基于hbase的设计代码
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
系统总体架构设计如下所示: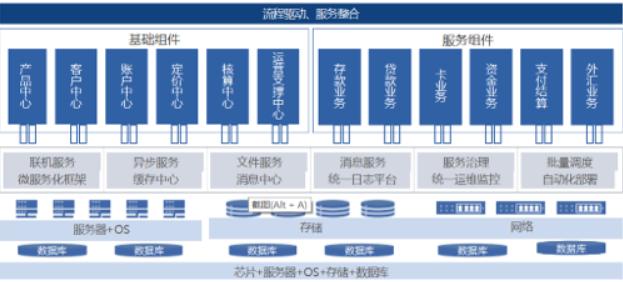- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理...
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群# 关键技术构建一个好的Data Catalog系统,需要考虑的核心产品设计和技术设计有很多。篇幅所限,本文只概要介绍技术设计中... 火山引擎 DataLeap 研发人员借用了Atlas的设计与实现。Atlas的底层使用JanusGraph做图引擎。JanusGraph 是基于Gremlin 图查询语义实现的计算引擎,其底层存储支持HBase/Cassadra/BerkeleyDB等KCV结构的存储,同时,使...
分布式数据库TiDB的设计和架构
HBase。但此类数据库的局限在于无法处理交易类数据及复杂业务逻辑的特性,限制其在非互联网领域的发展。**2013年以后**2013年以来,有个新的概念为分布式关系型数据库(NewSQL),它是兼具NoSQL扩展性又不丧失传统关... 它是基于 Google Spanner/F1 论文,未开源它的代码及技术细节,是基础软件最前沿的领域之一,技术门槛最高。NewSQL 代表产品有Spanner/F1(未开源)、CockroachDB(开源)和TiDB(开源)。 特惠活动
特惠活动
 基于hbase的设计代码-优选内容
基于hbase的设计代码-优选内容
 基于hbase的设计代码-相关内容
基于hbase的设计代码-相关内容
HBase
HBase 连接器提供了对分布式 HBase 数据库表的读写数据能力,支持做数据源表、结果表和维表。 使用限制Flink 目前提供了 HBase-1.4 和 HBase-2.2 两种连接器,请根据实际情况选择: 在 Flink 1.11-volcano 引擎版本中仅支持使用 HBase-1.4 连接器。 在 Flink 1.16-volcano 引擎版本中支持使用 HBase-1.4 和 HBase-2.2 两种连接器。 注意事项在公网环境中连接火山 HBase 时,您需要添加以下两个参数: 'properties.zookeeper.znode.me...
什么是表格数据库 HBase 版
火山引擎表格数据库 HBase 版是基于 Apache HBase 提供的全托管 NoSQL 服务,兼容标准 HBase 访问协议,具备低成本存储、高扩展吞吐等优势。 产品架构 如上图所示,表格数据库 HBase 版主要由 Master、RegionServer、ZooKeeper、HDFS 四部分组成: Master:Master 负责管理和协调 RegionServer,以及管理表的增删改查操作。每个 HBase 实例默认只能创建 2 个 Master 节点(主备)。 RegionServer:RegionServer 负责存放和管理 HRegion,以...
基于国产化环境的金融级业务系统性能优化实践|社区征文
系统总体架构设计如下所示:- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理...
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群# 关键技术构建一个好的Data Catalog系统,需要考虑的核心产品设计和技术设计有很多。篇幅所限,本文只概要介绍技术设计中... 火山引擎 DataLeap 研发人员借用了Atlas的设计与实现。Atlas的底层使用JanusGraph做图引擎。JanusGraph 是基于Gremlin 图查询语义实现的计算引擎,其底层存储支持HBase/Cassadra/BerkeleyDB等KCV结构的存储,同时,使...
分布式数据库TiDB的设计和架构
HBase。但此类数据库的局限在于无法处理交易类数据及复杂业务逻辑的特性,限制其在非互联网领域的发展。**2013年以后**2013年以来,有个新的概念为分布式关系型数据库(NewSQL),它是兼具NoSQL扩展性又不丧失传统关... 它是基于 Google Spanner/F1 论文,未开源它的代码及技术细节,是基础软件最前沿的领域之一,技术门槛最高。NewSQL 代表产品有Spanner/F1(未开源)、CockroachDB(开源)和TiDB(开源)。