hbase的底层架构原理
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
系统总体架构设计如下所示: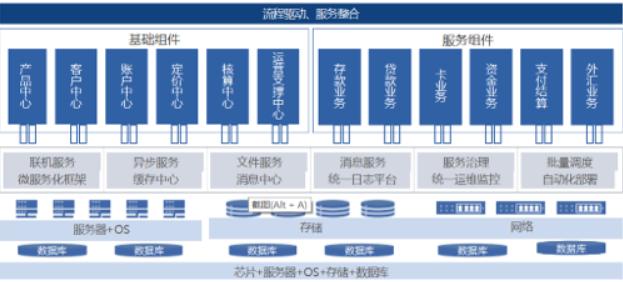- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理...
9年演进史:字节跳动 10EB 级大数据存储实战
# 背景## **HDFS** **简介**HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:- 和本地文件系统一样的目录... HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H...
Hive SQL 底层执行过程 | 社区征文
> 本文结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理。第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程,第三节剖析 SQL 编译成 MapReduce 的具体实现原理。### 一、HiveHive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hive直接访问存储在 HDFS 中或者 HBase ...
我的大数据学习总结 |社区征文
此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学习分布式原理和架构也很重要。这个学习顺序参考了我之前的工作和学习经历情况后订定。需要注意,大数据领域的技术很多很广,如Flink也值得研究。本人给出的仅作为一个参考案例,学习者还需结合实际情况选择合适的学习路径。 特惠活动
特惠活动
 hbase的底层架构原理-优选内容
hbase的底层架构原理-优选内容
 hbase的底层架构原理-相关内容
hbase的底层架构原理-相关内容
我的大数据学习总结 |社区征文
此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学习分布式原理和架构也很重要。这个学习顺序参考了我之前的工作和学习经历情况后订定。需要注意,大数据领域的技术很多很广,如Flink也值得研究。本人给出的仅作为一个参考案例,学习者还需结合实际情况选择合适的学习路径。* 顺序和随机读* 超大数据规模* 易扩展,容错率高**HDF... HBase,日志服务,Kafka 数据存储* Yarn,Flink 的计算框架平台数据* Spark,MapReduce 的计算相关数据存储**02****字节跳动特色的 HDFS 架构**在深入相关的技术细节之前,我...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
概念和原理又千差万别,对于元数据的采集、组织、理解、信任等,都带来了很大挑战。因此,做好一个Data Catalog产品,本身是一个门槛低、上限高的工作,需要有一个持续打磨提升的过程。## 旧版本痛点字节跳动Data Catalog产品早期为能较快解决Hive的元数据收集与检索工作,是基于LinkedIn Wherehows进行二次改造 。Wherehows架构相对简单,采用Backend + ETL的模式。初期版本,主要利用Wherehows的存储设计和ETL框架,自研实现前后端的...
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
Atlas的底层使用JanusGraph做图引擎。JanusGraph 是基于Gremlin 图查询语义实现的计算引擎,其底层存储支持HBase/Cassadra/BerkeleyDB等KCV结构的存储,同时,使用ElasticSearch作为索引查询支持。当火山引擎 DataLeap 研发人员将越来越多的元数据接入系统,图存储中的点和边分别到达百万和千万量级,读写性能都遇到了比较大的问题。我们做了部分源码的修改,这边介绍其中比较重要的两个,更多细节请参照后续的文章。### 读优化:**开...
招聘|字节跳动云原生计算团队,期待你的加入
资源调度等底层支撑。![]()# 你将获得**个人成长**:深度参与超大单体作业和超大集群规模应用场景下的性能优化与改造,获得高速的个人成长**业务经验**:深入参与大数据生态 ToB 业务,为互联网、金融、政企等... 2. 协调并驱动研发、测试、运营等多个团队共同完成产品业务目标,推进产品市场推广,包括内外部培训,市场活动,数据分析等。**职位要求**1. 熟悉开源大数据引擎,具有云计算厂商产品设计经验,包括产品架构、产品...
干货 | 字节跳动构建Data Catalog数据目录系统的实践(下)
数据消费者找数和理解数的业务场景,并服务于数据开发和数据治理的产品体系。本文介绍了字节跳动Data Catalog系统的构建和迭代过程,将分为上、下篇发布。[上篇围绕Data Catalog调研思路及技术架构展开。](http://mp... 以我们定义过的目录结构和先后顺序加载。这也为后面的标准化奠定了基础。**02 -****数据接入标准化**为了最终达成降低接入和维护成本的目标,统一了类型系统之后,第二步就是接入流程的标准化。我...
招聘|字节跳动云原生计算,期待你的加入
资源调度等底层支撑。 **02** **你将获得** **个人成长**:深度参与超大单体作业和超大集群规模应用场景下的性能优化与改造,获得高速的个人成长 **业务经验... 对数据结构及算法有较强的功底;具备并行计算或者分布式计算原理,熟悉高并发、高稳定性、可线性扩展、海量数据的系统特点和技术方案;2. 对开源计算框架 Flink/Calcite/Storm/Kafka/Yarn/Hive/Spark/Kubernetes 有一...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
上图是字节典型的广告后端架构,数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直... 并采用了基于 Coroutine 的异步调度执行框架。以上图为例,展示了一个 Query 的执行流程。Coordinator 会把优化过的 Query 生成 Fragments 并下发给一组 Data Servers 来执行。比如上图的 Query 生成了两组 Fragmen...
