达到最大值后返回零并加上剩余的值。
 社区干货
社区干货
一文理解 HyperLogLog(HLL) 算法 | 社区征文
因为包含 4 个不同的取值。- 序列 `[1, 2, 3, 1, 2]` 的基数为 3,虽然包含 5 个元素,但其中的 1, 2 分别重复了一次。最直观的基数统计方法是利用 HashSet:将序列中的所有值依次添加到 HashSet 中,最后统计 Hash... 最高得分是 5 分,请问玩了多少局?>> 答2:大概 32 局如果把硬币的正反两面分别记作 0、1 的话,那么 HyperLogLog 的计数原理就呼之欲出了:对于每一条待统计的数据(例如 user_id),计算其 hash 值并写成二进制形...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
=&rk3s=8031ce6d&x-expires=1715530855&x-signature=p37KBZHkDpucyJnzKE0NprYaPic%3D)由于需要聚合的数据量比较大,线上对于这样的 Query Latency 要求比较高,所以我们采用了 MV 来加速这个 Query 的执行,具体... Sample 数据的统计预估和支持数据的统计值只相差 1%,Sample Query 执行的 Overhead 不超过执行时长的 2%。另外我们的 Query 在执行完毕后,会收集一些轻量的统计信息和结果一起返回给 Coordinator 帮助优化器更新统...
2022技术盘点之平台云原生架构演进之道|社区征文
可以很容易的添加一个 Kubernetes Node 到集群中,从而实现横向扩展。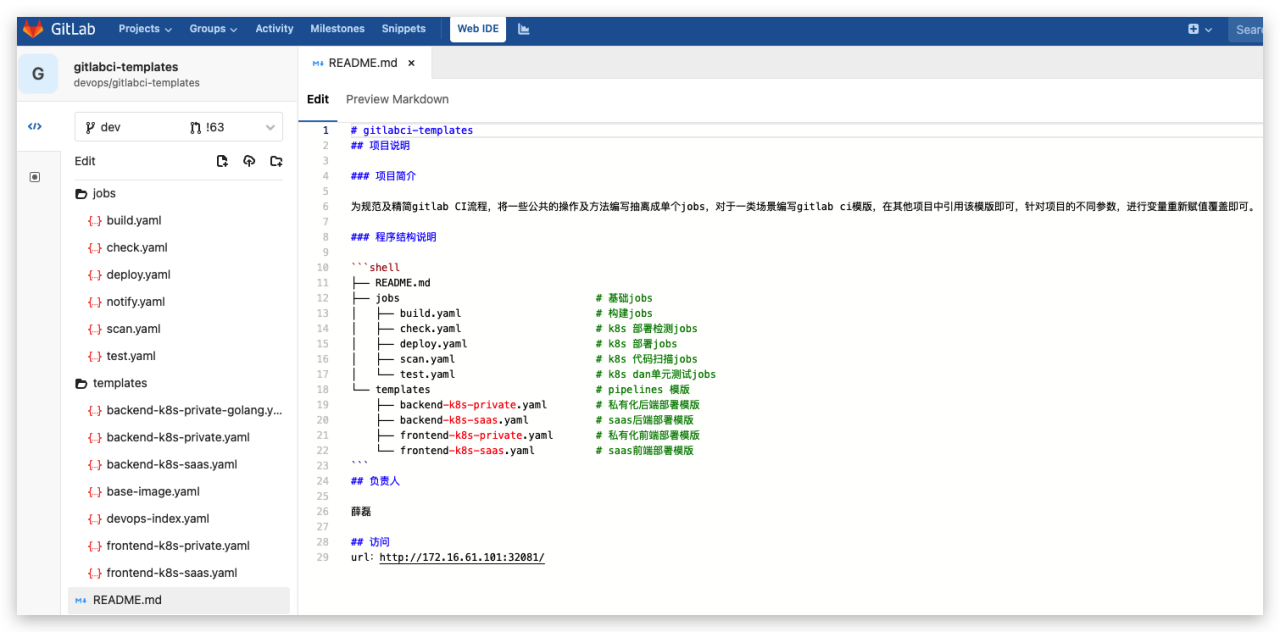利用Gitlab CI 共享模块库,可最大程度... 启动后k8s集群针对调用该service,后端会返回具体的pod列表。服务发现:在同一名称空间,直接使用service信息发起调用;- 方案特点: - 优势:负载均衡算法在服务端实现(service 的原生负载均衡算法),后期可使用服...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
=&rk3s=8031ce6d&x-expires=1715530876&x-signature=gRj8cIIAuQvrDZCRGGXam90bzd0%3D)由于需要聚合的数据量比较大,线上对于这样的 Query Latency 要求比较高,所以我们采用了 MV 来加速这个 Query 的执行,具体做法... Sample 数据的统计预估和支持数据的统计值只相差 1%,Sample Query 执行的 Overhead 不超过执行时长的 2%。 另外我们的 Query 在执行完毕后,会收集一些轻量的统计信息和结果一起返回给 Coordinator 帮助优化器更新统...
 特惠活动
特惠活动
 达到最大值后返回零并加上剩余的值。-优选内容
达到最大值后返回零并加上剩余的值。-优选内容
 达到最大值后返回零并加上剩余的值。-相关内容
达到最大值后返回零并加上剩余的值。-相关内容
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
=&rk3s=8031ce6d&x-expires=1715530855&x-signature=p37KBZHkDpucyJnzKE0NprYaPic%3D)由于需要聚合的数据量比较大,线上对于这样的 Query Latency 要求比较高,所以我们采用了 MV 来加速这个 Query 的执行,具体... Sample 数据的统计预估和支持数据的统计值只相差 1%,Sample Query 执行的 Overhead 不超过执行时长的 2%。另外我们的 Query 在执行完毕后,会收集一些轻量的统计信息和结果一起返回给 Coordinator 帮助优化器更新统...
数据结构
则不会返回该字段。 AccountType String 否 Normal 账号类型,取值范围: Super:高权限账号。 Normal:普通账号。 AccountStatus String 否 Available 账号状态:取值为: Unavailable:不可用。 Available:可用... 默认值为 1。 说明 不支持在批量创建实例时分别为实例指定名称。在批量创建实例时: 如在 InstanceName 参数指定了实例名称,则会在指定的实例名称后加序号为批量创建的实例命名。 如未在 InstanceName 参数指定实例...
2022技术盘点之平台云原生架构演进之道|社区征文
可以很容易的添加一个 Kubernetes Node 到集群中,从而实现横向扩展。利用Gitlab CI 共享模块库,可最大程度... 启动后k8s集群针对调用该service,后端会返回具体的pod列表。服务发现:在同一名称空间,直接使用service信息发起调用;- 方案特点: - 优势:负载均衡算法在服务端实现(service 的原生负载均衡算法),后期可使用服...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
=&rk3s=8031ce6d&x-expires=1715530876&x-signature=gRj8cIIAuQvrDZCRGGXam90bzd0%3D)由于需要聚合的数据量比较大,线上对于这样的 Query Latency 要求比较高,所以我们采用了 MV 来加速这个 Query 的执行,具体做法... Sample 数据的统计预估和支持数据的统计值只相差 1%,Sample Query 执行的 Overhead 不超过执行时长的 2%。 另外我们的 Query 在执行完毕后,会收集一些轻量的统计信息和结果一起返回给 Coordinator 帮助优化器更新统...
数据结构
则不返回此参数。 RegionId String cn-beijing 实例所在的地域 ID。 StorageSpace Integer 200 实例总存储空间。单位为 GiB。 StorageType String ESSD_PL0 Kafka 实例数据存储的云盘类型。即 ESSD_Fl... {"mode": "http","tag-wzx": "11"} 已绑定的标签。 UsablePartitionNumber Integer 20 当前实例剩余可用分区数。 UsableGroupNumber Integer 100 当前实例剩余可用消费组数。 UsedGroupNumber Integer ...
数据结构
MessageId String FDBD0FF1CE00003A0000000000000EFE425C18B4AAC23681EE4F0002 消息 ID。 MessageKey String FDBD0 消息 Key。为了避免特殊字符的影响,消息 Key 将会以 Base64 的编码的方式返回,需要通过... true:已开启 false:已关闭 AvailableQueueNumber Integer 3944 剩余可创建的分区数量。 ChargeDetail ChargeDetailObject 实例的计费方式等计费信息。详细说明请参考【ChargeDetailObject】。 ComputeS...
CnchMergeTree 表引擎
每一个逻辑分区可以存在零到多个数据片段(DataPart)。如果查询条件可以裁剪分区,通常可以加速查询。如果没有指定分区键,全部数据都在一个逻辑分区里。2. 数据片段数据片段里的数据按排序键排序。每个数据片段还会存... 表中分区表达式计算出的取值范围不能太大(推荐不超过一万),太多分区会占用比较大的内存以及带来比较多的 IO 和计算开销。合理的设计分区键可以极大减少查询时需要扫描的数据量,一般考虑将查询中最常用的条件同时取...
最新动态(2024年前)
0.2版本 迭代说明: 创建指标dsl算子增加属性类型 分流和调度:数据加载逻辑优化 2022年09月08日 V2.0.2版本 迭代说明: 支持查看行为细查 实验到期提醒支持webhook 定时任务优化 2022年08月25日 V2.0.0版本 迭代说明: 新增OpenAPI: 基于指标模板创建指标 anyevent可选事件公共属性 报告页逻辑优化,包含报告概览核心指标显著性去除60天最大限制和指标报告的实验版本排序优化 优化创建指标弹窗速度 2022年08月11日 V1.9.8版本 迭...
逻辑函数
逻辑函数可以接受任何数字类型的参数,并返回UInt8类型的0或1。当向函数传递零时,函数将判定为«false»,否则,任何其他非零的值都将被判定为«true»。 和,AND 运算符或,OR 运算符非,NOT 运算符异或,XOR 运算符
