hbase查询数据到文件
 社区干货
社区干货
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计...
字节跳动基于 Hudi 的机器学习应用场景
我们需要面临以下挑战:基于 HDFS 这种不可变的文件存储,如何实现低成本低读写放大的数据修改。在没有使用数据湖之前,用户做离线特征调研之前需要复制样本,修改并另存一份。其中消耗了巨大的计算和存储资源,伴随样本量的增大,这样的方案将消耗数个 EB 的存储,使得迭代变得不可能。我们基于 Hudi 实现了 ColumnFamily 的能力。这个方案受到了经典 BigTable 存储 Apache HBase 的启发,将 IO pattern 不同的数据使用不同的文件进行...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计...
9年演进史:字节跳动 10EB 级大数据存储实战
# 背景## **HDFS** **简介**HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:- 和本地文件系统一样的目录... 从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,Kafka 数据...
 特惠活动
特惠活动
 hbase查询数据到文件-优选内容
hbase查询数据到文件-优选内容
 hbase查询数据到文件-相关内容
hbase查询数据到文件-相关内容
功能发布记录(2023年)
HBase 数据源 配置 Doris 数据源 配置 VeDB 数据源 配置 TLS 数据源 实时分库分表解决方案 实时整库同步解决方案 离线整库同步解决方案 独享资源组管理 2 数据开发 基于 ByteHouse CE 引擎,新增 ByteHouse CE SQL 任务 临时查询支持 ByteHouse CE SQL 临时查询任务 ByteHouse CE SQL 临时查询 3 控制台 创建项目新增支持绑定 ByteHouse CE 引擎实例 创建项目 管理引擎 4 指标平台 新增维度管理功能 建模增加支持Doris...
Hbase Phoenix
1. 概述 支持接入HBase Phoenix去创建数据集。在连接数据之前,请收集以下信息: 数据库所在服务器的 IP 地址和端口号; 数据库的用户名和密码。 2. 快速入门 2.1 从数据连接新建(1)进入火山引擎,点击进入到某个具体项目下,点击数据准备,在下拉列表找到数据连接,点击数据连接。(2)在页面中选择 HBase Phoenix 。(3)填写所需的基本信息,并进行测试连接,连接成功后点击保存。(4)确认数据连接的基本信息无误后即完成数据连接。(5)可使...
HBase Phoenix数据连接
1. 产品概述 支持Hbase Phoenix数据连接。 说明 在连接数据之前,请收集以下信息: 数据库所在服务器的 IP 地址和端口号; 数据库的用户名和密码。 2. 使用限制 用户需具备 项目编辑 或 权限-按内容管理-模块-数据连接-新建连接 权限,才能新建数据连接。 3. 操作步骤 1.点击 数据融合 > 数据连接 。2.在数据连接目录左上角,点击 新建数据连接 按钮,选择 Hbase Phoenix 。 填写所需的基本信息,并进行 测试连接 。 连接成功后点击...
Java 程序通过 Thrift2 地址访问 HBase 实例
如需通过公网地址访问 HBase 实例,需确保运行 Java 工具的设备 IP 地址已加入 HBase 实例的白名单中。白名单设置方法,请参见编辑白名单。 已在 ECS 实例或本地设备上安装 Java 环境,建议使用 JDK 8 版本。更多详情,请参见 Java Downloads。 操作步骤获取 HBase 实例的 Thrift2 连接地址。连接地址查看方法,请参见查看连接地址。 说明 表格数据库 HBase 版默认未开通 Thrift2 地址,您需要先申请 Thrift2 连接地址,申请方法,请...
数据结构
本文汇总表格数据库 HBase 版的 API 接口中使用的数据结构定义详情。 AllowListObject白名单信息。被 DescribeAllowLists 接口引用。 名称 类型 示例值 描述 AllowListDesc String test 白名单的备注。 AllowListI... HdfsSsd:SSD 文件存储。 StorageCapacity Integer 500 实例总存储容量,单位:GiB。 UsedStorage Float 0 实例已使用的存储容量,单位:GiB。 VpcId String vpc-rs5811nceqyov0x58x4**** 实例所属的私有网络 ID。 Su...
9年演进史:字节跳动 10EB 级大数据存储实战
# 背景## **HDFS** **简介**HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:- 和本地文件系统一样的目录... 从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,Kafka 数据...
揭秘|字节跳动基于Hudi的实时数据湖平台
记录本次写入修改的文件。相较于传统数仓,Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group中。底层存储由多个 file group 构成,有其特定的 file ID。File group 内的文件分为... 会定期合并 log file 到 base file 中。对于更新数据,Hudi 通过索引快速定位数据所属的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index,其中 **Bucket Index 尚未合并到主...
揭秘|字节跳动基于Hudi的实时数据湖平台
Hudi 是一个流式数据湖平台,提供 ACID 功能,支持实时消费增量数据、离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行查询。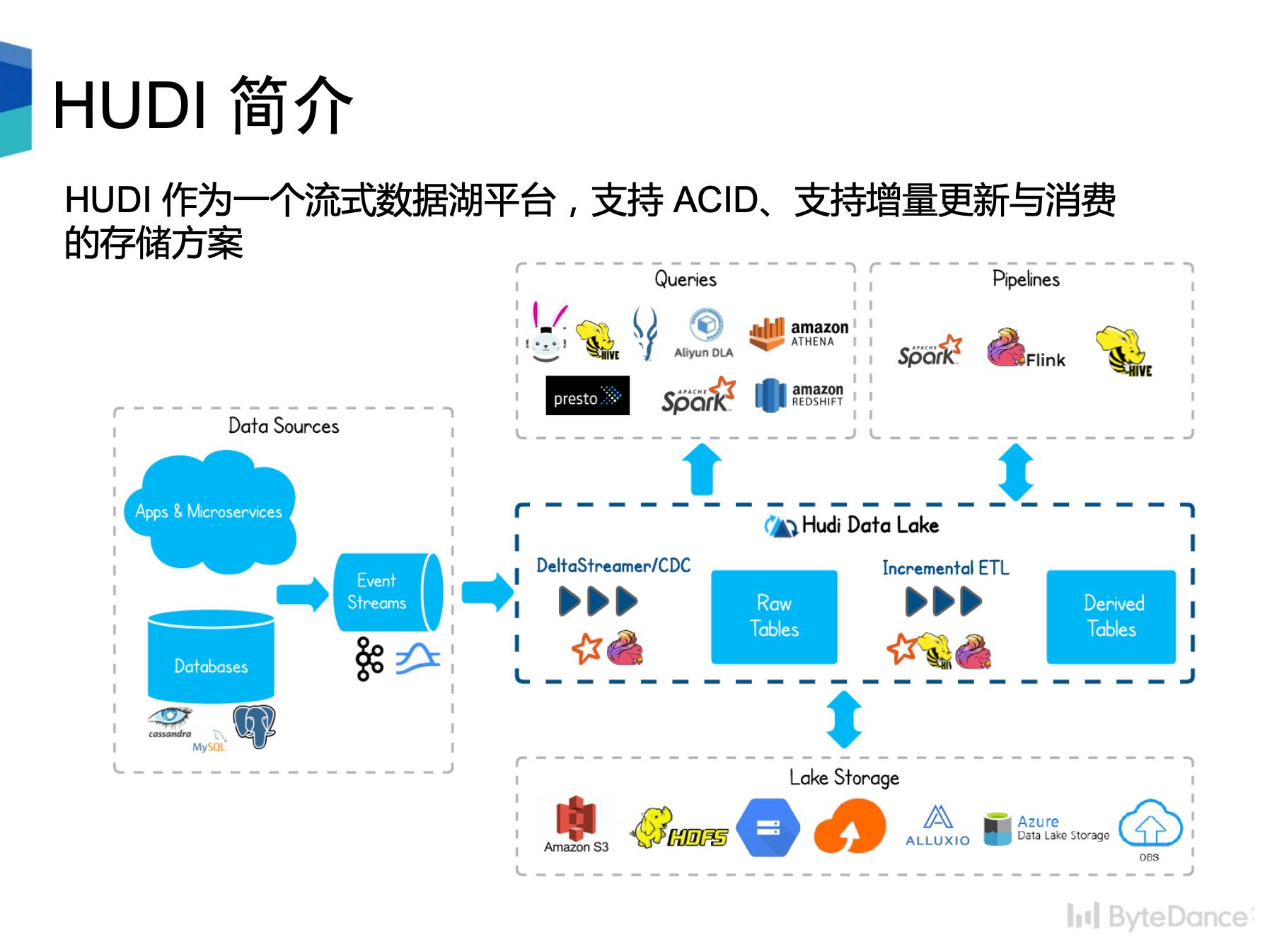Hudi 表由 timeline 和 file group两大项构成。Timeline 由一个个 commit 构成,一次写入过程对应时间线中的一个 commit,记录本次写入修改的文件。相较...
字节跳动基于 Hudi 的实时数据湖平台
记录本次写入修改的文件。相较于传统数仓,Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group 中。底层存储由多个 file group 构成,有其特定的 file ID。File group 内的文件分为 b... 会定期合并 log file 到 base file 中。对于更新数据,Hudi 通过索引快速定位数据所属的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index,其中 **Bucket Index 尚未合并到主分支...
