hbase为什么没有索引
 社区干货
社区干货
字节跳动数据湖索引演进
这是默认的索引方案,基于布隆过滤器实现,索引信息存储在 Parquet 文件的 Footer 当中。② Hbase Index。索引信息存储在 Hbase 数据库上。③ Bucket Index。字节提出的一种基于哈希的实现,不需要额外存储索引信息,可... **Q11:字节的 TimeLine 最长会维护多久呢?** A11:字节的 TimeLine 是维护在 MySQL 中,理论上是没有限制的。我们会根据用户的需求返回对应 TimeLine 长度,但是如果用户指定的 TimeLine 过长,查询效率也会降低。 *...
一文读懂火山引擎云数据库产品及选型
## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三大基础软... 宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不...
干货|字节跳动数据湖技术选型的思考
这张图是一个有索引和没有索引的对比。在CDC数据写入的过程中,为了让新增的Update数据作用在底表上,我们需要明确知道这条数据是否出现过、出现在哪里,从而把数据写到正确的地方。在合并的时候,我们就可以只合并... 没有什么规律可言,并且底表的数据量会比较大,新增的数据量通常相比底表会比较小。在这种场景下,我们可以 **选用哈希索引、State索引和Hbase索引来做到高效率的全局索引**。这两个例子说明了不同场景下,索...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
最近最新推出的 GPT-4 模型以及 Google 最近发布的第二代 PaLM 没有公布具体的模型细节。但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇... 通过全局索引可以知道一条写进记录是否已经写入,没写入的可以 Insert 插入;写入的可以采用 Update 更新操作。这部分我们参考了 Apache Hudi 的设计,除了支持 HBase 全局索引,还支持 HFile 文件索引、即直接使用 HB...
 特惠活动
特惠活动
 hbase为什么没有索引-优选内容
hbase为什么没有索引-优选内容
 hbase为什么没有索引-相关内容
hbase为什么没有索引-相关内容
干货|Hudi Bucket Index 在字节跳动的设计与实践
索引的类型索引是独立模块, 开源 Hudi 主要提供以下两种索引: | | 原理 | 特点 || **Bloom Filter Index** | 每个 Parquet 文件维护一个 Bloom Filter,在 File Group 映射阶段,把所有可能更新的分区的文件的 Bloom Filter 加载进来,用来判断 Record Key 是否存在 | 轻量级,默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
最近最新推出的 GPT-4 模型以及 Google 最近发布的第二代 PaLM 没有公布具体的模型细节。但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇... 通过全局索引可以知道一条写进记录是否已经写入,没写入的可以 Insert 插入;写入的可以采用 Update 更新操作。这部分我们参考了 Apache Hudi 的设计,除了支持 HBase 全局索引,还支持 HFile 文件索引、即直接使用 HB...
干货|Hudi Bucket Index 在字节跳动的设计与实践
索引是独立模块, 开源 Hudi 主要提供以下两种索引: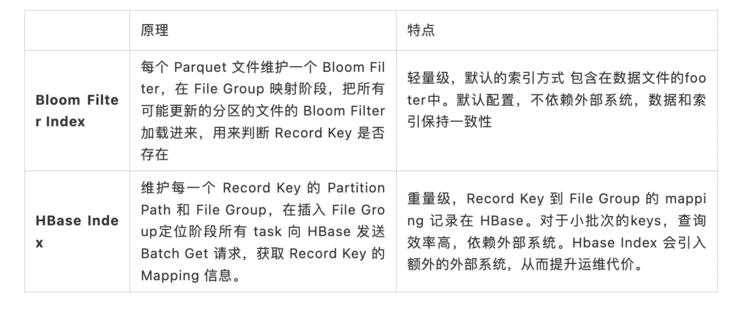在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动的设计与实践。# Bucket Index 产生背景索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index 类型,但在字节跳动大规模数据入湖、探索分...
Hudi Bucket Index 在字节跳动的设计与实践
默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBase 发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。 | 重量级,Record Key 到 File Group 的 mapping 记录在 HBase。对于小批次的keys,查...
Hudi Bucket Index 在字节跳动的设计与实践
索引是独立模块, 开源 Hudi 主要提供以下两种索引:| | | || --- | --- | --- || | 原理 | 特点 || **Bloom Filter Index** | 每个 Parquet 文件维护一个 Bloom Filter,在 File Group 映射阶段,把所有可能更新的分区的文件的 Bloom Filter 加载进来,用来判断 Record Key 是否存在 | 轻量级,默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个...
干货 | 这样做,能快速构建企业级数据湖仓
最后考虑的问题点:Table Format 是不是一个终极武器?我们认为答案是 **否定** 的。主要有几方面的原因:* 使用体验离预期有差距:由于 Table Format 设计上的原因,流式写入的效率不高,写入越频繁小文件问题就越严... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
字节跳动实时数据湖构建的探索和实践
最为看重的就是Hudi的索引系统。**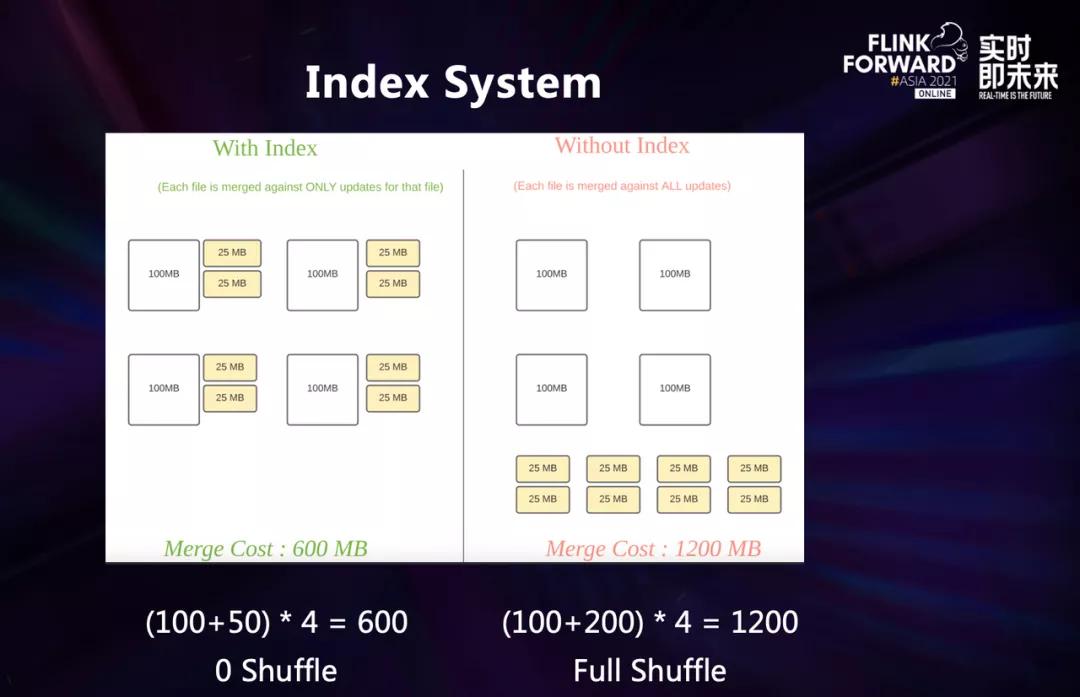这张图是一个有索引和没有索引的对比。在C... 没有什么规律可言,并且底表的数据量会比较大,新增的数据量通常相比底表会比较小。在这种场景下,我们可以**选用哈希索引、State索引和Hbase索引来做到高效率的全局索引**。这两个例子说明了不同场景下,索引的选...
字节跳动数据湖技术选型的思考
这张图是一个有索引和没有索引的对比。在 CDC 数据写入的过程中,为了让新增的 Update 数据作用在底表上,我们需要明确知道这条数据是否出现过、出现在哪里,从而把数据写到正确的地方。在合并的时候,我们就可以只... 没有什么规律可言,并且底表的数据量会比较大,新增的数据量通常相比底表会比较小。在这种场景下,我们可以 **选用哈希索引、State 索引和 HBase 索引来做到高效率的全局索引** 。这两个例子说明了不同场景下,...
字节跳动基于 Hudi 的机器学习应用场景
在没有使用数据湖之前,用户做离线特征调研之前需要复制样本,修改并另存一份。其中消耗了巨大的计算和存储资源,伴随样本量的增大,这样的方案将消耗数个 EB 的存储,使得迭代变得不可能。我们基于 Hudi 实现了 ColumnFamily 的能力。这个方案受到了经典 BigTable 存储 Apache HBase 的启发,将 IO pattern 不同的数据使用不同的文件进行存储,以减少不必要的读写放大。原理是将同一个 FileGroup 的不同列数据存储在不同的文件中,在读...
