hbase多线程并发入库
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 甚至是多棵子树下的所有 INode。### **DanceNN** **启动优化**由于我们的 DanceNN 底层元数据实现了本地目录树管理结构,因此我们 DanceNN 的启动优化都是围绕着这样的设计来做的。#### **多线程扫描和填充 B...
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续... l **应用层面**:提升线程并发数,充分利用CPU的多核特点,降低热点资源竞争、减少或避免锁、微服务化、分布式架构。# 三、解决方案系统优化的基本过程: 特惠活动
特惠活动
 hbase多线程并发入库-优选内容
hbase多线程并发入库-优选内容
 hbase多线程并发入库-相关内容
hbase多线程并发入库-相关内容
干货|DataLeap数据资产实战:如何实现存储优化?
排除了HBase和Cassandra;==================================================**●**从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了BerkeleyDB;==============================================... 而且事务对于多个线程并发使用是安全的,但是JanusGraph的事务并不都支持ACID,是否支持会取决于底层存储组件, **对于某些存储组件来说,提供可序列化隔离机制或者多行原子写入代价会比较大。** JanusGraph中...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... 并且后台有个线程定期的与 Meta Server 中的数据版本进行对比,并移除掉过期的 Cache Entry。 - **Plan/Stats/** **Result** **Cache** **:** Coordinator中会把Query plan cache住,对于一些Query Fragment的...
DataLeap 数据资产实战:如何实现存储优化?
排除了 HBase 和 Cassandra;- 从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了 BerkeleyDB;- 同样因为人力成本,需要做极大量开发改造的方案暂时不考虑,排除了 Redis。 最终我们挑选了 MySQL ... 而且事务对于多个线程并发使用是安全的,但是 JanusGraph 的事务并不都支持 ACID,是否支持会取决于底层存储组件,对于某些存储组件来说,提供可序列化隔离机制或者多行原子写入代价会比较大。 JanusGraph 中的每...
干货 | ELT in ByteHouse 实践与展望
聚合完成后将结果写入 **HBase** 或MySQL中再去取数据,将数据取出后作展示。 Flink 还会去直接暴露中间状态的接口,即queryable state,让用户更好的使用状态数据。但是最后还会与批计算的结果完成对数,如... 有效利用多核多机并发能力;数据快速导入;内存使用有效(内存管理);CPU 优化(向量化、codegen)4. 生态 & 可观测性:可对接多种工具;任务状态感知;任务进度感知;失败日志查询;有一定可视化能力**ByteHouse**针对...
字节跳动基于数据湖技术的近实时场景实践
导入到实时的 Redis 或 HBase 存储,然后复用到实时计算中。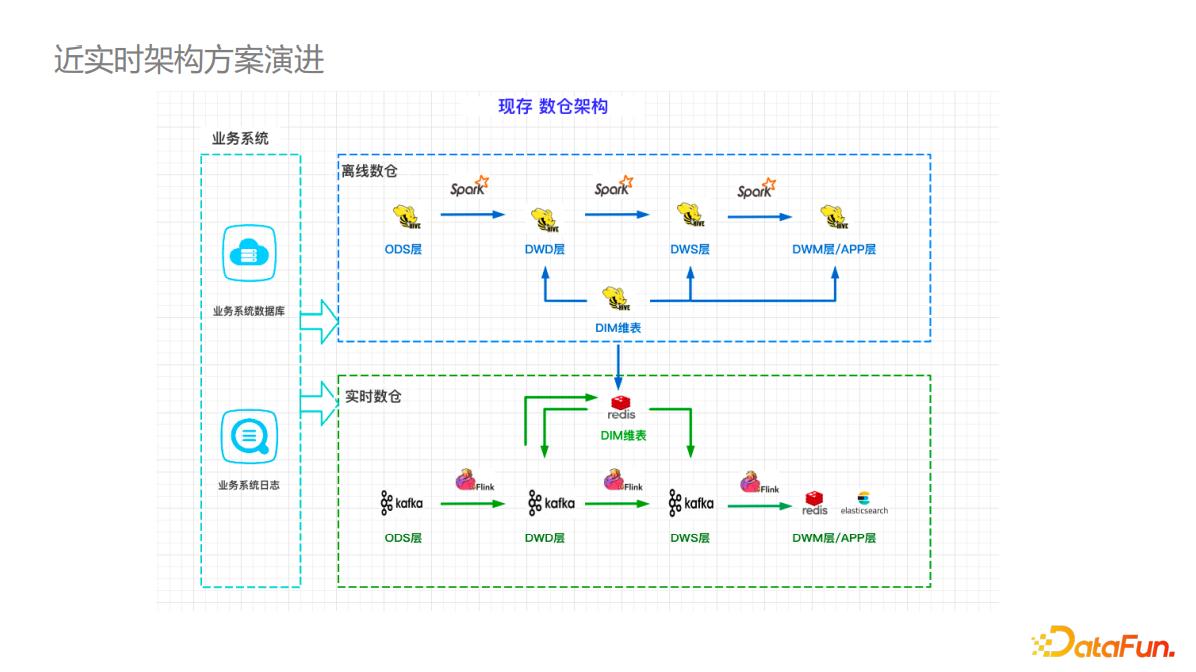 下图是基于Hudi... 将多数据源实时增量入库,避免过多的 join 或者是汇总计算,同时又把离线的表去做复用。整体直接面向查询引擎,由用户去决定在查询分析时候的 schema ,也就是转化为 schema on read 的模式。 8. ## **运维型场...
ELT in ByteHouse 实践与展望
将结果写入HBase或MySQL中再去取数据,将数据取出后作展示。Flink还会去直接暴露中间状态的接口,即queryable state,让用户更好的使用状态数据。但是最后还会与批计算的结果完成对数,如果不一致,需要进行回查操作,整... **效率&性能**:有效利用多核多机并发能力;数据快速导入;内存使用有效(内存管理);CPU优化(向量化、codegen)1. **生态&** **可观测性**:可对接多种工具;任务状态感知;任务进度感知;失败日志查询;有一定可视化能力...
招聘|字节跳动云原生计算,期待你的加入
熟悉高并发、高稳定性、可线性扩展、海量数据的系统特点和技术方案;2. 对开源计算框架 Flink/Calcite/Storm/Kafka/Yarn/Hive/Spark/Kubernetes 有一项或多项深入研究和相关经验者优先;对机器学习,图计算,OLAP 有... 熟悉网络编程和多线程编程,参与研发,完成产品落地;3. 熟悉大数据体系生态,除存储系统外,熟悉至少两种相关生态组件(如Yarn、Spark、Flink、Kafka、HBase)的原理、架构和应用; **工作地点:**上海...
招聘|字节跳动云原生计算团队,期待你的加入
熟悉高并发、高稳定性、可线性扩展、海量数据的系统特点和技术方案; 2. 对开源计算框架 Flink/Calcite/Storm/Kafka/Yarn/Hive/Spark/Kubernetes 有一项或多项深入研究和相关经验者优先;对机器学习,图计算,OLAP 有... 2. 熟悉 Java/C/C++/Go 等其中一种语言,熟悉网络编程和多线程编程,参与研发,完成产品落地; 3. 熟悉大数据体系生态,除存储系统外,熟悉至少两种相关生态组件(如Yarn、Spark、Flink、Kafka、HBase)的原理、架构和应...
火山引擎ByteHouse:只需2个方法,增强 ClickHouse 数据导入能力
其数据分布在多个 Shard 上,Kafka 引擎可以在多个 Shard 上去做并发的写入,而在同一个 Shard 内可以启动多线程做并发写入,并具备本地盘的极致的性能读写。* **社区版 Kafka 不足**:在内外部业务的场景中,会经常遇... 实时写入便实时入库。通过 low-level 的这种消费来保证数据的有序分片,再通过增强的消费语义 exactly once 保证数据的精准一次传输。最后我们通过自研的 Unique 引擎来实现实时的这种 upsert 的语义,让数据实时写入...
