基于hbase的系统的设计
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
系统总体架构设计如下所示: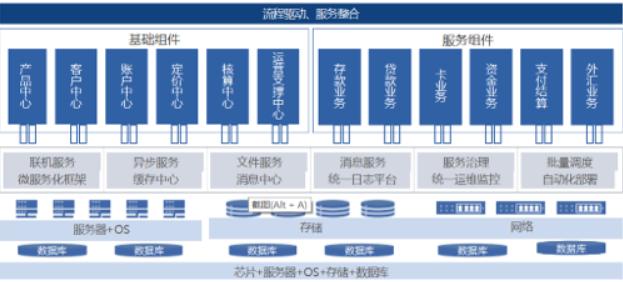- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 是整个系统的大脑。一旦故障,整个集群都会陷入不可用状态。因此 Name Node 有一套基于 ZKFC 的主从热备的高可用方案。Name Node 还面临着扩展性的问题,单机承载能力始终受限。于是 HDFS 引入了联邦(Federation)机...
一文读懂火山引擎云数据库产品及选型
针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三大基础软件,分别是操作系统、数据库系统和中间件。我们每天日常生活中的方方面面,背后都离不开这些基础软件的支撑,其中数据库系统是业务数据的...
火山引擎上云迁移指南(一):上云迁移背景与流程
> **王志雷**,火山引擎存储&数据库解决方案架构师,专注于存储&数据库产品的解决方案规划、设计和拓展工作。 > **贾伟力**,火山引擎存储&数据库解决方案架构师,专注于存储&数据库产品的解决方案规划、设计和拓展... 系统正式进入运行和后期运维阶段,通过性能调优、高可用加固、安全加固、提升服务质量等实现系统的优化。 特惠活动
特惠活动
 基于hbase的系统的设计-优选内容
基于hbase的系统的设计-优选内容
 基于hbase的系统的设计-相关内容
基于hbase的系统的设计-相关内容
功能发布记录(2023年)
本文为您介绍 2023 年大数据研发治理套件 DataLeap 产品功能和对应的文档动态。 2023/12/21序号 功能 功能描述 使用文档 1 数据集成 ByteHouse CDW 离线写入时,支持写入动态分区; HBase 数据源支持火山引擎 ... 配置 ByteHouse CDW 数据源 配置 HBase 数据源 配置 Doris 数据源 配置 VeDB 数据源 配置 TLS 数据源 实时分库分表解决方案 实时整库同步解决方案 离线整库同步解决方案 独享资源组管理 2 数据开发 基于 Byte...
基于国产化环境的金融级业务系统性能优化实践|社区征文
系统总体架构设计如下所示:- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理...
标签概述
标签可用于标识云资源,帮助您从不同维度(如用途、类型、所有者、环境等)对具有相同特征的表格数据库 HBase 版实例进行标记和分类,便于筛选和管理。 功能概述随着云上资源数量的不断增长,管理难度也随之增加。火山引... volc: 为系统预留的标签键,添加标签时,标签键的开头不能设置为任何大小写形式的 volc:。 标签键的长度需为 1~128 个字符。 标签值 支持语言字符(如中文、英文字母等)、数字、空格和英文符号 _.:/=+-@。 标签值的...
EMR-2.4.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 HDFS 2.10.2 2.10.2 YARN 2.10.2 2.10.2 MapReduce2 2.10... Spark Thrift Server 2.4.8 基于HiveServer2提供的Thrift服务。 spark_client 2.4.8 Spark命令行客户端。 livy_server 0.8.0 提供REST接口来与Spark交互的服务。 sqoop 1.4.7 提供数据库与HDFS导入导出功能。 ice...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 是整个系统的大脑。一旦故障,整个集群都会陷入不可用状态。因此 Name Node 有一套基于 ZKFC 的主从热备的高可用方案。Name Node 还面临着扩展性的问题,单机承载能力始终受限。于是 HDFS 引入了联邦(Federation)机...
一文读懂火山引擎云数据库产品及选型
针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三大基础软件,分别是操作系统、数据库系统和中间件。我们每天日常生活中的方方面面,背后都离不开这些基础软件的支撑,其中数据库系统是业务数据的...
火山引擎上云迁移指南(一):上云迁移背景与流程
> **王志雷**,火山引擎存储&数据库解决方案架构师,专注于存储&数据库产品的解决方案规划、设计和拓展工作。 > **贾伟力**,火山引擎存储&数据库解决方案架构师,专注于存储&数据库产品的解决方案规划、设计和拓展... 系统正式进入运行和后期运维阶段,通过性能调优、高可用加固、安全加固、提升服务质量等实现系统的优化。,系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应对...
干货 | 看 SparkSQL 如何支撑企业级数仓
数仓在构建的时候通常需要 ETL 处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种 ETL 处理成为 DWD 层,再基于 DWD 层设计上层的数据模型层,形成 DM,中间会有 DWB/DWS 作为部分中间过程数据。从技... MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似 SQL 语法的分析入口,同时在编程态的支撑也不够友好,只有 Map 和 Reduce ...
