Hudi的实时数据湖平台
Hudi 通过索引快速定位数据所属的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index,其中 **Bucket Index 尚未合并到主分支**。 字节跳动基于Hudi的实时数据湖平台 字节跳动基于 Hudi 的实时数据湖平台,通过秒级数据可见支持实时数仓。除了提供 Hudi 社区的所有功能外,还支持基于数据湖的元数据管理系统、行列级别的并发更新、Bucket ...
字节跳动实时数据湖构建的探索和实践
量会比较大,新增的数据量通常相比底表会比较小。在这种场景下,我们可以**选用哈希索引、State索引和Hbase索引来做到高效率的全局索引**。这两个例子说明了不同场景下,索引的选择也会决定了整个表读写性能。Hudi提供多种开箱即用的索引,已经覆盖了绝大部分场景,用户使用成本非常低。### 02 - Merge On Read表格式除了索引系统之外,Hudi的Merge On Read表格式也是一个我们看重的核心功能之一。这种表格式让实时写入、近实时...
揭秘|字节跳动基于Hudi的实时数据湖平台
**COW 表:** 适用于离线批量更新场景,对于更新数据,会先读取旧的 base file,然后合并更新数据,生成新的 base file。- **MOR 表**:适用于实时高频更新场景,更新数据会直接写入 log file 中,读时再进行合并。为了减少读放大的问题,会定期合并 log file 到 base file 中。对于更新数据,Hudi 通过索引快速定位数据所属的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index,其中 **Bucket Ind...
字节跳动基于 Hudi 的实时数据湖平台
对于更新数据,Hudi 通过索引快速定位数据所属的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index,其中 **Bucket Index 尚未合并到主分支**。 ## 字节跳动基于Hudi的实时数据湖平台 字节跳动基于 Hudi 的实时数据湖平台,通过秒级数据可见支持实时数仓。除了提供 Hudi 社区的所有功能外,还支持基于数据湖的元数据管理系统、行列级别的并发更新、Bucket Index 和 Append 模式等特性...
 特惠活动
特惠活动
 hbase写数据的并发数-优选内容
hbase写数据的并发数-优选内容
 hbase写数据的并发数-相关内容
hbase写数据的并发数-相关内容
字节跳动基于 Hudi 的实时数据湖平台
对于更新数据,Hudi 通过索引快速定位数据所属的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index,其中 **Bucket Index 尚未合并到主分支**。 ## 字节跳动基于Hudi的实时数据湖平台 字节跳动基于 Hudi 的实时数据湖平台,通过秒级数据可见支持实时数仓。除了提供 Hudi 社区的所有功能外,还支持基于数据湖的元数据管理系统、行列级别的并发更新、Bucket Index 和 Append 模式等特性...
干货|DataLeap数据资产实战:如何实现存储优化?
排除了HBase和Cassandra;==================================================**●**从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了BerkeleyDB;==============================================... 而且事务对于多个线程并发使用是安全的,但是JanusGraph的事务并不都支持ACID,是否支持会取决于底层存储组件, **对于某些存储组件来说,提供可序列化隔离机制或者多行原子写入代价会比较大。** JanusGraph中...
9年演进史:字节跳动 10EB 级大数据存储实战
(不支持随机写) - 顺序和随机读 - 超大数据规模 - 易扩展,容错率高## HDFS 在字节跳动的发展字节跳动已经应用 HDFS 非常长的时间了。经历了 9 年的发展,目前已直接支持了十多种数据平台,间接支持了上百种业务发展。从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,K...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.09
数据源配置支持开发生产环境隔离;独享计算资源组、独享调度资源组支持扩缩容; - **数据集成:** 实时分库分表、实时整库解决方案中新增 DataSail 内置缓存通道;新增 DataSail 数据源配置;TOS 数据源支持离线写入;新增ClickHouse、Hive、MySQL、Oracle、PostgreSQL、SQLServer、StarRocks、火山引擎HBase、 Doris 、VeDB MySQL、 TLS源端字段支持配置常量、变量、数据库函数等能力;支持已有表字段列匹配规则设置,设置全局高级...
DataLeap 数据资产实战:如何实现存储优化?
排除了 HBase 和 Cassandra;- 从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了 BerkeleyDB;- 同样因为人力成本,需要做极大量开发改造的方案暂时不考虑,排除了 Redis。 最终我们挑选了 MySQL ... 而且事务对于多个线程并发使用是安全的,但是 JanusGraph 的事务并不都支持 ACID,是否支持会取决于底层存储组件,对于某些存储组件来说,提供可序列化隔离机制或者多行原子写入代价会比较大。 JanusGraph 中的每...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储* Yarn,Flink 的计算框架平台数据* Spark,MapReduce 的计算相关数据存储**02****字节跳动特色的 HDFS 架构**在深入相关的技术细节之前,我... 任何对目录树的修改操作都会阻塞其他的读写操作,并发度较低;从上可以看出,在大数据量场景下,我们亟需一个新架构版本的 Name Node 来承载我们的海量元数据。除了 C++语言重写来规避 Java 带来的 GC 问题以外,我...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.04
支持按需扩充资源并发。 - 数据资产地图中 LAS 表支持同步显示数据安全中的敏感列信息。**说明文档链接(非微信域内链接)**:https://www.volcengine.com/docs/6260/65395/?utm_source=wechat_dp&utm_medium... **新增** **EMR** **软件** **栈** **3.1.1:** StarRocks 集群全量公开发布;新增 Phoenix 组件,版本为 5.1.3,作为 Hadoop 集群的可选组件,HBase 的必选组件;Impala、Kudu、ClickHouse、Doris、StarRocks 等...
如何快速构建企业级数据湖仓?
量的特点。LakeHouse 定义了一种叫我们称之为 **Table Format** 的存储标准。Table format 有四个典型的特征:- **支持** **ACID** **和历史快照**,保证数据并发访问安全,同时历史快照功能方便流、AI 等场景需求。- **满足多引擎访问**:能够对接 Spark 等 ETL 的场景,同时能够支持 Presto 和 channel 等交互式的场景,还要支持流 Flink 的访问能力。- **开放存储**:数据不局限于某种存储底层,支持包括从本地、HDFS 到云对...
大数据学习架构实践|社区征文
量大规模数据的存储问题。2)HBase列式存储在HDFS基础上,采用了列式存储的HBase数据库,解决了数据稀疏性的问题。并且由于HBase中数据结构的优化,使得快速实时查询在HBase上成为可能。# **4、大数据技术生态**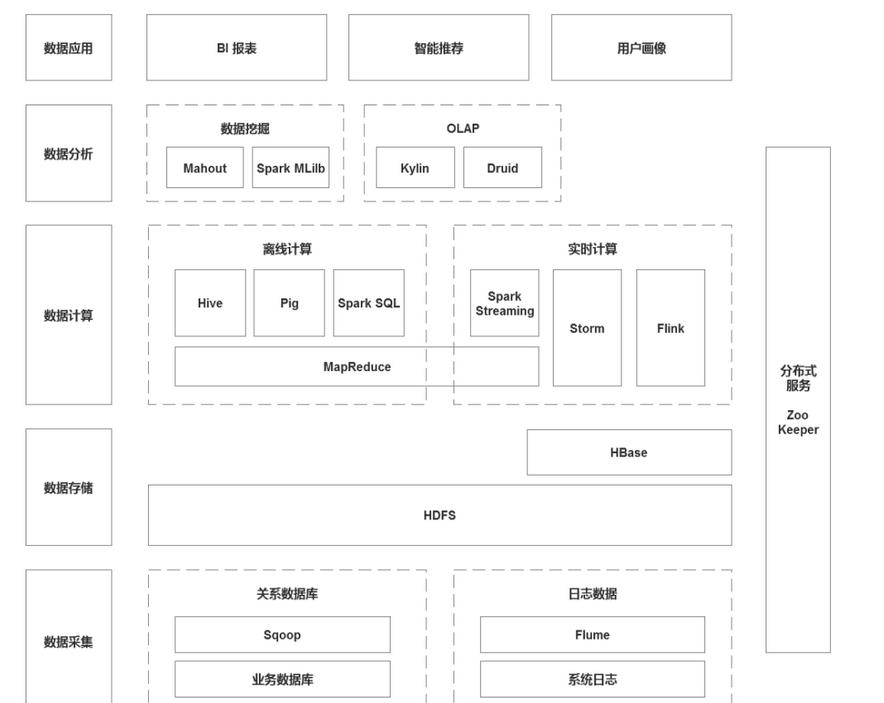## **4.1 数据采集**1)Sqoop:Sqoop是关系型数据库和HDFS之间的一个桥梁,写的时候...
