txt格式文件插入hbase
 社区干货
社区干货
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
其中hello.txt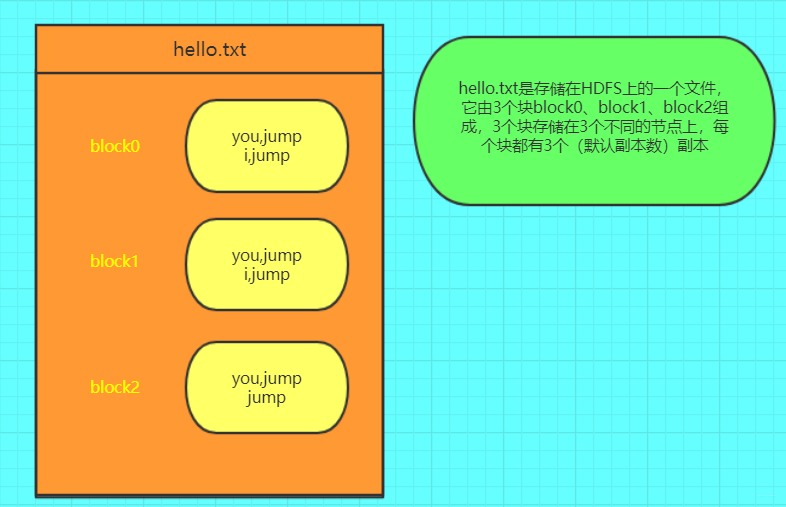## 三、RDD的创建方式### 3.1 通过读取文件生成的由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等```cppscala> val file =...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
当需要添加列或加特征时使用写时复制(Copy-On-Write)的方式会导致存储量翻倍,大幅增加成本负担的同时也会因为读写放大的本质导致不必要的计算资源开销。其次是通过**传统数据库方案**存放样本,这种方案更多适用于... 没写入的可以 Insert 插入;写入的可以采用 Update 更新操作。这部分我们参考了 Apache Hudi 的设计,除了支持 HBase 全局索引,还支持 HFile 文件索引、即直接使用 HBase 底层的数据格式作为索引并托管在 Iceberg 元...
干货 | 这样做,能快速构建企业级数据湖仓
这种数据格式有三个实现: **Delta Lake** 、 **Iceberg** 和 **Hudi** 。三种格式的出发点略有不同,但是场景需求里都包含了事务支持和流式支持。在具体实现中,三种格式也采用了相似做法,即在数据湖的存储之上定... 流式写入的效率不高,写入越频繁小文件问题就越严重;* 有一定维护成本:使用 Table Format 的用户需要自己维护,会给用户造成一定的负担;* 与现有生态之间存在gap:开源社区暂不支持和 Table format 之间的表同步,自...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
当需要添加列或加特征时使用写时复制(Copy-On-Write)的方式会导致存储量翻倍,大幅增加成本负担的同时也会因为读写放大的本质导致不必要的计算资源开销。其次是通过 **传统数据库方案** 存放样本,这种方案更多... 没写入的可以 Insert 插入;写入的可以采用 Update 更新操作。这部分我们参考了 Apache Hudi 的设计,除了支持 HBase 全局索引,还支持 HFile 文件索引、即直接使用 HBase 底层的数据格式作为索引并托管在 Iceberg 元...
 特惠活动
特惠活动
 txt格式文件插入hbase-优选内容
txt格式文件插入hbase-优选内容
 txt格式文件插入hbase-相关内容
txt格式文件插入hbase-相关内容
EMR-3.6.0 版本说明
HBase集群类型、Flink集群类型、自定义集群类型适配Kerberos,该特性属于白名单功能。 更改、增强和解决的问题【组件】Tez版本升级由0.10.1升级到0.10.2 【组件】Spark组件开箱参数优化,以及内核优化提高SQL执行性能 【组件】Hadoop组件添加Fuse模块 【组件】Proton组件由1.4.3升级到1.5.0版本 遗留的问题【组件】GPU不支持数据湖格式 组件版本 下面列出了 EMR 和此版本一起安装的组件。 组件 版本 描述 zookeeper_server 3....
EMR-3.6.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... Trino组件中修复access-control.properties文件内容。 【组件】修复扩容节点上Tez依赖包重复上传造成Hive作业失败问题。 组件版本 下面列出了 EMR 和此版本一起安装的组件。 组件 版本 描述 zookeeper_server 3....
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
其中hello.txt## 三、RDD的创建方式### 3.1 通过读取文件生成的由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等```cppscala> val file =...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
当需要添加列或加特征时使用写时复制(Copy-On-Write)的方式会导致存储量翻倍,大幅增加成本负担的同时也会因为读写放大的本质导致不必要的计算资源开销。其次是通过**传统数据库方案**存放样本,这种方案更多适用于... 没写入的可以 Insert 插入;写入的可以采用 Update 更新操作。这部分我们参考了 Apache Hudi 的设计,除了支持 HBase 全局索引,还支持 HFile 文件索引、即直接使用 HBase 底层的数据格式作为索引并托管在 Iceberg 元...
干货 | 这样做,能快速构建企业级数据湖仓
这种数据格式有三个实现: **Delta Lake** 、 **Iceberg** 和 **Hudi** 。三种格式的出发点略有不同,但是场景需求里都包含了事务支持和流式支持。在具体实现中,三种格式也采用了相似做法,即在数据湖的存储之上定... 流式写入的效率不高,写入越频繁小文件问题就越严重;* 有一定维护成本:使用 Table Format 的用户需要自己维护,会给用户造成一定的负担;* 与现有生态之间存在gap:开源社区暂不支持和 Table format 之间的表同步,自...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
当需要添加列或加特征时使用写时复制(Copy-On-Write)的方式会导致存储量翻倍,大幅增加成本负担的同时也会因为读写放大的本质导致不必要的计算资源开销。其次是通过 **传统数据库方案** 存放样本,这种方案更多... 没写入的可以 Insert 插入;写入的可以采用 Update 更新操作。这部分我们参考了 Apache Hudi 的设计,除了支持 HBase 全局索引,还支持 HFile 文件索引、即直接使用 HBase 底层的数据格式作为索引并托管在 Iceberg 元...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... Ingestion Server 负责数据的导入,Compaction Server 负责将数据定期 Merge。数据导入后,Ingestion Server 会写 WAL,同时数据进入内存 Buffer,Buffer 满了 Flush 成列存文件到 Cloud Store 上,并向 Meta Server 注...
EMR-3.10.0发布说明
环境信息版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 系统环境应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 ... 以及小文件写等场景。 【组件】HBase组件由2.3.7升级为2.5.2,并和Phoenix完成适配 【组件】YARN组件修复开源问题[YARN-11178],解决在Kerbeor环境下CPU繁忙问题。 遗留问题【组件】Spark组件不支持在GPU机型执行...
EMR-2.2.0 版本说明
HBase集群中集成Knox组件用于访问代理;并集成了YARN和MapReduce2; 【组件】Flink引擎支持avro,csv,debezium-json和avro-confluent等格式; 【组件】修复Presto写入TOS的潜在问题; 【组件】Hive适配CFS, 支持外部... 已知问题通过Sqoop从SQL Server导入数据时,存在编码异常问题,如果需要使用此功能可联系售后处理,预计会在后续版本进行优化; 使用Dolphin Scheduler调度Presto数据源项目时,由于keystore文件只位于master-1节点,...
