hbase2.6打快照变慢
 社区干货
社区干货
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
(https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/4aff02a315244154bce21def052cf60b~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049291&x-signature=uXlxuuHd%2BLgE9sQuZxgwef... 扫描海量样本时会变得非常缓慢。另外,当需要添加列或加特征时使用写时复制(Copy-On-Write)的方式会导致存储量翻倍,大幅增加成本负担的同时也会因为读写放大的本质导致不必要的计算资源开销。其次是通过**传统数据...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.09
火山引擎HBase、 Doris 、VeDB MySQL、 TLS源端字段支持配置常量、变量、数据库函数等能力;支持已有表字段列匹配规则设置,设置全局高级参数能力; - **数据开发:** 升级IDE3.0编辑器助力研发提效;临时查询支持“通用 -MySQL 数据库”;Serverless Flink SQL 支持快照和重启、Session集群调试能力;Flink SQL支持 Jar 包形式;基于ByteHouse CE 任务及临时查询; - **数据安全:** 支持 EMR StarRocks 库表权限申请、授权管...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
(https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/cd04d78210204b6da74b2d660d590883~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049259&x-signature=hCobNIqJv7mCSJ%2F1Q3EvkhObcHI%3D)首先,传统样本存储是将样本 **直接存放在 HDFS、对象存储或者 Hive 上的方案** 。这种方案在处理海量样本时会遇到性能瓶颈。由于采用了单点 List 操作,扫描海量样本时会变得非常缓慢。另外,当需要添加列...
20000字详解大厂实时数仓建设 | 社区征文
渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要... 1.2 方案_抽象一下这个场景就是下面这种 SQL: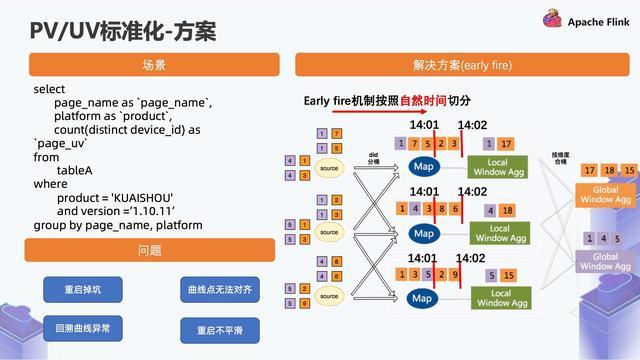简单来说,就是从一张表做筛选条件,然后按照维度层面做聚合,接着产生一些 Count 或者 Sum 操作。...
 特惠活动
特惠活动
 hbase2.6打快照变慢-优选内容
hbase2.6打快照变慢-优选内容
 hbase2.6打快照变慢-相关内容
hbase2.6打快照变慢-相关内容
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
(https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/cd04d78210204b6da74b2d660d590883~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049259&x-signature=hCobNIqJv7mCSJ%2F1Q3EvkhObcHI%3D)首先,传统样本存储是将样本 **直接存放在 HDFS、对象存储或者 Hive 上的方案** 。这种方案在处理海量样本时会遇到性能瓶颈。由于采用了单点 List 操作,扫描海量样本时会变得非常缓慢。另外,当需要添加列...
20000字详解大厂实时数仓建设 | 社区征文
渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要... 1.2 方案_抽象一下这个场景就是下面这种 SQL:简单来说,就是从一张表做筛选条件,然后按照维度层面做聚合,接着产生一些 Count 或者 Sum 操作。...
字节跳动基于 Hudi 的机器学习应用场景
(https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/d2d659c38ddd4879983468e6d4c82582~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049291&x-signature=qYcgGpyL6TJ9NfRdDPx64ApoErg%3D)在流式架构中,特征由在线预估服务在 serving 时 dump 对应的快照并发送到消息队列中。标签则来自实时行为采集服务,通过日志上报等方法采集得到。在线样本生成服务消费两个数据流,通过关联得到完整的样本,并...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 因此被限流的路径或用户会感觉到访问 HDFS 变慢,但是并不会失败。## **Dance NN(Dance Name Node)**### **解决的问题**如前所述,在数据量上到 10EB 级别的场景后,原有的 Java 版本的 Name Node 存在了非常多...
基于火山引擎 EMR 构建企业级数据湖仓
同时历史快照功能方便流、AI 等场景需求。 - 满足多引擎访问:能够对接 Spark 等 ETL 的场景,同时能够支持 Presto 和 channel 等交互式的场景,还要支持流 Flink 的访问能力。 - 开放存储:数据不局限于某种存储底... (https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/2645a6a61a2a435084a734eea0ccf356~tplv-k3u1fbpfcp-5.jpeg?)可以看到,绝大部分特性这三者都是支持的。只不过在一些小的方面,三者之间是有一点区别的。这种...
干货 | 这样做,能快速构建企业级数据湖仓
=&rk3s=8031ce6d&x-expires=1716049251&x-signature=KDqYkLP1iZCgGr2Mh7sZV%2Bk29lE%3D)> > > 本文整理自火山引擎开发者社区技术大讲堂第四期演讲,主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点... 同时历史快照功能方便流、AI 等场景需求。* **满足多引擎访问** :能够对接 Spark 等 ETL 的场景,同时能够支持 Presto 和 channel 等交互式的场景,还要支持流 Flink 的访问能力。* **开放存储** :数据不局限于某种...
字节跳动基于 Iceberg 的海量特征存储实践
=&rk3s=8031ce6d&x-expires=1716049262&x-signature=zOSQ7PFjG1fc78n8qsGa882MtW4%3D)特征存储的整体流程1. 业务在线进行特征模块抽取;2. 抽取后的特征以行的格式存储在 HDFS,考虑到成本,此时不存储原始特征... =&rk3s=8031ce6d&x-expires=1716049262&x-signature=NAe27T5QgPHZ26rZChhRWk5E%2FGQ%3D)整体上 Iceberg 是一个分层的结构,snapshot 层存储了当前表的所有快照;manifest list 层存储了每个快照包含的 manifest 云...
关于大数据计算框架 Flink 内存管理的原理与实现总结 | 社区征文
Flink 基于 Chandy-Lamport 算法实现了分布式一致性的快照,从而提供了 exactly-once 的语义。(Flink 基于两阶段提交协议,实现了端到端的 exactly-once 语义保证。内置支持了 Kafka 的端到端保证,并提供了 TwoPhase... Hbase,为了获取C一样的性能以及避免OOM的发生。### Flink内存管理因为Java对象及jvm内存管理存在的问题,flink针对这些问题基于jvm进行了优化, Flink内存管理主要会涉及内存管理、定制的序列化工具、缓存友好的...
字节跳动基于 Iceberg 的海量特征存储实践
这个过程通常需要**2周**甚至更长的时间。并且,如果发现特征的计算逻辑写错或想要更改计算逻辑,则需重复上述过程。在线特征抽取导致当前字节特征调研的效率非常低。基于当前的架构,离线特征调研的成本又非常高。... (https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/c574ed66fd7740899ddfc191f651ad3d~tplv-k3u1fbpfcp-5.jpeg?)整体上 Iceberg 是一个分层的结构,snapshot 层存储了当前表的所有快照;manifest list 层存储了...
