基于hbase的系统ppt
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
系统总体架构设计如下所示: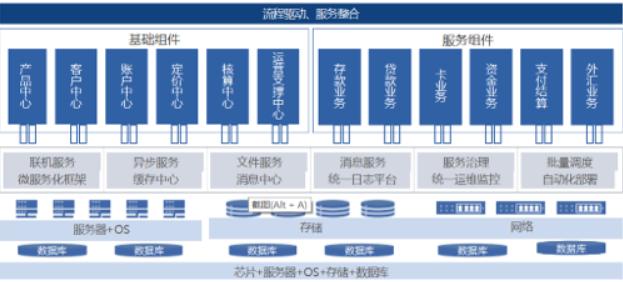- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 是整个系统的大脑。一旦故障,整个集群都会陷入不可用状态。因此 Name Node 有一套基于 ZKFC 的主从热备的高可用方案。Name Node 还面临着扩展性的问题,单机承载能力始终受限。于是 HDFS 引入了联邦(Federation)机...
字节跳动 NoSQL 的探索与实践
列存:以 HBase 为代表; - 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提... 需要基于网页的链接关系计算每个页面的 page rank,从而对页面进行排序。页面的链接关系其实就是一张图,基于网页链接关系的 page rank 计算,就是在这张图上运行一个图算法,即图计算。小规模的图可以通过单机来进行...
干货 | 这样做,能快速构建企业级数据湖仓
火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。> > > >  特惠活动
特惠活动
 基于hbase的系统ppt-优选内容
基于hbase的系统ppt-优选内容
 基于hbase的系统ppt-相关内容
基于hbase的系统ppt-相关内容
EMR-2.3.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.5.13 2.5.13 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.10.0 - Knox 1.5.0 - Presto 0.280 - Trino 412 - Spark 2.4.8 - Sqoop 1.4.7 - T...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 是整个系统的大脑。一旦故障,整个集群都会陷入不可用状态。因此 Name Node 有一套基于 ZKFC 的主从热备的高可用方案。Name Node 还面临着扩展性的问题,单机承载能力始终受限。于是 HDFS 引入了联邦(Federation)机...
EMR-2.1.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
EMR-2.2.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
字节跳动 NoSQL 的探索与实践
列存:以 HBase 为代表; - 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提... 需要基于网页的链接关系计算每个页面的 page rank,从而对页面进行排序。页面的链接关系其实就是一张图,基于网页链接关系的 page rank 计算,就是在这张图上运行一个图算法,即图计算。小规模的图可以通过单机来进行...
EMR-2.4.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 HDFS 2.10.2 2.10.2 YARN 2.10.2 2.10.2 MapReduce2 2.10... Spark Thrift Server 2.4.8 基于HiveServer2提供的Thrift服务。 spark_client 2.4.8 Spark命令行客户端。 livy_server 0.8.0 提供REST接口来与Spark交互的服务。 sqoop 1.4.7 提供数据库与HDFS导入导出功能。 ice...
干货 | 这样做,能快速构建企业级数据湖仓
火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。> > > >  Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.5.13 2.5.13 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.10.0 - Knox 1.5.0 - Presto 0.280 - Trino 412 - Spark 2.4.8 - Sqoop 1.4.7 - T...
